Declaration officielle
Autres déclarations de cette vidéo 14 ▾
- □ Peut-on vraiment utiliser un sous-répertoire unique pour gérer plusieurs marchés internationaux avec hreflang ?
- □ Pourquoi Google n'indexe-t-il pas toutes les URLs de votre site ?
- □ Peut-on utiliser des avis tiers pour les résultats enrichis produits ?
- □ Comment savoir si Google vous pénalise vraiment ?
- □ Faut-il abandonner les URI de thésaurus NALT pour optimiser son référencement ?
- □ Pourquoi les erreurs robots.txt unreachable sont-elles toujours de votre faute ?
- □ Faut-il vraiment rediriger vos 404 vers la homepage ?
- □ Faut-il vraiment maintenir les redirections lors d'une migration de domaine ?
- □ Faut-il s'inquiéter de millions d'URLs non indexées sur son site ?
- □ Google traite-t-il vraiment les redirections 308 et 301 de la même manière ?
- □ La qualité du contenu influence-t-elle vraiment la vitesse d'indexation par Google ?
- □ WiFi vs Wi-Fi : Google fait-il vraiment la différence pour le référencement ?
- □ Un nombre d'avis à zéro pénalise-t-il le référencement d'une page produit ?
- □ Pourquoi certains sites migrés apparaissent-ils dans Google en quelques minutes et d'autres mettent des mois ?
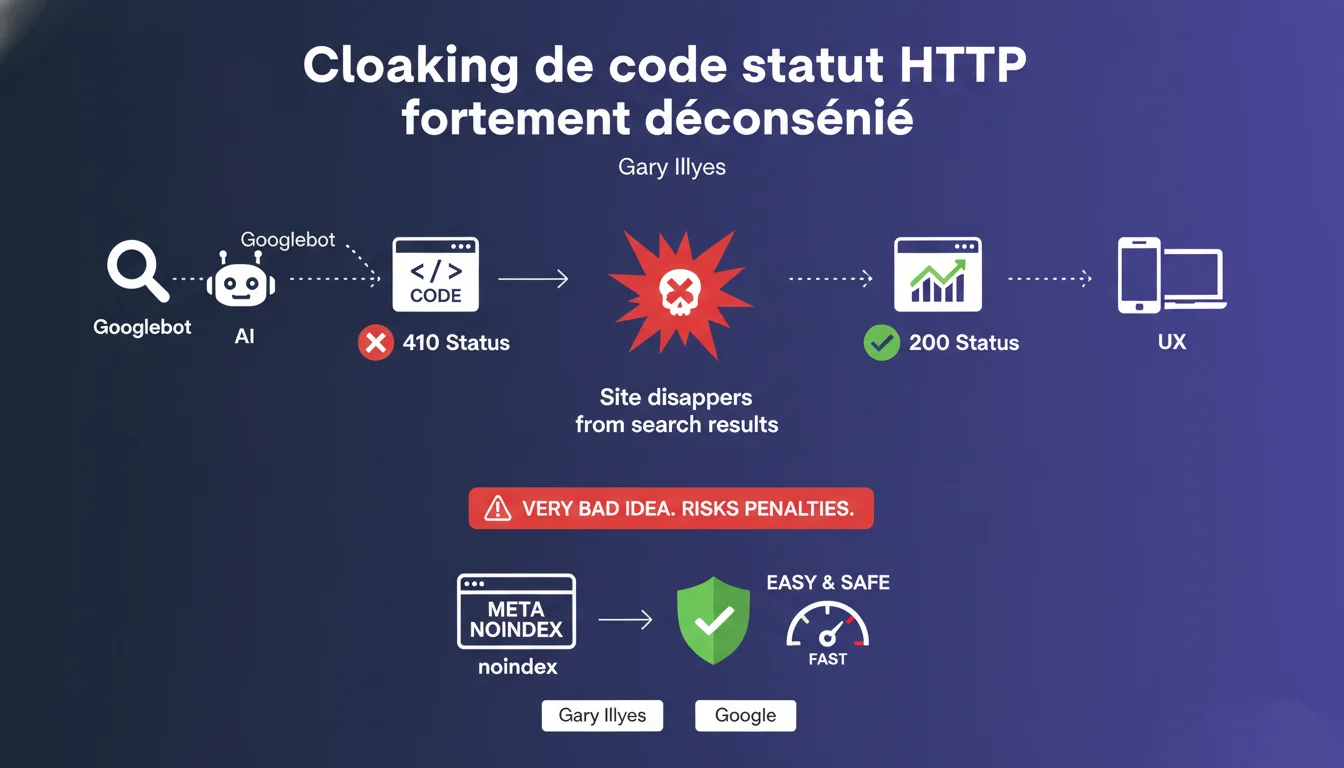
Google qualifie explicitement de cloaking le fait de servir un code statut 410 à Googlebot et 200 aux utilisateurs. La recommandation officielle pour retirer du contenu : utiliser la balise meta noindex plutôt que de jouer avec les codes HTTP différenciés. Le risque ? Une désindexation complète du site si les conditions de service détectent l'anomalie.
Ce qu'il faut comprendre
Gary Illyes cible ici une pratique probablement plus répandue qu'on ne le pense : différencier volontairement le code statut HTTP servi à Googlebot de celui envoyé aux visiteurs humains.
L'exemple cité — 410 pour le bot, 200 pour l'utilisateur — est une forme de cloaking technique. Et Google le dit sans détour : c'est une très mauvaise idée.
Pourquoi cette pratique existe-t-elle encore ?
Certains sites cherchent à contrôler finement ce que Google indexe sans impacter l'expérience utilisateur. Envoyer un 410 (Gone) à Googlebot tout en maintenant un 200 pour les visiteurs permet théoriquement de désindexer une page sans la retirer du site.
