Declaration officielle
Autres déclarations de cette vidéo 12 ▾
- □ La balise meta robots noindex suffit-elle vraiment à empêcher l'indexation d'une page ?
- □ Peut-on vraiment piloter Googlebot News et Googlebot Search avec des balises meta robots distinctes ?
- □ Peut-on vraiment empiler plusieurs directives meta robots dans une seule balise ?
- □ L'en-tête HTTP X-Robots peut-il remplacer la balise meta robots ?
- □ Où faut-il vraiment placer le fichier robots.txt pour qu'il soit pris en compte ?
- □ Le fichier robots.txt est-il vraiment respecté par tous les moteurs de recherche ?
- □ Faut-il utiliser les wildcards dans robots.txt pour mieux contrôler son crawl ?
- □ Faut-il vraiment déclarer son sitemap XML dans le fichier robots.txt ?
- □ Pourquoi ne faut-il jamais combiner robots.txt et meta noindex sur la même page ?
- □ Pourquoi robots.txt empêche-t-il Google de désindexer vos pages ?
- □ Robots.txt bloque-t-il vraiment l'indexation de vos pages ?
- □ Le rapport robots.txt de Google Search Console change-t-il vraiment la donne pour le crawl ?
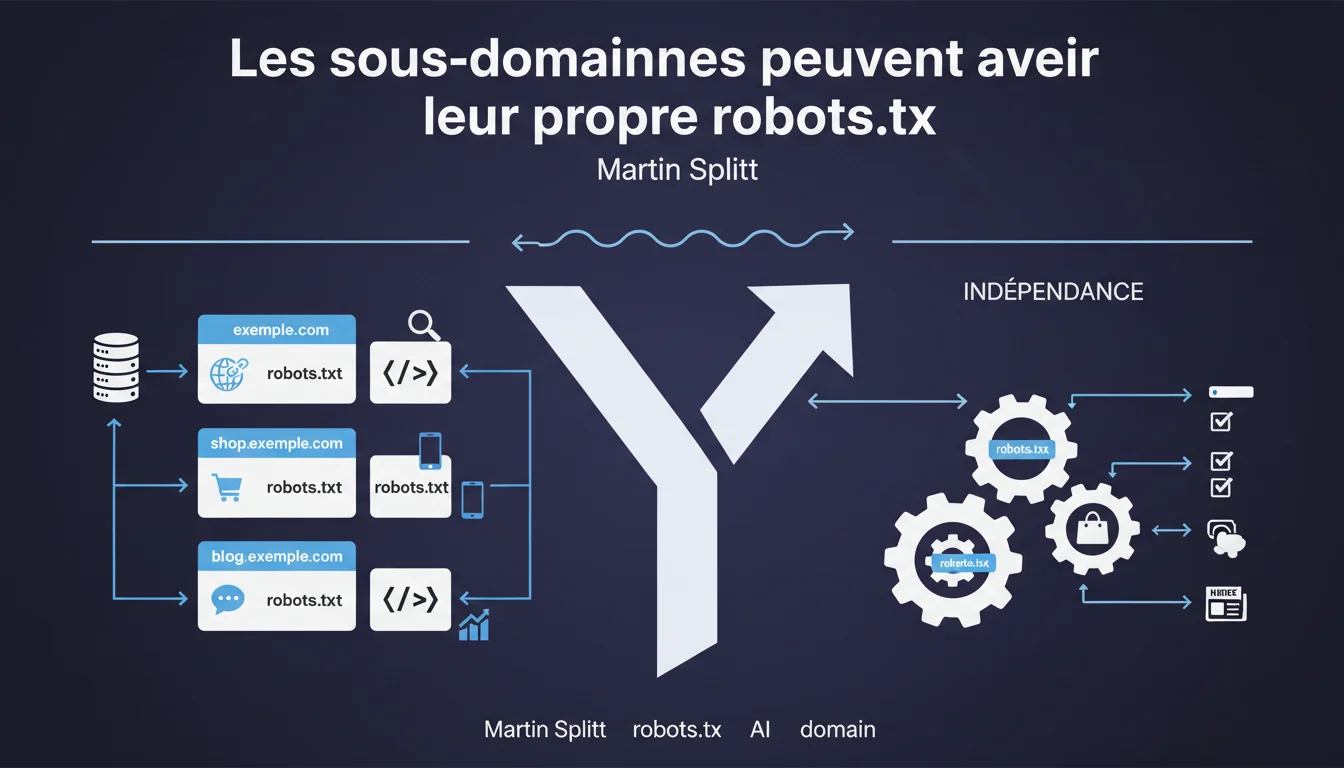
Chaque sous-domaine dispose de son propre fichier robots.txt, totalement indépendant du domaine principal. Un robots.txt placé sur shop.exemple.com n'hérite d'aucune directive du robots.txt de exemple.com. Cette séparation implique une gestion individualisée des directives de crawl pour chaque sous-domaine actif.
Ce qu'il faut comprendre
Les sous-domaines sont-ils vraiment des entités distinctes pour Google ?
Google traite chaque sous-domaine comme un hôte indépendant. Contrairement aux répertoires (exemple.com/shop/) qui héritent du robots.txt racine, un sous-domaine (shop.exemple.com) est considéré comme un site à part entière.
Cette distinction n'est pas qu'une subtilité technique. Elle impacte directement la manière dont Googlebot crawle et indexe vos contenus. Un robots.txt sur www.exemple.com ne s'applique pas à blog.exemple.com, même s'ils appartiennent au même propriétaire.
Concrètement, comment ça fonctionne pour Googlebot ?
