Declaration officielle
Autres déclarations de cette vidéo 12 ▾
- □ La balise meta robots noindex suffit-elle vraiment à empêcher l'indexation d'une page ?
- □ Peut-on vraiment empiler plusieurs directives meta robots dans une seule balise ?
- □ L'en-tête HTTP X-Robots peut-il remplacer la balise meta robots ?
- □ Où faut-il vraiment placer le fichier robots.txt pour qu'il soit pris en compte ?
- □ Faut-il gérer un robots.txt distinct pour chaque sous-domaine ?
- □ Le fichier robots.txt est-il vraiment respecté par tous les moteurs de recherche ?
- □ Faut-il utiliser les wildcards dans robots.txt pour mieux contrôler son crawl ?
- □ Faut-il vraiment déclarer son sitemap XML dans le fichier robots.txt ?
- □ Pourquoi ne faut-il jamais combiner robots.txt et meta noindex sur la même page ?
- □ Pourquoi robots.txt empêche-t-il Google de désindexer vos pages ?
- □ Robots.txt bloque-t-il vraiment l'indexation de vos pages ?
- □ Le rapport robots.txt de Google Search Console change-t-il vraiment la donne pour le crawl ?
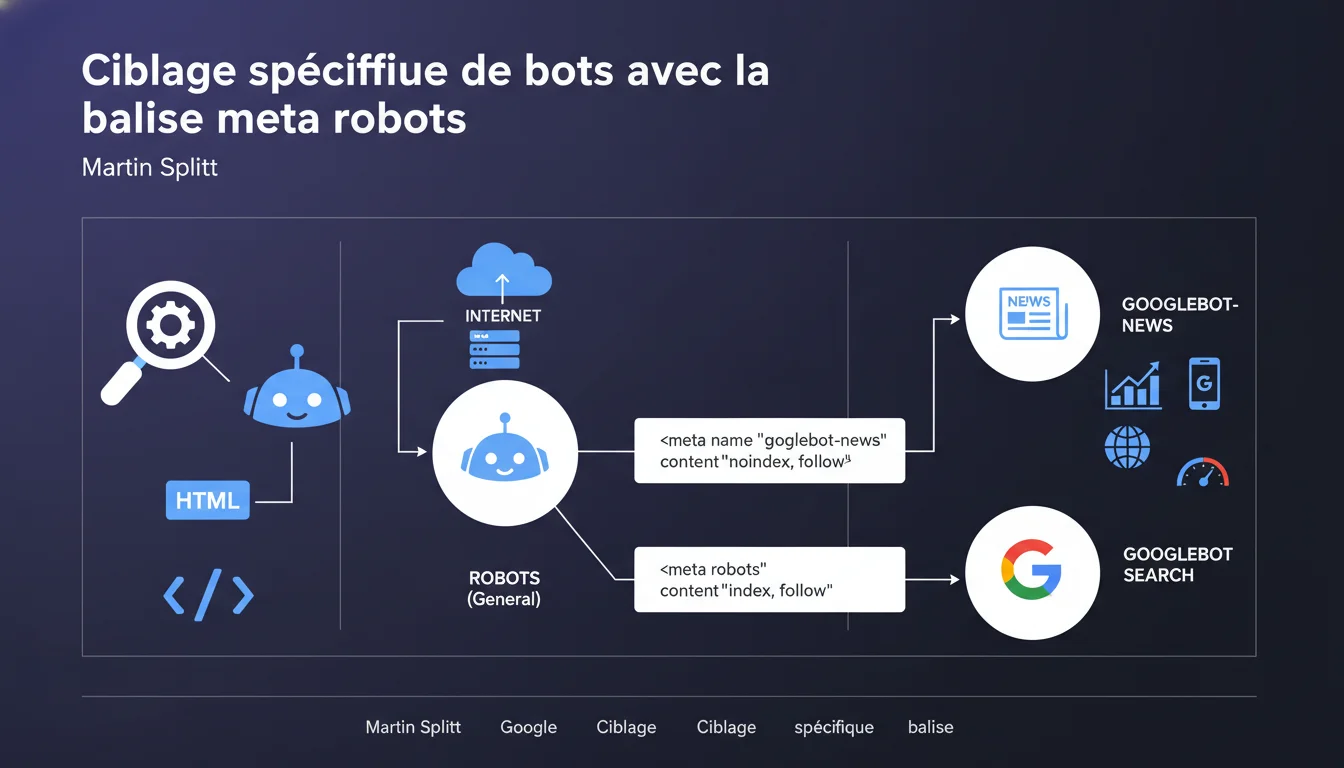
Google confirme qu'on peut cibler des robots spécifiques via l'attribut 'name' de la balise meta robots. En utilisant 'googlebot-news' au lieu de 'robots', on donne des instructions uniquement à Googlebot News sans impacter Googlebot Search classique. Cette granularité permet un pilotage différencié du crawl selon les verticales Google.
