Declaration officielle
Autres déclarations de cette vidéo 12 ▾
- □ La balise meta robots noindex suffit-elle vraiment à empêcher l'indexation d'une page ?
- □ Peut-on vraiment piloter Googlebot News et Googlebot Search avec des balises meta robots distinctes ?
- □ Peut-on vraiment empiler plusieurs directives meta robots dans une seule balise ?
- □ L'en-tête HTTP X-Robots peut-il remplacer la balise meta robots ?
- □ Où faut-il vraiment placer le fichier robots.txt pour qu'il soit pris en compte ?
- □ Faut-il gérer un robots.txt distinct pour chaque sous-domaine ?
- □ Faut-il utiliser les wildcards dans robots.txt pour mieux contrôler son crawl ?
- □ Faut-il vraiment déclarer son sitemap XML dans le fichier robots.txt ?
- □ Pourquoi ne faut-il jamais combiner robots.txt et meta noindex sur la même page ?
- □ Pourquoi robots.txt empêche-t-il Google de désindexer vos pages ?
- □ Robots.txt bloque-t-il vraiment l'indexation de vos pages ?
- □ Le rapport robots.txt de Google Search Console change-t-il vraiment la donne pour le crawl ?
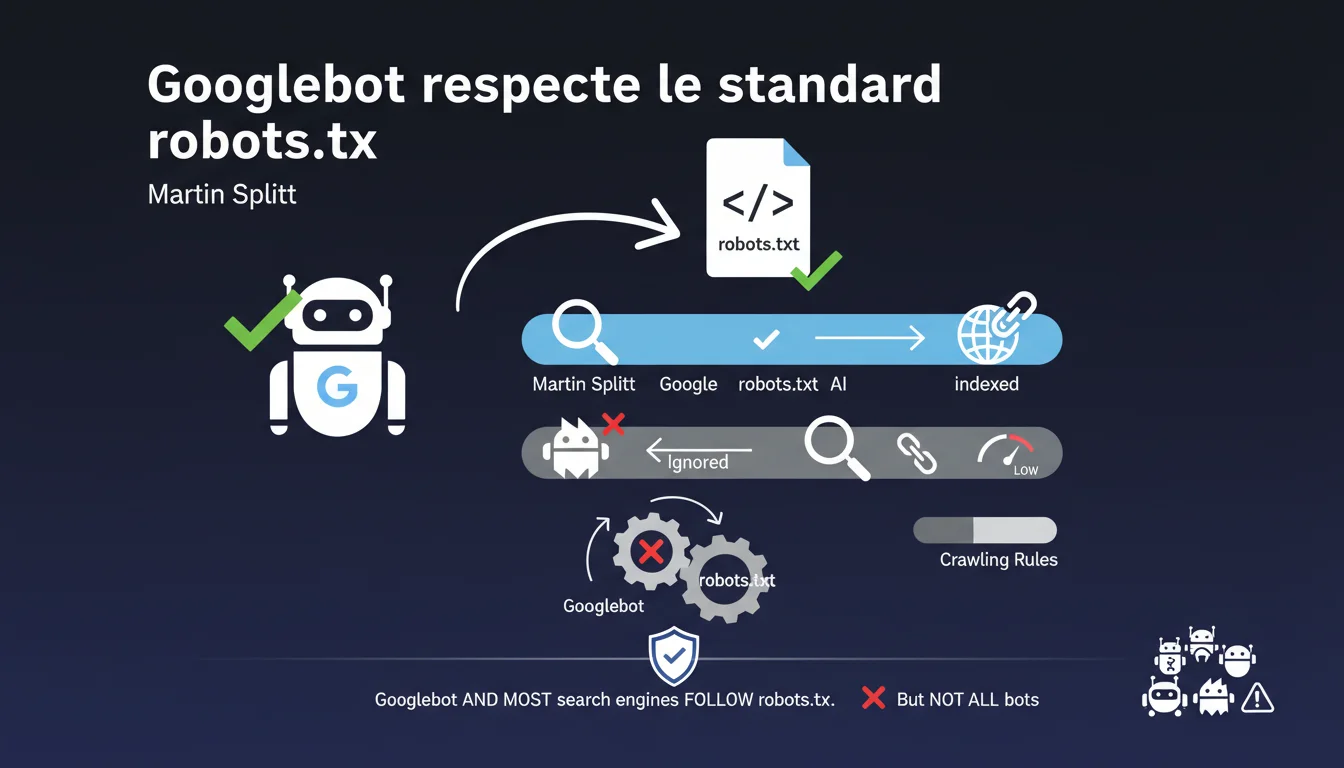
Googlebot et la majorité des moteurs de recherche respectent les directives du fichier robots.txt, mais tous les bots présents sur le web ne s'y conforment pas. Cette clarification de Martin Splitt rappelle qu'un robots.txt n'est pas une sécurité absolue contre le crawl indésirable — c'est une convention, pas un verrou technique.
