Official statement
Other statements from this video 21 ▾
- □ Should you update the same page or create a new URL every day for frequently refreshed content?
- □ Should you stop using the manual submission tool in Google Search Console?
- □ Do H2 tags in your footer actually hurt your SEO rankings?
- □ Do HTML5 <header> and <footer> tags really boost your SEO rankings?
- □ Should you really rely on the schema.org validator to optimize your structured data?
- □ Does improving page speed really boost your rankings as fast as everyone claims?
- □ Does Google really crawl all your sitemaps at the same pace?
- □ Does Google really keep crawling a sitemap after you remove it from Search Console?
- □ Can you safely use bidirectional canonicals between two site versions without any risk?
- □ Can structured data really replace traditional internal linking strategy?
- □ Why is one x-default enough for your entire multi-domain hreflang configuration?
- □ Should you really avoid product structured data on category pages?
- □ Do you really need to pick one primary language per page if you're targeting multiple markets?
- □ Why is Google completely ignoring your desktop version once mobile-first indexing kicks in?
- □ Can commodity content really survive in Google search results?
- □ Should you isolate your FAQs on separate pages to rank better?
- □ Is Google really cutting back on FAQ rich snippets in search results, and what does that mean for your SEO strategy?
- □ Is Google really ignoring 95% of your submitted URLs—and what does that say about your content?
- □ Can you host your XML sitemap on a different domain than your main website?
- □ Does the shift from 'Bad' to 'Medium' on Core Web Vitals really transform your Google rankings?
- □ Does server speed really impact the crawl budget of large websites?
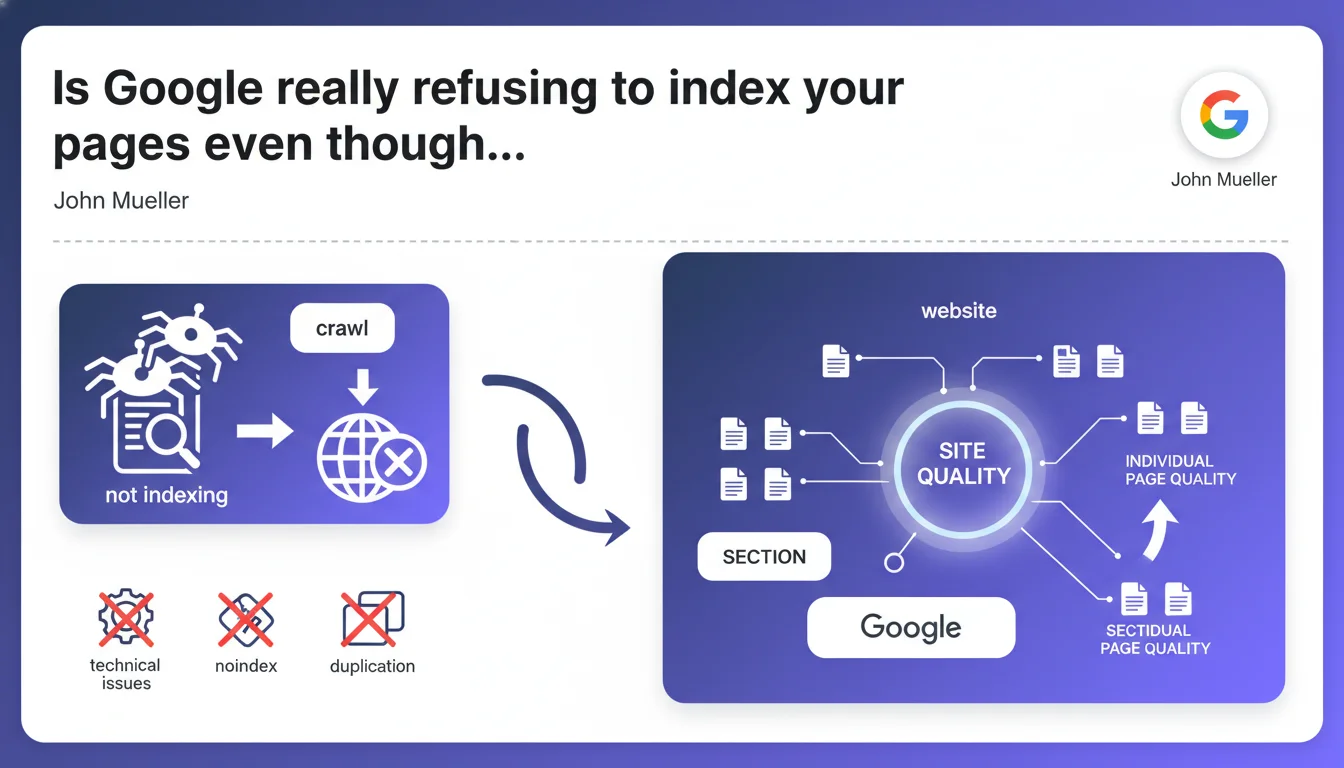
When Google crawls a page multiple times without indexing it — even though no technical issues, noindex directives, or duplicate content are detected — the problem stems from the perceived quality of the entire site or the relevant section, not just that individual page. Over-optimizing that single page is pointless: it's the broader context that's blocking its indexation.