Ce qu'il faut comprendre
Pourquoi cette distinction entre robots Googlebot est-elle possible ?
La balise meta robots standard avec name="robots" s'applique à tous les crawlers sans distinction. Mais Google exploite plusieurs versions de Googlebot selon la verticale : Googlebot Search, Googlebot News, Googlebot Images, etc.
Chaque bot peut recevoir des directives spécifiques via l'attribut name. Concrètement, googlebot-news ne s'adresse qu'au crawler News, tandis que Googlebot Search ignore cette instruction et suit uniquement celles qui le ciblent explicitement ou la directive générique 'robots'.
Quelle est la logique de priorité entre ces directives ?
La règle est simple : le ciblage spécifique l'emporte sur le générique. Si tu définis à la fois name="robots" et name="googlebot-news", ce dernier prévaut pour le bot News.
Exemple : meta name="robots" content="index, follow" + meta name="googlebot-news" content="noindex" → la page sera indexée dans Search mais pas dans Google News. Cette hiérarchie permet un contrôle granulaire sans conflit entre directives.
Quels sont les identifiants de bots reconnus par Google ?
Google documente plusieurs identifiants : googlebot (générique pour tout Googlebot), googlebot-news, googlebot-images, googlebot-video, googlebot-shopping. Chacun répond à sa directive spécifique.
Le piège : utiliser un identifiant fantaisiste ou mal orthographié ne provoquera aucune erreur, mais la directive sera simplement ignorée. Vérifie toujours la casse et l'orthographe exacte — googlebot-news, pas googlebotNews ou googlebot_news.
- Les directives spécifiques priment sur les directives génériques (googlebot-news > robots)
- Chaque vertical Googlebot possède son propre identifiant à utiliser dans l'attribut 'name'
- Une page peut cumuler plusieurs balises meta robots avec des cibles différentes sans conflit
- L'ordre des balises meta dans le HTML n'a aucune importance, seule la spécificité compte
- Un identifiant erroné ou inventé sera silencieusement ignoré sans génération d'erreur
Avis d'un expert SEO
Cette déclaration est-elle cohérente avec ce qu'on observe sur le terrain ?
Oui, et c'est documenté depuis des années dans la documentation technique de Google. Sauf que peu de praticiens l'exploitent réellement — la plupart se contentent de la balise robots générique.
On voit surtout cette approche sur les sites médias qui veulent exclure certaines sections de Google News (par exemple des contenus sponsorisés ou des pages auteurs) tout en les gardant indexées dans Search. Concrètement, ça fonctionne : une page avec noindex pour googlebot-news disparaît bien de News mais reste dans les résultats classiques.
Quelles nuances faut-il apporter à cette affirmation ?
Martin Splitt simplifie un peu. Les directives génériques robots s'appliquent aussi à Googlebot si aucune directive spécifique googlebot n'est définie. Donc robots + googlebot-news ne suffit pas toujours : il peut être judicieux d'ajouter googlebot ou googlebot-images selon les besoins.
Autre point : cette granularité fonctionne pour les balises meta, mais robots.txt ne permet pas ce niveau de ciblage fin. Le User-agent dans robots.txt distingue bien Googlebot-News de Googlebot, mais on reste sur une logique de blocage de chemins, pas de directives d'indexation page par page. [A vérifier] : certains observent que Googlebot ignore parfois les directives ultra-spécifiques si elles contredisent des signaux forts dans robots.txt ou la Search Console.
Dans quels cas cette règle ne s'applique-t-elle pas comme prévu ?
Attention aux balises X-Robots-Tag en HTTP headers : elles peuvent entrer en conflit avec les meta robots si elles ne ciblent pas les mêmes bots. Si ton serveur envoie X-Robots-Tag: noindex pour tous les bots et que tu mets une meta googlebot-news: index, follow, le header l'emporte souvent selon les observations.