Ce qu'il faut comprendre
Qu'est-ce que Google affirme exactement ici ?
Google confirme que Googlebot suit les règles définies dans le robots.txt, tout comme la plupart des moteurs de recherche légitimes. C'est une convention largement adoptée par les acteurs sérieux du web.
Mais la nuance est capitale : tous les bots ne respectent pas cette convention. Certains robots — malveillants, scrappeurs agressifs, ou simplement mal configurés — ignorent purement et simplement ce fichier. Le robots.txt n'est pas un mur infranchissable, c'est un panneau "accès interdit" que seuls les acteurs de bonne foi respectent.
Pourquoi cette distinction est-elle importante en SEO ?
Parce que beaucoup de praticiens utilisent encore le robots.txt comme outil de sécurité ou de masquage de contenu sensible. Grosse erreur. Si vous bloquez une URL via robots.txt, elle peut quand même être indexée par Google si elle reçoit des backlinks (sans snippet, certes, mais indexée).
Et surtout, un bot malveillant se moque éperdument de votre Disallow. Si votre objectif est de protéger du contenu, le robots.txt n'est pas la solution. Il faut passer par une authentification serveur, un noindex, ou un blocage IP.
Quels sont les standards du fichier robots.txt ?
Le robots.txt suit une syntaxe standardisée reconnue par la plupart des moteurs. User-agent, Disallow, Allow, Crawl-delay (bien que Google ne le supporte pas), Sitemap… Ces directives sont claires et documentées.
Google a même publié une RFC pour formaliser ce standard. Mais encore une fois, un standard n'est qu'une recommandation. Il n'y a aucune obligation technique pour un bot de le respecter — c'est une question d'éthique et de réputation.
- Googlebot respecte le robots.txt — c'est confirmé officiellement
- La plupart des moteurs légitimes (Bing, Yandex, Baidu) font de même
- Les bots malveillants ou agressifs ignorent souvent ces directives
- Le robots.txt n'est pas un outil de sécurité — c'est un guide de crawl
- Une URL bloquée par robots.txt peut quand même être indexée si elle reçoit des liens externes
Avis d'un expert SEO
Cette déclaration est-elle cohérente avec les pratiques observées sur le terrain ?
Oui, totalement. Google respecte scrupuleusement le robots.txt — j'ai pu le vérifier sur des centaines d'audits. Quand une directive Disallow est bien écrite, Googlebot ne crawle pas les URLs concernées. Les logs serveur le confirment systématiquement.
En revanche, le problème vient des erreurs de syntaxe que je vois encore trop souvent. Un espace mal placé, un slash oublié, un wildcard mal utilisé… et la directive ne fonctionne plus. Google suit le robots.txt, mais si votre fichier est mal écrit, vous ne pouvez vous en prendre qu'à vous-même.
Quelles nuances faut-il apporter à cette affirmation ?
Première nuance : robots.txt ne garantit pas la non-indexation. Google peut indexer une URL bloquée par robots.txt si elle reçoit des backlinks. L'URL apparaîtra dans les SERPs avec une description générique du type "Aucune information disponible". Si vous voulez vraiment empêcher l'indexation, utilisez une balise noindex.
