Official statement
Other statements from this video 14 ▾
- □ Peut-on vraiment utiliser un sous-répertoire unique pour gérer plusieurs marchés internationaux avec hreflang ?
- □ Pourquoi Google n'indexe-t-il pas toutes les URLs de votre site ?
- □ Peut-on utiliser des avis tiers pour les résultats enrichis produits ?
- □ Comment savoir si Google vous pénalise vraiment ?
- □ Faut-il abandonner les URI de thésaurus NALT pour optimiser son référencement ?
- □ Pourquoi les erreurs robots.txt unreachable sont-elles toujours de votre faute ?
- □ Faut-il vraiment rediriger vos 404 vers la homepage ?
- □ Faut-il vraiment maintenir les redirections lors d'une migration de domaine ?
- □ Faut-il vraiment éviter le cloaking de codes HTTP entre Googlebot et utilisateurs ?
- □ Google traite-t-il vraiment les redirections 308 et 301 de la même manière ?
- □ La qualité du contenu influence-t-elle vraiment la vitesse d'indexation par Google ?
- □ WiFi vs Wi-Fi : Google fait-il vraiment la différence pour le référencement ?
- □ Un nombre d'avis à zéro pénalise-t-il le référencement d'une page produit ?
- □ Pourquoi certains sites migrés apparaissent-ils dans Google en quelques minutes et d'autres mettent des mois ?
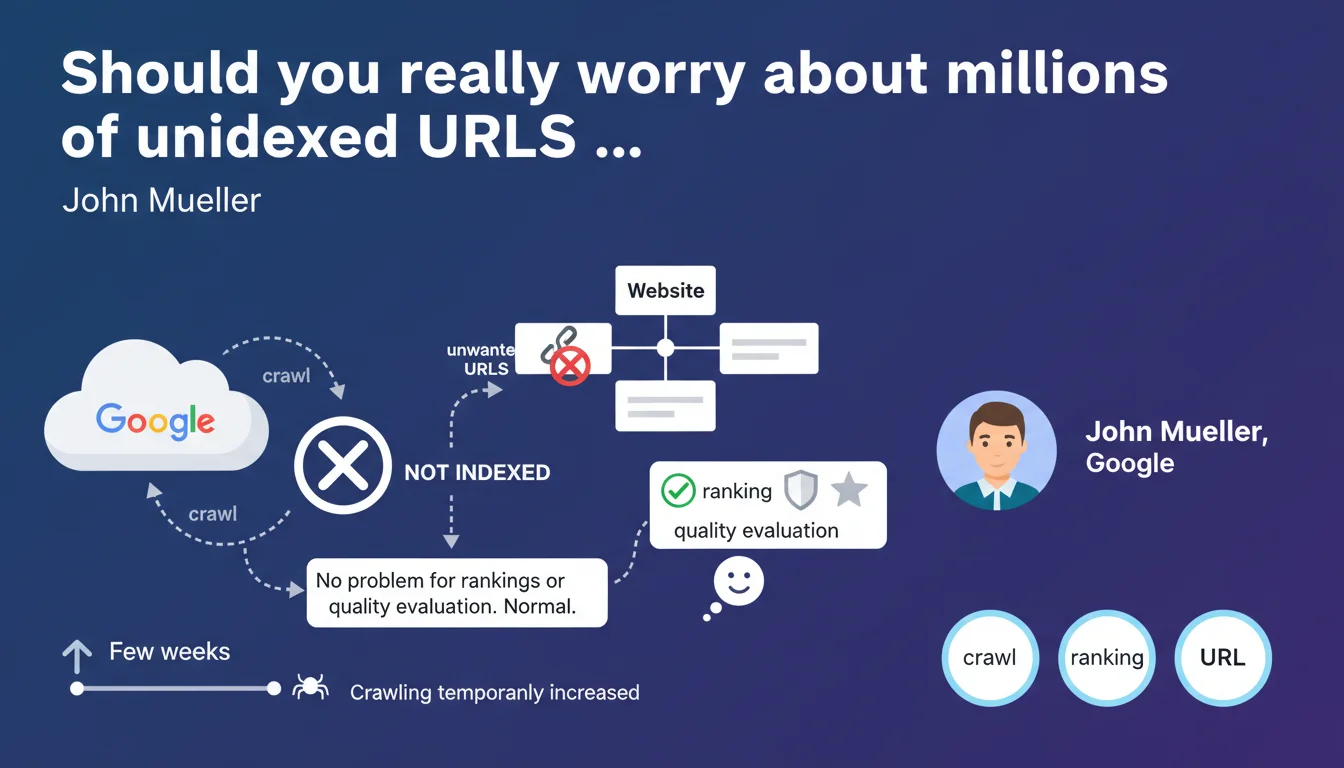
Google says its systems automatically detect and manage technical incidents that generate massive unwanted URLs. A temporary increase in crawling for a few weeks is normal, but the failure to index these pages affects neither rankings nor the site's quality evaluation. Having a large volume of unindexed URLs is not a negative signal.
What you need to understand
Technical incidents that accidentally generate millions of URLs — misconfigured sorting parameters, infinite facets, exposed user sessions — are more common than you might think. Mueller clarifies that these situations do not trigger algorithmic penalties.
Why does Google consider these URLs as unproblematic?
