Declaration officielle
Autres déclarations de cette vidéo 12 ▾
- □ La balise meta robots noindex suffit-elle vraiment à empêcher l'indexation d'une page ?
- □ Peut-on vraiment piloter Googlebot News et Googlebot Search avec des balises meta robots distinctes ?
- □ Peut-on vraiment empiler plusieurs directives meta robots dans une seule balise ?
- □ L'en-tête HTTP X-Robots peut-il remplacer la balise meta robots ?
- □ Où faut-il vraiment placer le fichier robots.txt pour qu'il soit pris en compte ?
- □ Faut-il gérer un robots.txt distinct pour chaque sous-domaine ?
- □ Le fichier robots.txt est-il vraiment respecté par tous les moteurs de recherche ?
- □ Faut-il utiliser les wildcards dans robots.txt pour mieux contrôler son crawl ?
- □ Faut-il vraiment déclarer son sitemap XML dans le fichier robots.txt ?
- □ Pourquoi ne faut-il jamais combiner robots.txt et meta noindex sur la même page ?
- □ Robots.txt bloque-t-il vraiment l'indexation de vos pages ?
- □ Le rapport robots.txt de Google Search Console change-t-il vraiment la donne pour le crawl ?
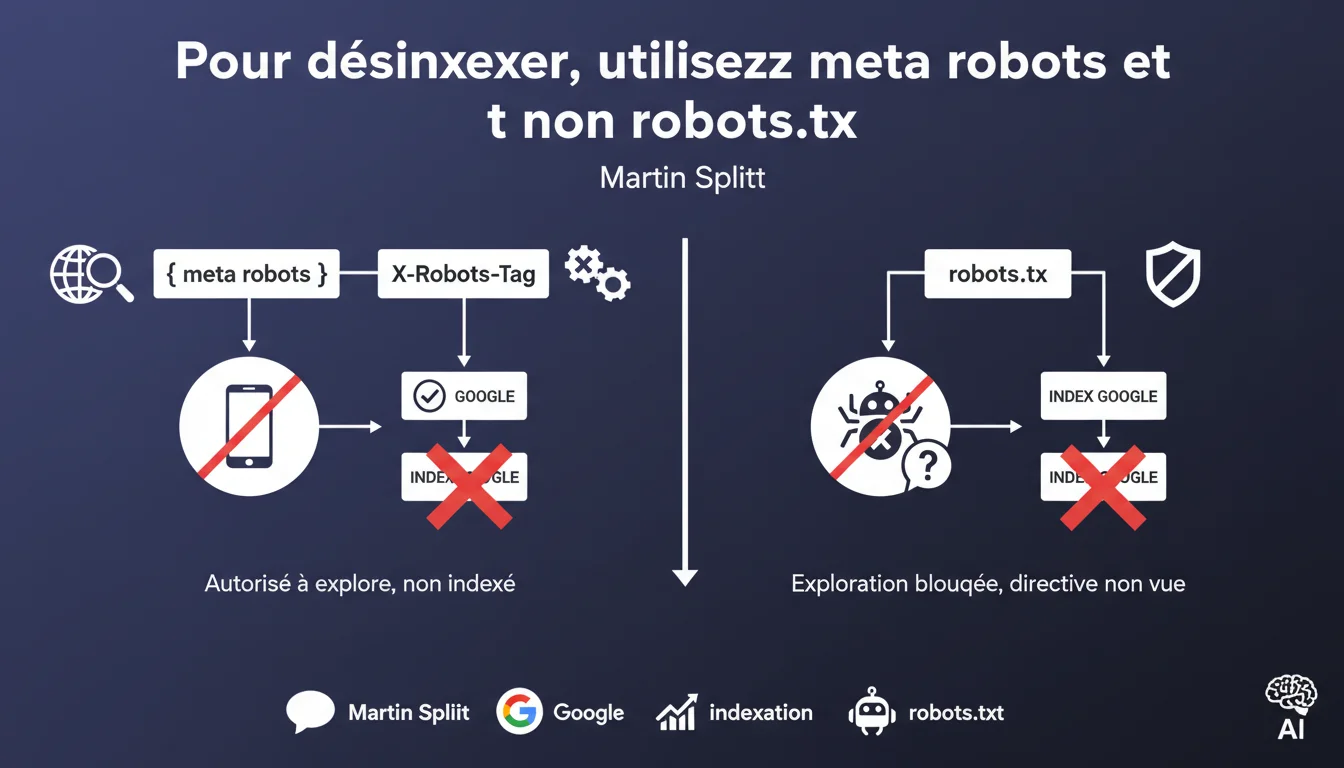
Bloquer une page via robots.txt ne la désindexe pas — au contraire, ça empêche Googlebot de lire vos directives noindex. Pour désindexer proprement, utilisez meta robots ou X-Robots-Tag, jamais robots.txt. Une confusion fréquente qui coûte cher en visibilité.
