Declaration officielle
Autres déclarations de cette vidéo 14 ▾
- □ Peut-on vraiment utiliser un sous-répertoire unique pour gérer plusieurs marchés internationaux avec hreflang ?
- □ Pourquoi Google n'indexe-t-il pas toutes les URLs de votre site ?
- □ Peut-on utiliser des avis tiers pour les résultats enrichis produits ?
- □ Comment savoir si Google vous pénalise vraiment ?
- □ Faut-il abandonner les URI de thésaurus NALT pour optimiser son référencement ?
- □ Faut-il vraiment rediriger vos 404 vers la homepage ?
- □ Faut-il vraiment maintenir les redirections lors d'une migration de domaine ?
- □ Faut-il s'inquiéter de millions d'URLs non indexées sur son site ?
- □ Faut-il vraiment éviter le cloaking de codes HTTP entre Googlebot et utilisateurs ?
- □ Google traite-t-il vraiment les redirections 308 et 301 de la même manière ?
- □ La qualité du contenu influence-t-elle vraiment la vitesse d'indexation par Google ?
- □ WiFi vs Wi-Fi : Google fait-il vraiment la différence pour le référencement ?
- □ Un nombre d'avis à zéro pénalise-t-il le référencement d'une page produit ?
- □ Pourquoi certains sites migrés apparaissent-ils dans Google en quelques minutes et d'autres mettent des mois ?
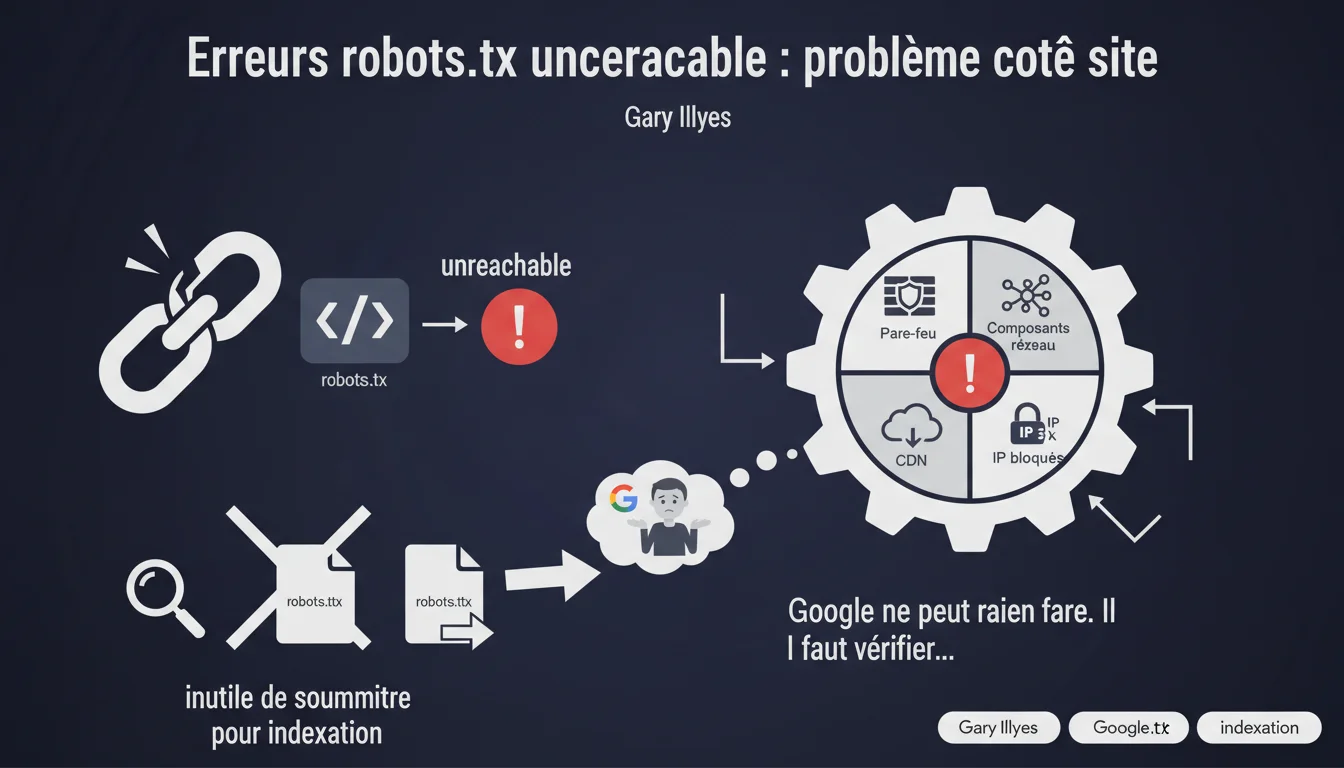
Les erreurs robots.txt unreachable ne viennent jamais de Google. Gary Illyes est formel : le problème se situe systématiquement côté site — pare-feu trop strict, CDN mal configuré, IP de Googlebot bloquée. Soumettre le fichier robots.txt à l'indexation ne sert à rien.