What you need to understand
What does "crawled but not indexed" really mean in practice?
This situation appears in Search Console when Googlebot visits a page multiple times but decides not to add it to its index. The page is technically accessible, has no noindex directive, no 404 or 500 errors, but Google judges it insufficiently relevant to appear in its search results.
The typical reflex is to analyze that page in detail — refine the content, adjust internal linking, optimize tags. Mueller says this is a waste of time: the problem extends far beyond the scope of that single URL.
Why does Google evaluate quality at the site level rather than page by page?
Google's algorithm operates through aggregated signals. If a site or section produces predominantly weak content — thin pages, partial duplications, low user engagement — each new page in that area inherits an implicit penalty at the outset.
This mechanism allows Google to save crawl budget by avoiding systematically indexing content that's likely to be of little use. Overall quality becomes a preliminary filter for individual page indexation.
What signals does Google use to evaluate this overall quality?
Google never specifies the exhaustive list, but we know several factors come into play: the proportion of unique vs. duplicate content, engagement metrics (bounce rate, time on page), the crawl depth required to reach pages, the profile of internal and external links.
This vagueness is typical: Google mentions "perceived quality" without detailing thresholds or weightings. [To verify] on your own sites by cross-referencing Search Console data with Analytics.
- A technically correct page can remain unindexed if the site as a whole lacks credibility
- Sectional context matters: a quality blog on an e-commerce site can offset weak product sheets, and vice versa
- Google evaluates thematic consistency and the depth of topic treatment across the entire domain
- Orphaned pages or those more than 4-5 clicks away from the homepage are statistically less likely to be indexed
SEO Expert opinion
Is this statement consistent with field observations?
Yes, and it's even one of the rare instances where Google confirms what SEO professionals have been observing for years. Sites displaying massive "crawled not indexed" in Search Console often share common patterns: explosion of unparameterized faceted pages, auto-generated content with no added value, deep directory structures with recycled content.
However, Mueller remains vague about the evaluation scope. Is it the entire domain, a subdomain, or a section defined by the directory structure? On large sites, this distinction is critical — and Google never clarifies it. [To verify] by isolating your tests by directory.
In what cases does this rule not apply?
Watch out for exceptions. Perfectly legitimate pages can remain "crawled not indexed" for reasons that have nothing to do with overall quality: internal cannibalization with a competing URL already indexed, content judged too similar to a better-ranking external page, a page that's too recent (Google sometimes waits weeks before indexing).
E-commerce sites with thousands of product variants (colors, sizes) are particularly affected. Google often refuses to index all combinations even if the overall site is solid. This isn't a quality problem but a decision about crawl budget allocation.
Should you take Google at its word when it talks about "quality"?
The term "quality" is a convenient catch-all for Google. Behind this word lie technical criteria (loading speed, Core Web Vitals), semantic criteria (depth of treatment, uniqueness), behavioral criteria (engagement, click-through rate in SERPs), and structural criteria (internal linking, page depth).
Let's be honest: Google has no interest in detailing its criteria. Saying "improve overall quality" is valid advice in 80% of cases, but it doesn't help anyone prioritize concrete actions. It's up to you to cross-reference the data to identify where the real bottleneck is.
Practical impact and recommendations
What should you concretely do when facing "crawled not indexed"?
Stop fine-tuning individual pages. Start with a section or content-type audit: identify whether the problem affects a specific type of content (blog, product sheets, landing pages), a particular directory, or the entire domain.
Next, analyze the crawl depth of these pages (how many clicks from the homepage?), their rate of partial duplication (via Screaming Frog or Sitebulb), their performance in terms of engagement (Analytics: bounce rate, time on page). If these pages are predominantly weak on these criteria, Google treats them as noise.
What mistakes should you absolutely avoid?
Don't multiply manual submissions via "Request indexing" in Search Console. This solves nothing if the problem is structural. Google will crawl the page again and reject it once more due to insufficient signals.
Also avoid diluting your internal linking by artificially boosting these pages from the homepage. If they don't belong in the index, it's probably because they lack strategic value. Better to consolidate, merge, or delete them.
- Segment your "not indexed" crawl by page type and directory
- Calculate the indexed pages / crawled pages ratio by section — a ratio below 30% signals an overall quality problem
- Audit the content of affected sections: average length, internal duplication rate, semantic density
- Check page depth: URLs more than 3-4 clicks from the homepage are statistically disadvantaged
- Analyze Core Web Vitals and loading time for these sections — poor technical UX impacts quality perception
- Compare with competitors well-indexed on the same topic: what content depth, what information structure?
- Consider consolidation: merging several weak pages into one comprehensive resource is often more effective than multiplying them
❓ Frequently Asked Questions
Une page crawlée plusieurs fois mais non indexée est-elle définitivement perdue ?
Faut-il bloquer ces pages en robots.txt pour économiser du crawl budget ?
Le problème vient-il forcément du contenu textuel ?
Peut-on forcer l'indexation avec des backlinks externes vers ces pages ?
Comment savoir si le problème touche tout le site ou juste une section ?
🎥 From the same video 21
Other SEO insights extracted from this same Google Search Central video · published on 05/03/2022
🎥 Watch the full video on YouTube →
💬 Comments (0)
Be the first to comment.