Le problème ? C'est exactement la définition du cloaking : montrer une chose au moteur, une autre aux utilisateurs. Et les Guidelines de Google sont claires sur ce point depuis des années.
Quelles sont les conséquences concrètes évoquées ?
Illyes mentionne que « quelque chose finira par mal tourner » — formulation volontairement vague mais menaçante. Il évoque les « conditions de service », ce qui laisse entendre une action manuelle ou algorithmique détectant l'anomalie.
Le résultat : le site peut disparaître complètement des résultats de recherche. Pas juste la page concernée — le site entier. C'est une pénalité grave, probablement manuelle.
Quelle alternative Google propose-t-il ?
La solution recommandée est simple : utiliser la balise meta noindex. Selon Illyes, c'est « plus facile et plus sûr ».
Concretement, ça signifie servir un code 200 à tout le monde, mais ajouter <meta name="robots" content="noindex"> dans le <head> de la page. Googlebot crawle, voit la directive, et retire la page de l'index sans que l'utilisateur soit impacté.
- Le cloaking de codes HTTP est explicitement interdit — même pour désindexer
- La meta noindex est la méthode officielle pour retirer du contenu sans affecter les utilisateurs
- Les risques sont réels : désindexation complète du site en cas de détection
- Google détecte ces pratiques — probablement via des signaux automatiques et manuels
Avis d'un expert SEO
Cette déclaration est-elle cohérente avec les observations terrain ?
Oui, totalement. Les cas de désindexation massive suite à du cloaking — même involontaire — sont documentés. Ce qui est intéressant ici, c'est que Google classe explicitement la différenciation de codes HTTP comme du cloaking.
Certains praticiens considéraient que seul le contenu HTML différencié était concerné. Cette déclaration ferme la porte : les codes statut HTTP font partie intégrante de la réponse serveur, et les différencier entre bot et utilisateur est sanctionnable.
La meta noindex est-elle vraiment « plus sûre » dans tous les cas ?