Ce qu'il faut comprendre
Que signifie vraiment « unreachable » pour Google ?
Quand Google remonte une erreur robots.txt unreachable, cela signifie que Googlebot n'a pas pu accéder au fichier robots.txt de votre site au moment du crawl. Pas qu'il n'existe pas, pas qu'il est mal formaté — simplement que la requête HTTP a échoué.
Ce diagnostic ne concerne donc pas le contenu du fichier, mais l'accessibilité technique de la ressource. Google tente de récupérer robots.txt avant chaque crawl. Si la réponse met trop de temps, si elle retourne une erreur serveur (5xx), si la connexion est refusée, l'erreur est déclenchée.
Pourquoi Google dit-il ne rien pouvoir faire ?
Parce que l'erreur se situe entre le bot et votre infrastructure. Google ne contrôle ni votre pare-feu, ni votre CDN, ni vos règles de rate limiting. Si Googlebot se fait bloquer, c'est que quelque chose — volontairement ou non — l'empêche d'atteindre le fichier.
Gary Illyes insiste : c'est systématique. Les configurations réseau mal calibrées sont la cause la plus fréquente. Un WAF qui considère le user-agent de Googlebot comme suspect, un CDN qui rate-limit trop agressivement, une règle .htaccess qui bloque une plage d'IP — autant de scénarios courants.
Pourquoi soumettre robots.txt à l'indexation est inutile ?
Parce que robots.txt n'est jamais indexé. Il est lu avant le crawl, pas traité comme une page classique. Le soumettre via la Search Console n'a aucun effet — ce n'est pas une URL candidate à l'indexation, c'est un fichier de directives.
Si Google ne peut pas y accéder lors du crawl, le soumettre après coup ne changera rien. Il faut corriger le problème d'accessibilité en amont, pas tenter de forcer une indexation qui n'a pas lieu d'être.
- L'erreur unreachable signifie une impossibilité technique d'accès, pas un problème de contenu
- Google ne contrôle pas votre infrastructure : pare-feu, CDN, rate limiting sont de votre ressort
- Soumettre robots.txt à l'indexation est une fausse manipulation sans effet
- Les causes fréquentes : IP bloquées, timeouts, WAF trop strict, CDN mal configuré
Avis d'un expert SEO
Cette déclaration est-elle cohérente avec les observations terrain ?
Oui, totalement. Sur le terrain, les erreurs robots.txt unreachable sont presque toujours liées à des blocages réseau. On voit régulièrement des Cloudflare mal paramétrés qui rate-limitent Googlebot, des pare-feu applicatifs qui blacklistent des plages IP de Google, des configurations nginx qui timeout trop vite.
Ce qui surprend parfois, c'est la variabilité temporelle. Un site peut être accessible 95 % du temps, mais si Google tombe sur une période de charge élevée ou une règle de sécurité mal calibrée, l'erreur est remontée. Le problème, c'est que ces incidents peuvent passer inaperçus côté webmaster si personne ne surveille activement la Search Console.
Quelles nuances faut-il apporter ?
Gary Illyes dit « toujours côté site », mais il faut préciser : parfois, c'est involontaire et difficile à diagnostiquer. Un hébergeur qui change une règle de pare-feu sans prévenir, un CDN qui applique un nouveau profil de sécurité, un plugin WordPress qui bloque les bots par défaut — autant de cas où le webmaster n'a rien touché consciemment.