Ce qu'il faut comprendre
Quel est le piège du robots.txt pour la désindexation ?
Le robots.txt bloque le crawl, pas l'indexation. Si Googlebot ne peut pas accéder à une page, il ne voit pas non plus votre balise noindex. Résultat : la page peut rester indexée avec une URL et parfois un snippet généré depuis des sources externes.
Google peut indexer une URL sans même crawler la page — sur la base de backlinks, de mentions ou d'anciennes versions en cache. Bloquer le crawl ne résout rien si la page est déjà connue du moteur.
Comment fonctionnent réellement meta robots et X-Robots-Tag ?
La balise meta robots noindex se place dans le <head> d'une page HTML. L'en-tête X-Robots-Tag s'envoie via le serveur (utile pour les PDFs, images, fichiers non-HTML). Dans les deux cas, Googlebot doit pouvoir crawler la page pour lire la directive.
Une fois la directive détectée, Google retire la page de son index au prochain passage. Si vous bloquez le crawl ensuite dans robots.txt, la directive reste effective — mais mieux vaut laisser Googlebot vérifier périodiquement.
Que se passe-t-il si je bloque une page noindex dans robots.txt ?
Googlebot ne peut plus vérifier si la directive noindex est toujours en place. Si vous supprimez ensuite la balise noindex mais gardez le blocage robots.txt, la page peut se réindexer sans que vous le vouliez — parce que Google n'a aucun moyen de confirmer votre intention.
- robots.txt bloque le crawl, pas l'indexation — confusion fréquente.
- meta robots noindex et X-Robots-Tag sont les seules méthodes fiables pour désindexer.
- Googlebot doit pouvoir crawler la page pour lire les directives de désindexation.
- Bloquer après désindexation fonctionne, mais empêche la vérification future des directives.
- Une page bloquée dans robots.txt peut quand même apparaître dans les SERPs si Google la connaît par ailleurs.
Avis d'un expert SEO
Cette directive est-elle cohérente avec les observations terrain ?
Oui — et c'est même l'une des rares déclarations de Google parfaitement alignées avec la réalité. On voit régulièrement des sites bloquer des pages sensibles (dev, staging, admin) uniquement via robots.txt, puis s'étonner de les retrouver indexées avec l'URL visible dans les SERPs.
La confusion vient souvent du fait que robots.txt semble interdire Google. Mais le fichier ne contrôle que l'accès au contenu, pas la présence dans l'index. Si une URL est mentionnée ailleurs sur le web, Google peut l'indexer sans jamais la crawler.
Quelles nuances faut-il apporter à cette règle ?
Si une page n'a jamais été crawlée ni connue de Google, la bloquer dans robots.txt suffit à empêcher son indexation future. Mais dès qu'elle est découverte — backlink, sitemap, lien interne — le blocage devient contre-productif.
Autre cas : les pages orphelines avec noindex mais sans robots.txt. Si Googlebot ne les trouve jamais (pas de liens internes, pas de sitemap), la directive noindex ne sert à rien. Il faut d'abord que Google accède à la page pour lire la balise.