Presque toujours, mais pas systématiquement. La meta noindex nécessite que Googlebot puisse crawler la page pour lire la directive. Si vous bloquez la page via robots.txt, la balise ne sera jamais vue.
De plus, une meta noindex retire la page de l'index mais ne supprime pas forcément les signaux associés (liens, autorité). Un 410 ou 404 est plus radical — ce qui peut être souhaitable dans certains contextes (contenu dupliqué, pages obsolètes définitivement).
[A verifier] : Google affirme que « quelque chose finira par mal tourner », mais ne précise pas si cette détection est automatique, manuelle, ou basée sur des signaux utilisateurs. Le flou reste entier sur les mécanismes exacts.
Existe-t-il des exceptions légitimes ?
Oui — et c'est là que ça devient délicat. Les sites qui servent du contenu géolocalisé ou des paywall peuvent légitimement renvoyer des codes différents selon le contexte utilisateur (localisation, abonnement).
Mais la nuance critique est : différencier selon le user-agent (Googlebot vs humain) reste du cloaking. Différencier selon la géolocalisation ou l'authentification, c'est acceptable si appliqué uniformément — bot inclus.
Impact pratique et recommandations
Que faut-il faire immédiatement si vous différenciez les codes HTTP ?
Première étape : auditer vos logs serveur. Comparez les codes HTTP renvoyés à Googlebot vs. les utilisateurs pour les mêmes URLs. Si vous voyez des divergences systématiques (410 pour le bot, 200 pour les autres), c'est rouge.
Ensuite, remplacez cette logique par une meta noindex si l'objectif est de désindexer sans retirer la page du site. Si la page doit vraiment disparaître, servez un 410 ou 404 à tout le monde — pas juste au bot.
Quelles erreurs courantes faut-il éviter ?
Ne jamais bloquer une page via robots.txt ET ajouter une meta noindex. Googlebot ne verra jamais la balise si la page est bloquée au crawl. Résultat : la page reste indexée avec l'ancien contenu en cache.
Autre piège : utiliser des règles .htaccess ou Nginx qui détectent le user-agent « Googlebot » pour renvoyer des codes spécifiques. C'est exactement ce que Google considère comme du cloaking, même si l'intention n'est pas malveillante.
Comment vérifier que votre site est conforme ?
Utilisez l'outil Inspection d'URL dans Google Search Console. Comparez le code HTTP renvoyé lors du test en direct avec celui servi aux utilisateurs (visible via les DevTools du navigateur).
Vérifiez aussi vos fichiers de configuration serveur (.htaccess, nginx.conf, règles CDN) pour détecter toute logique conditionnelle basée sur le user-agent. Si vous trouvez des règles qui ciblent spécifiquement Googlebot, supprimez-les.
- Auditer les logs serveur pour détecter les divergences de codes HTTP entre Googlebot et utilisateurs
- Remplacer les 410/404 différenciés par une meta noindex si la page doit rester accessible
- Supprimer toute règle serveur qui détecte Googlebot pour modifier le comportement HTTP
- Utiliser l'Inspection d'URL dans Search Console pour comparer les codes renvoyés
- Documenter les raisons de chaque directive noindex pour éviter les erreurs lors des migrations
❓ Questions frequentes
La meta noindex fonctionne-t-elle aussi rapidement qu'un code 410 pour désindexer ?
Peut-on utiliser X-Robots-Tag dans les headers HTTP au lieu de la meta noindex ?
Si Googlebot reçoit un 410 par erreur de configuration, le site entier risque-t-il une pénalité ?
Les règles de géolocalisation qui renvoient des 3xx selon la région sont-elles considérées comme du cloaking ?
Faut-il supprimer les anciennes URLs désindexées via 410 de sitemap.xml ?
🎥 De la même vidéo 14
Autres enseignements SEO extraits de cette même vidéo Google Search Central · publiée le 12/04/2023
🎥 Voir la vidéo complète sur YouTube →
💬 Commentaires (0)
Soyez le premier à commenter.