Official statement
Other statements from this video 14 ▾
- □ Peut-on vraiment utiliser un sous-répertoire unique pour gérer plusieurs marchés internationaux avec hreflang ?
- □ Pourquoi Google n'indexe-t-il pas toutes les URLs de votre site ?
- □ Peut-on utiliser des avis tiers pour les résultats enrichis produits ?
- □ Comment savoir si Google vous pénalise vraiment ?
- □ Faut-il abandonner les URI de thésaurus NALT pour optimiser son référencement ?
- □ Pourquoi les erreurs robots.txt unreachable sont-elles toujours de votre faute ?
- □ Faut-il vraiment rediriger vos 404 vers la homepage ?
- □ Faut-il vraiment maintenir les redirections lors d'une migration de domaine ?
- □ Faut-il s'inquiéter de millions d'URLs non indexées sur son site ?
- □ Google traite-t-il vraiment les redirections 308 et 301 de la même manière ?
- □ La qualité du contenu influence-t-elle vraiment la vitesse d'indexation par Google ?
- □ WiFi vs Wi-Fi : Google fait-il vraiment la différence pour le référencement ?
- □ Un nombre d'avis à zéro pénalise-t-il le référencement d'une page produit ?
- □ Pourquoi certains sites migrés apparaissent-ils dans Google en quelques minutes et d'autres mettent des mois ?
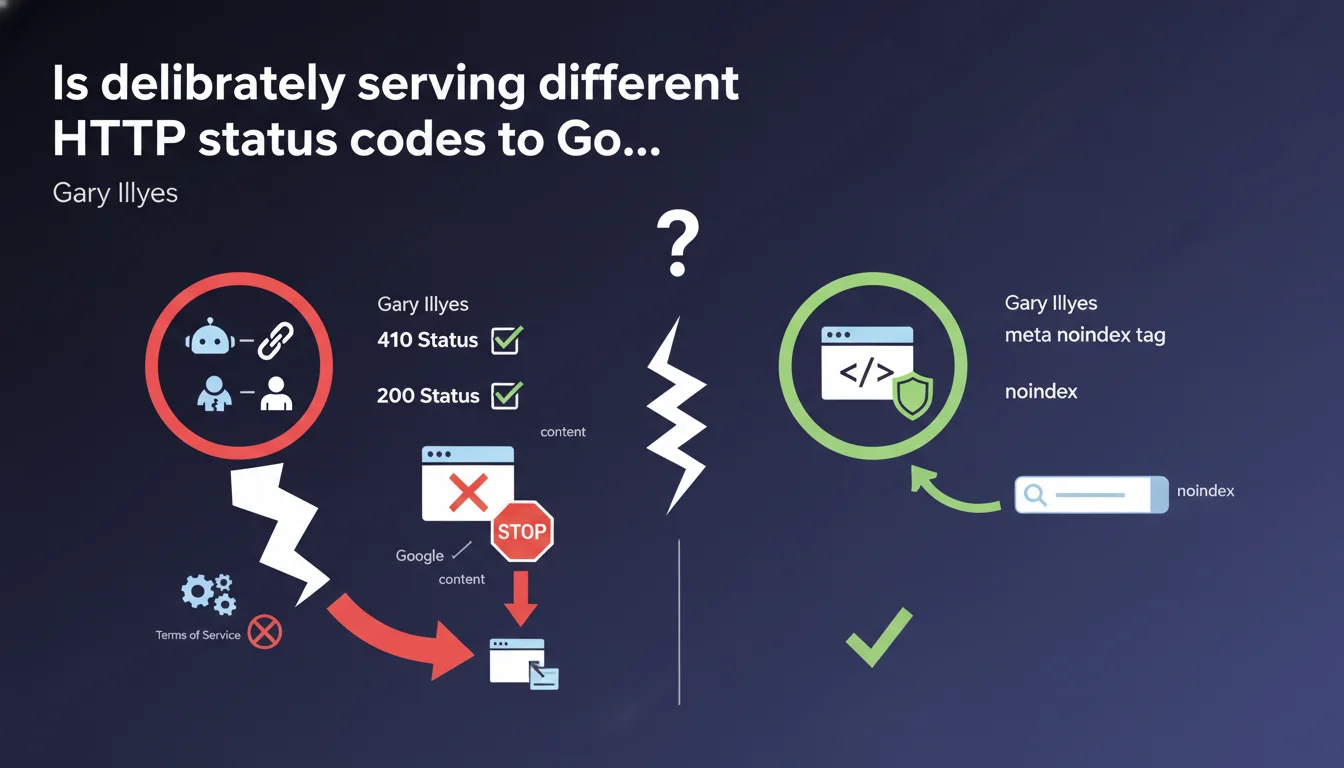
Google explicitly qualifies as cloaking the practice of serving a 410 status code to Googlebot while serving 200 to users. The official recommendation for removing content: use the meta noindex tag rather than playing with differentiated HTTP codes. The risk? Complete site deindexation if Terms of Service violations are detected.