Autre cas problématique : les pages rendues côté client (JavaScript). Si la balise meta n'est injectée qu'après le rendu, certains bots peuvent ne pas la voir — et là, la directive générique ou l'absence de directive prévaut. Teste toujours avec l'outil d'inspection d'URL pour vérifier ce que Googlebot voit réellement.
Impact pratique et recommandations
Que faut-il faire concrètement pour exploiter cette granularité ?
Identifie d'abord les sections de ton site qui nécessitent un traitement différencié selon les verticales Google. Typiquement : contenus éditoriaux pour News, fiches produits pour Shopping, galeries pour Images.
Ensuite, implémente les balises meta avec les bons identifiants. Exemple pour exclure une page de News uniquement : <meta name="googlebot-news" content="noindex"> + <meta name="robots" content="index, follow">. Si tu gères des milliers de pages, centralise cette logique dans tes templates ou ton CMS pour éviter les erreurs manuelles.
Quelles erreurs éviter lors de l'implémentation ?
Erreur classique : multiplier les balises sans cohérence. Trois balises meta robots avec des directives qui se contredisent, c'est la porte ouverte aux bugs. Définis une stratégie claire : quelle verticale pour quelle section, et documente-la.
Autre piège : oublier que robots.txt bloque le crawl avant même la lecture des meta. Si tu bloques /news/ dans robots.txt pour Googlebot-News, la balise meta ne sera jamais lue. La logique de blocage doit être cohérente entre robots.txt (accès) et meta robots (indexation).
- Cartographie les sections de ton site et leur pertinence par verticale Google (News, Images, Shopping, etc.)
- Utilise les identifiants exacts documentés par Google (googlebot-news, googlebot-images, etc.) — vérifie la casse
- Teste chaque implémentation avec l'outil d'inspection d'URL de Search Console pour valider ce que Googlebot voit
- Documente ta stratégie de ciblage dans un tableau de bord ou un wiki interne pour éviter les incohérences futures
- Surveille l'indexation réelle via les rapports de couverture Search Console, filtrés par type de contenu si possible
- Évite les conflits entre robots.txt, meta robots et X-Robots-Tag — privilégie une source unique de vérité par directive
Comment vérifier que le ciblage fonctionne correctement ?
Le moyen le plus fiable : Search Console, onglet Couverture. Si une page est exclue de News mais indexée dans Search, tu verras la différence dans les rapports. Pour News spécifiquement, vérifie aussi le rapport "Performances sur Google Actualités" si ton site est éligible.
Autre méthode : site:tonsite.com sur Google Search classique vs. recherche directe dans Google News. Si une URL apparaît dans l'un et pas dans l'autre, ton ciblage fonctionne. Mais attention, ce n'est pas instantané — laisse quelques jours à Googlebot pour recrawler après modification.
Le ciblage spécifique de bots via la balise meta robots offre un contrôle chirurgical de l'indexation par verticale. C'est particulièrement puissant pour les sites média, e-commerce ou mixtes qui jouent sur plusieurs tableaux Google.
L'implémentation demande rigueur et cohérence — une stratégie documentée, des tests systématiques, et une surveillance continue via Search Console. Ces optimisations techniques peuvent rapidement devenir complexes à grande échelle, surtout si ton architecture mélange rendu côté serveur, JavaScript et multiples templates. Dans ce cas, l'accompagnement d'une agence SEO spécialisée peut s'avérer précieux pour éviter les faux pas et maximiser l'impact de cette granularité.
❓ Questions frequentes
Peut-on cumuler plusieurs balises meta robots avec des cibles différentes sur une même page ?
Si je bloque Googlebot-News dans robots.txt, la balise meta googlebot-news sera-t-elle quand même lue ?
Les directives spécifiques fonctionnent-elles aussi avec X-Robots-Tag en HTTP headers ?
Que se passe-t-il si j'utilise un identifiant de bot qui n'existe pas, comme 'googlebot-toto' ?
Est-ce que cette approche fonctionne avec Bing ou d'autres moteurs de recherche ?
🎥 De la même vidéo 12
Autres enseignements SEO extraits de cette même vidéo Google Search Central · publiée le 04/12/2024
🎥 Voir la vidéo complète sur YouTube →
💬 Commentaires (0)
Soyez le premier à commenter.