Autre point : Google parle d'« IP bloquées », mais les plages IP de Googlebot changent. Si vous avez whitelisté des adresses en dur plutôt que de vérifier via reverse DNS, vous risquez de bloquer le bot sans le savoir. [A vérifier] : Google ne publie pas toujours de manière proactive les ajouts de nouvelles plages.
Dans quels cas cette règle ne s'applique-t-elle pas ?
Il existe des cas limites où l'erreur peut provenir d'un bug côté Google, mais c'est extrêmement rare. Si vous constatez une erreur unreachable alors que votre robots.txt répond correctement en 200 pour tous les autres crawlers et que vous avez vérifié les IP, contactez le support Search Console.
Dans 99 % des cas, cependant, creuser côté infrastructure suffit. Les logs serveur sont votre meilleur allié : cherchez les requêtes vers /robots.txt avec un user-agent Googlebot et regardez les codes de réponse. Si vous voyez des 403, 503 ou des timeouts, vous avez votre coupable.
Impact pratique et recommandations
Que faut-il faire concrètement quand l'erreur apparaît ?
Première étape : vérifier l'accessibilité du fichier depuis plusieurs IP et user-agents. Utilisez un outil comme curl avec le user-agent Googlebot, testez depuis un serveur externe, utilisez l'outil d'inspection d'URL de la Search Console.
Si le fichier répond correctement lors de vos tests mais que l'erreur persiste, creusez les logs serveur. Cherchez les requêtes vers /robots.txt provenant de Googlebot. Identifiez les codes de réponse : 403, 503, timeout ? Cela vous dira où chercher.
Quelles erreurs éviter ?
Ne bloquez jamais Googlebot via robots.txt — ça semble évident, mais on voit encore des sites avec des règles User-agent: Googlebot / Disallow: /. Ne bloquez pas non plus les plages IP de Google dans votre pare-feu. Vérifiez toujours via reverse DNS plutôt que de whitelister des adresses en dur.
Autre erreur classique : un CDN avec un cache trop agressif. Si votre robots.txt est caché pendant 24 heures et que Google tente d'y accéder pendant un incident, il récupère une erreur mise en cache. Configurez un TTL court pour ce fichier — 1 heure maximum.
Comment vérifier que mon site est conforme ?
Utilisez l'outil de test de robots.txt dans la Search Console. Testez l'accessibilité depuis plusieurs localisations géographiques. Vérifiez que votre pare-feu ou WAF ne bloque pas les user-agents Google. Consultez régulièrement les rapports de couverture pour détecter toute erreur unreachable.
Si vous utilisez un CDN type Cloudflare, vérifiez les règles de rate limiting et les paramètres de sécurité. Assurez-vous que les IP de Googlebot sont whitelistées ou que les règles de challenge ne s'appliquent pas à ce user-agent.
- Tester l'accessibilité de robots.txt avec le user-agent Googlebot depuis plusieurs IP
- Consulter les logs serveur pour identifier les codes de réponse HTTP vers /robots.txt
- Vérifier les règles de pare-feu, WAF et CDN pour s'assurer que Googlebot n'est pas bloqué
- Ne jamais whitelister des IP Google en dur — utiliser la vérification par reverse DNS
- Configurer un TTL court (1h max) pour le cache de robots.txt
- Surveiller régulièrement la Search Console pour détecter les erreurs unreachable
- Ne pas tenter de soumettre robots.txt à l'indexation — cela n'a aucun effet
❓ Questions frequentes
Que faire si l'erreur robots.txt unreachable apparaît alors que le fichier est accessible lors de mes tests ?
Est-ce grave si l'erreur n'apparaît qu'occasionnellement ?
Faut-il absolument avoir un fichier robots.txt ?
Mon hébergeur peut-il être responsable de l'erreur ?
Comment whitelister Googlebot correctement ?
🎥 De la même vidéo 14
Autres enseignements SEO extraits de cette même vidéo Google Search Central · publiée le 12/04/2023
🎥 Voir la vidéo complète sur YouTube →
💬 Commentaires (0)
Soyez le premier à commenter.