What you need to understand
Gary Illyes is targeting here a practice that is probably more widespread than one might think: deliberately differentiating the HTTP status code served to Googlebot from the one sent to human visitors.
The example cited — 410 for the bot, 200 for the user — is a form of technical cloaking. And Google says it outright: it's a very bad idea.
Why does this practice still exist?
Some sites seek to finely control what Google indexes without impacting user experience. Sending a 410 (Gone) to Googlebot while maintaining a 200 for visitors theoretically allows you to deindex a page without removing it from the site.
The problem? That's exactly the definition of cloaking: showing one thing to the search engine, another to users. And Google's Guidelines have been clear on this point for years.
What are the concrete consequences mentioned?
Illyes mentions that "something will eventually go wrong" — deliberately vague but threatening phrasing. He references "Terms of Service," suggesting manual or algorithmic action detecting the anomaly.
The result: your site can disappear completely from search results. Not just the affected page — the entire site. This is a serious penalty, likely manual.
What alternative does Google propose?
The recommended solution is simple: use the meta noindex tag. According to Illyes, it's "easier and safer."
Concretely, this means serving a 200 code to everyone, but adding <meta name="robots" content="noindex"> in the page's <head>. Googlebot crawls, sees the directive, and removes the page from the index without impacting the user.
- HTTP status code cloaking is explicitly forbidden — even for deindexing
- The meta noindex tag is the official method for removing content without affecting users
- The risks are real: complete site deindexation if detected
- Google detects these practices — likely through both automated signals and manual review
SEO Expert opinion
Is this statement consistent with field observations?
Yes, completely. Cases of massive deindexation following cloaking — even unintentional — are well documented. What's interesting here is that Google explicitly classifies HTTP status code differentiation as cloaking.
Some practitioners believed that only differentiated HTML content was affected. This firm statement closes the door: HTTP status codes are an integral part of the server response, and differentiating them between bot and user is punishable.
Is the meta noindex really "safer" in all cases?
Almost always, but not systematically. The meta noindex requires that Googlebot can crawl the page to read the directive. If you block the page via robots.txt, the tag will never be seen.
Additionally, a meta noindex removes the page from the index but doesn't necessarily suppress associated signals (links, authority). A 410 or 404 is more radical — which can be desirable in certain contexts (duplicate content, permanently obsolete pages).
[To verify]: Google claims that "something will eventually go wrong," but doesn't specify whether this detection is automated, manual, or based on user signals. The mechanism remains unclear.
Are there legitimate exceptions?
Yes — and that's where it gets tricky. Sites serving geolocation-based content or paywalls can legitimately return different codes depending on user context (location, subscription).
But the critical nuance is: differentiating by user-agent (Googlebot vs. human) remains cloaking. Differentiating by geolocation or authentication is acceptable if applied uniformly — bots included.
Practical impact and recommendations
What should you do immediately if you're differentiating HTTP codes?
First step: audit your server logs. Compare the HTTP codes returned to Googlebot vs. users for the same URLs. If you see systematic divergences (410 for the bot, 200 for others), that's a red flag.
Then replace this logic with a meta noindex if your goal is to deindex without removing the page from the site. If the page really needs to disappear, serve a 410 or 404 to everyone — not just the bot.
What common mistakes should you avoid?
Never block a page via robots.txt AND add a meta noindex. Googlebot will never see the tag if the page is blocked from crawling. Result: the page stays indexed with old cached content.
Another pitfall: using .htaccess or Nginx rules that detect the "Googlebot" user-agent to return specific codes. This is exactly what Google considers cloaking, even if your intent isn't malicious.
How do you verify your site is compliant?
Use the URL Inspection tool in Google Search Console. Compare the HTTP code returned during live testing with the one served to users (visible via your browser's DevTools).
Also review your server configuration files (.htaccess, nginx.conf, CDN rules) to detect any conditional logic based on user-agent. If you find rules specifically targeting Googlebot, remove them.
- Audit server logs to detect HTTP code divergences between Googlebot and users
- Replace differentiated 410/404 codes with meta noindex if the page should remain accessible
- Remove any server rules that detect Googlebot to modify HTTP behavior
- Use URL Inspection in Search Console to compare returned codes
- Document the reasons for each noindex directive to prevent mistakes during migrations
❓ Frequently Asked Questions
La meta noindex fonctionne-t-elle aussi rapidement qu'un code 410 pour désindexer ?
Peut-on utiliser X-Robots-Tag dans les headers HTTP au lieu de la meta noindex ?
Si Googlebot reçoit un 410 par erreur de configuration, le site entier risque-t-il une pénalité ?
Les règles de géolocalisation qui renvoient des 3xx selon la région sont-elles considérées comme du cloaking ?
Faut-il supprimer les anciennes URLs désindexées via 410 de sitemap.xml ?
🎥 From the same video 14
Other SEO insights extracted from this same Google Search Central video · published on 12/04/2023
🎥 Watch the full video on YouTube →
💬 Comments (0)
Be the first to comment.