Deuxième nuance : le robots.txt est public. N'importe qui peut lire votre fichier et découvrir les zones que vous avez choisi de bloquer. C'est d'ailleurs un réflexe classique en audit SEO ou en reconnaissance technique — aller lire le robots.txt pour repérer les URLs sensibles ou les structures cachées. [A vérifier] si vous pensez que bloquer un répertoire /admin/ dans le robots.txt le rend invisible… vous faites exactement l'inverse.
Dans quels cas cette règle ne s'applique-t-elle pas ?
Le robots.txt est respecté par les crawlers qui se déclarent honnêtement. Mais un bot peut mentir sur son User-Agent. Certains se font passer pour Googlebot alors qu'ils ne le sont pas — d'où l'importance de vérifier les IPs inverses si vous avez des doutes.
Autre cas : les scrappeurs professionnels ou les bots de concurrents qui analysent votre contenu. Ils n'ont aucune raison de respecter votre robots.txt, et ils ne le font généralement pas. La seule défense efficace dans ce cas : un blocage au niveau serveur (rate limiting, WAF, captcha…).
Impact pratique et recommandations
Que faut-il faire concrètement avec son fichier robots.txt ?
D'abord, vérifiez la syntaxe de votre robots.txt. Utilisez l'outil de test dans la Google Search Console pour valider que vos directives sont correctement interprétées. Une erreur de syntaxe passe souvent inaperçue… jusqu'au jour où vous réalisez que Googlebot crawle des milliers d'URLs que vous pensiez avoir bloquées.
Ensuite, ne bloquez que ce qui doit l'être. Trop de sites bloquent des répertoires entiers par précaution, sans réelle nécessité. Résultat : du contenu légitime n'est pas crawlé, le crawl budget est mal utilisé, et l'indexation est sous-optimale. Soyez chirurgical, pas paranoïaque.
Quelles erreurs éviter absolument ?
Ne JAMAIS utiliser robots.txt pour masquer du contenu sensible. Ce n'est pas un outil de sécurité. Si vous avez des données confidentielles, mettez-les derrière une authentification serveur (HTTP auth, login requis…). Le robots.txt est lisible par n'importe qui.
Autre erreur classique : bloquer des ressources critiques (CSS, JS, images) pensant économiser du crawl budget. Google a besoin de ces fichiers pour rendre vos pages. Un blocage ici peut empêcher l'indexation correcte de votre contenu, surtout si vous utilisez du JavaScript pour afficher des éléments clés.
Comment vérifier que mon robots.txt fonctionne comme prévu ?
Consultez vos logs serveur. C'est la seule source de vérité. Vous verrez exactement quelles URLs Googlebot tente de crawler, et si vos directives sont respectées. Si vous constatez que des URLs bloquées sont quand même crawlées, il y a probablement une erreur de syntaxe.
Utilisez aussi la Search Console : section Couverture, puis filtrez par "Exclues par le fichier robots.txt". Vous verrez la liste des URLs que Google a détectées mais n'a pas crawlées à cause de votre robots.txt. Vérifiez que cette liste correspond bien à votre intention.
- Validez la syntaxe de votre robots.txt avec l'outil Google Search Console
- Ne bloquez jamais CSS, JavaScript ou images critiques pour le rendering
- N'utilisez pas robots.txt pour masquer du contenu sensible — préférez une authentification serveur
- Analysez vos logs pour vérifier que Googlebot respecte bien vos directives
- Documentez vos choix de blocage pour éviter les erreurs lors des mises à jour
- Révisez votre robots.txt régulièrement, surtout après une refonte ou migration
❓ Questions frequentes
Un robots.txt peut-il empêcher l'indexation d'une page ?
Tous les moteurs de recherche respectent-ils le robots.txt ?
Peut-on bloquer des ressources CSS ou JS avec robots.txt ?
Comment vérifier que mon robots.txt fonctionne correctement ?
Le robots.txt est-il un fichier confidentiel ?
🎥 De la même vidéo 12
Autres enseignements SEO extraits de cette même vidéo Google Search Central · publiée le 04/12/2024
🎥 Voir la vidéo complète sur YouTube →
💬 Commentaires (0)
Soyez le premier à commenter.