Google's recognition systems identify aberrant patterns: sudden explosion of URLs, repetitive structures, near-identical content. The algorithm understands this is a temporary malfunction, not a deliberate spam strategy.
Crawling can increase for a few weeks — Google explores these new URLs to confirm they're genuinely unnecessary. Once diagnosed, the engine simply stops indexing them without impacting the overall domain evaluation.
What does it really mean: "no problem for quality evaluation"?
Google distinguishes URLs accidentally left unindexed from those intentionally created to manipulate. An e-commerce site generating 500,000 filter variations due to a bug won't be treated as a satellite network.
Having an unbalanced crawled URLs / indexed URLs ratio is therefore not a quality indicator in itself. It's the nature and intent behind these pages that matters, not their absolute volume.
- Google's systems detect technical incident patterns and differentiate them from intentional spam
- A temporary spike in crawling for 2-3 weeks is the algorithm's normal response to a sudden influx of URLs
- The volume of unindexed URLs does not affect quality evaluation if these pages stem from an identified malfunction
- Having millions of discovered but unindexed URLs is a normal state for many medium to large-sized websites
SEO Expert opinion
Is this statement consistent with real-world observations?
Yes, in most observed cases. Sites that experienced accidental URL explosions — for example following a failed production deployment — generally don't suffer sustained organic traffic drops. Google ultimately does ignore these parasitic pages.
But — and this is where Mueller oversimplifies — the indirect impact definitely exists. A multiplication of useless URLs dilutes crawl budget, delays discovery of strategic new content, and can disrupt internal PageRank distribution. The absence of direct penalty doesn't mean "zero operational consequence".
In which cases does this rule not apply?
If unwanted URLs persist for months without correction, Google may reconsider its diagnosis. A tolerated temporary incident becomes a suspicious structural problem. The engine could then reinterpret this mass of URLs as an attempt to manipulate through volume.
Another edge case: websites whose legitimate architecture naturally generates millions of combinations (marketplaces, aggregators, travel sites). For these players, the boundary between "useful but low-performing URLs" and "parasitic URLs" is blurry. [To verify]: Mueller doesn't specify how Google adjusts its tolerance based on the site's business model.
What nuance should be added to "no indexation problem"?
Mueller talks about quality evaluation, not operational efficiency. A site generating 5 million unnecessary pagination URLs won't be penalized, true. But Googlebot will dedicate resources to exploring these pages, at the expense of more strategic sections.
In practice, SEO teams often notice a slowdown in indexing of real new content during the incident period. Google says "no worries", but crawl budget remains a real limited resource — especially for under-crawled sites.
Practical impact and recommendations
What should you concretely do if this incident happens?
First priority: identify and block the source of URL generation. Modify .htaccess, fix code, adjust CMS parameters. As long as the tap stays open, Google will keep exploring and the problem worsens.
Then, clean up the traces: mass deindex via Search Console (URL removals), add temporary robots.txt rules, use canonicals if URLs have a legitimate version. The goal is to reduce noise so Googlebot refocuses its activity.
What mistakes should you avoid when managing this incident?
Don't panic and overreact with drastic solutions. Blocking all crawling or putting the entire site on noindex as a precaution worsens the situation. Google is managing the incident — don't complicate its task with contradictory signals.
Another common mistake: completely ignoring the problem on the grounds that Mueller says "no worries". True, no immediate algorithmic penalty, but real operational impact on indexing velocity and server log readability.
- Audit server logs to identify the URL pattern generated (parameters, structure, volume)
- Fix the problem's source before any cleanup action — otherwise URLs recreate in a loop
- Use the URL removal tool in Search Console to accelerate clearing
- Add targeted robots.txt rules to block crawling of problematic patterns (without locking everything down)
- Monitor crawl budget for 4-6 weeks to verify return to normal
- Verify that new strategic content is properly crawled and indexed within usual timeframes
How can you anticipate this type of incident in the future?
Set up automatic alerts on discovered URL volume (Search Console API, third-party crawlers). Abnormal growth threshold should trigger immediate notification before Google detects the problem.
Rigorously test each deployment likely to modify URL structure: facets, filters, pagination, sorting parameters. A staging environment with simulated crawling lets you identify leaks before production launch.
Google tolerates technical incidents generating massive unwanted URLs, but this tolerance doesn't exempt you from quick correction. The absence of direct penalty doesn't mean absence of operational impact on crawling and indexing.
Managing this type of incident — detection, diagnosis, correction, cleanup, monitoring — requires specialized technical expertise and controlled reactivity. For large websites or complex architectures, support from a specialized SEO agency can prove crucial in minimizing incident duration and impact, while avoiding counterproductive overreactions.
❓ Frequently Asked Questions
Combien de temps Google met-il à normaliser le crawl après un incident d'URLs massif ?
Un ratio URLs découvertes / URLs indexées très déséquilibré est-il un signal négatif ?
Faut-il utiliser l'outil de suppression d'URLs dans Search Console pour nettoyer après l'incident ?
Est-ce que bloquer ces URLs dans le robots.txt après coup est utile ?
Google peut-il confondre un incident technique avec une tentative de spam ?
🎥 From the same video 14
Other SEO insights extracted from this same Google Search Central video · published on 12/04/2023
🎥 Watch the full video on YouTube →
💬 Comments (0)
Be the first to comment.