Et soyons honnêtes : certains outils tiers (crawlers SEO, scrapers) ignorent robots.txt. Bloquer une page sensible uniquement via ce fichier, c'est miser sur la bonne volonté des bots. Autant ajouter une authentification serveur si la confidentialité est critique.
Dans quels cas cette approche pose-t-elle problème ?
Les sites avec du contenu dupliqué massif (e-commerce avec filtres, sites multilingues mal configurés) peuvent vouloir bloquer certaines URLs dans robots.txt pour économiser du crawl budget. Sauf que si ces pages sont déjà indexées, le blocage fige la situation — impossible de pousser un noindex ensuite.
La solution propre : d'abord appliquer le noindex, attendre la désindexation (quelques jours à quelques semaines selon la fréquence de crawl), puis bloquer dans robots.txt si nécessaire. Ou mieux : utiliser les canoniques pour concentrer l'indexation plutôt que de multiplier les blocages.
Impact pratique et recommandations
Que faut-il faire concrètement pour désindexer une page ?
Ajoutez <meta name="robots" content="noindex"> dans le <head> de la page HTML. Pour les fichiers non-HTML (PDFs, images), configurez l'en-tête X-Robots-Tag: noindex au niveau du serveur (Apache, Nginx, ou via règles CDN).
Vérifiez que la page n'est pas bloquée dans robots.txt. Si elle l'est, retirez le blocage temporairement le temps que Googlebot crawle et lise la directive noindex. Une fois la page désindexée (vérifiable via site:example.com/url), vous pouvez bloquer à nouveau si vous voulez économiser du crawl budget — mais ce n'est pas obligatoire.
Quelles erreurs éviter absolument ?
Ne bloquez jamais une page dans robots.txt en pensant qu'elle disparaîtra de l'index. C'est l'inverse qui se produit : elle reste indexée avec une URL visible, parfois un snippet généré depuis des liens externes ou des ancres.
Évitez aussi de cumuler noindex + canonical vers une autre page. Google privilégie le canonical et ignore le noindex — résultat imprévisible. Si vous voulez désindexer, faites-le proprement avec noindex seul, sans canonical contradictoire.
Comment vérifier que la désindexation fonctionne ?
Utilisez site:example.com/url-exacte dans Google. Si la page apparaît encore, attendez quelques jours — la désindexation n'est pas instantanée. Vous pouvez aussi forcer un re-crawl via la Search Console (Inspection d'URL → Demander une indexation).
Vérifiez les logs serveur pour confirmer que Googlebot accède bien à la page. Si le bot ne passe jamais, la directive noindex ne sera jamais lue — et la page restera indexée indéfiniment.
- Ajoutez meta robots noindex ou X-Robots-Tag sur les pages à désindexer.
- Assurez-vous que ces pages ne sont pas bloquées dans robots.txt.
- Attendez que Googlebot crawle et traite la directive (quelques jours à quelques semaines).
- Vérifiez la désindexation avec
site:dans Google ou via Search Console. - Si la page reste indexée, inspectez les logs pour confirmer le crawl et vérifiez l'absence de canonical contradictoire.
- Une fois désindexée, vous pouvez bloquer dans robots.txt pour économiser du crawl budget — mais ce n'est pas obligatoire.
❓ Questions frequentes
Peut-on bloquer une page dans robots.txt après l'avoir désindexée avec noindex ?
Une page bloquée dans robots.txt peut-elle apparaître dans les SERPs ?
Faut-il retirer le blocage robots.txt avant d'appliquer un noindex ?
Quelle différence entre meta robots et X-Robots-Tag ?
Combien de temps faut-il pour qu'une page disparaisse de l'index après un noindex ?
🎥 De la même vidéo 12
Autres enseignements SEO extraits de cette même vidéo Google Search Central · publiée le 04/12/2024
🎥 Voir la vidéo complète sur YouTube →
💬 Commentaires (0)
Soyez le premier à commenter.