Lorsque Googlebot rencontre une URL sur un sous-domaine, il cherche le fichier robots.txt à la racine de ce sous-domaine spécifique. Si shop.exemple.com/robots.txt existe, il applique ses directives. Si ce fichier est absent ou renvoie une erreur 404, Googlebot considère qu'aucune restriction ne s'applique et crawle librement.
Cette logique implique que vous devez dupliquer vos directives de crawl sur chaque sous-domaine qui nécessite des restrictions. Pas d'héritage, pas de cascade. Chaque configuration est isolée.
Pourquoi cette architecture peut poser problème ?
La multiplication des sous-domaines entraîne une fragmentation de la gestion du crawl. Un oubli sur un seul robots.txt peut exposer des zones sensibles (staging, admin, faceted navigation) que vous vouliez bloquer.
Les configurations deviennent rapidement hétérogènes quand plusieurs équipes gèrent des sous-domaines différents. L'absence de centralisation crée des incohérences qui nuisent à l'optimisation du crawl budget.
- Chaque sous-domaine nécessite son propre robots.txt — aucun héritage du domaine principal
- Un robots.txt absent ou en 404 signifie aucune restriction de crawl pour ce sous-domaine
- La gestion doit être systématique et documentée pour éviter les oublis critiques
- Les sous-domaines inactifs ou de test doivent être explicitement bloqués dans leur propre robots.txt
Avis d'un expert SEO
Cette déclaration reflète-t-elle vraiment les observations terrain ?
Oui, et c'est vérifié depuis des années. Les tests montrent systématiquement que Googlebot requête le robots.txt du sous-domaine ciblé, jamais celui du domaine apex. Cette indépendance est documentée dans les logs serveur de tous les sites multi-sous-domaines.
Ce qui est moins connu : cette séparation stricte peut créer des désynchronisations problématiques. J'ai vu des sites bloquer leur blog via blog.exemple.com/robots.txt tout en oubliant de bloquer les paramètres de tri sur shop.exemple.com, ce qui a explosé le crawl budget.
Quand cette logique crée-t-elle des pièges ?
Le premier piège : les redirections entre domaine apex et www. Si vous redirigez exemple.com vers www.exemple.com mais que seul exemple.com/robots.txt contient vos directives, Googlebot applique le robots.txt du sous-domaine final (www.exemple.com/robots.txt), pas celui du domaine source.
Autre cas vicieux : les sous-domaines générés dynamiquement (client1.saas.com, client2.saas.com…). Impossible de maintenir manuellement un robots.txt par client. Il faut une génération automatique, mais combien de plateformes SaaS ont oublié ce détail ? [À vérifier] dans votre architecture si vous êtes dans ce cas.
Est-ce que tous les crawlers respectent cette règle ?
Google, oui. Bing aussi. Mais certains crawlers tiers (notamment des scrapers agressifs) tentent parfois de récupérer le robots.txt du domaine principal quand celui du sous-domaine est absent. Ne comptez pas sur cette faille pour sécuriser vos contenus.
Soyons honnêtes : cette indépendance des robots.txt n'est pas négociable côté Google. Si votre stratégie repose sur un héritage implicite, vous êtes déjà exposé à des problèmes de crawl non maîtrisé.
Impact pratique et recommandations
Que faut-il auditer en priorité sur vos sous-domaines ?
Commencez par lister tous les sous-domaines actifs de votre domaine, y compris ceux que vous avez oubliés (dev, staging, ancien blog, etc.). Un scan DNS ou un outil comme Subfinder vous donnera la liste complète.
Pour chaque sous-domaine actif, vérifiez l'existence et le contenu de son robots.txt. Les sous-domaines de test, de staging ou inactifs doivent impérativement bloquer tous les crawlers via User-agent: * / Disallow: /.
Comment synchroniser les directives entre plusieurs sous-domaines ?
Si plusieurs sous-domaines nécessitent des directives similaires (ex : bloquer /admin, /checkout, /facets), créez un template de robots.txt centralisé et déployez-le via votre CI/CD. Ne comptez jamais sur la saisie manuelle, c'est la garantie d'oublier un sous-domaine critique.
Pour les plateformes SaaS ou multi-sites, automatisez la génération du robots.txt à la création de chaque nouveau sous-domaine. Cette génération doit être partie intégrante du provisioning.
Quelles erreurs bloquent le plus souvent le crawl ?
L'erreur classique : mettre un robots.txt uniquement sur le domaine apex (exemple.com) alors que tout le trafic est redirigé vers www.exemple.com. Googlebot crawle www, donc il cherche www.exemple.com/robots.txt — et si ce dernier est vide ou absent, vos directives ne s'appliquent pas.
Autre erreur fréquente : oublier le robots.txt sur un sous-domaine de blog ou de docs, ce qui laisse Googlebot crawler des milliers de pages de pagination ou de filtres inutiles.
- Lister exhaustivement tous les sous-domaines actifs (y compris dev, staging, archives)
- Vérifier l'existence d'un robots.txt sur chaque sous-domaine via curl ou navigateur
- Bloquer explicitement les sous-domaines de test et inactifs (User-agent: * / Disallow: /)
- Déployer un template robots.txt cohérent sur tous les sous-domaines de production
- Automatiser la génération du robots.txt lors de la création de nouveaux sous-domaines
- Déclarer chaque sous-domaine comme propriété distincte dans Search Console
- Surveiller les logs serveur pour détecter du crawl non maîtrisé sur des sous-domaines oubliés
❓ Questions frequentes
Si je redirige mon domaine principal vers un sous-domaine, quel robots.txt s'applique ?
Puis-je utiliser un wildcard DNS pour servir le même robots.txt à tous les sous-domaines ?
Un sous-domaine sans robots.txt est-il entièrement crawlable par Google ?
Les directives robots.txt d'un sous-domaine impactent-elles le crawl budget du domaine principal ?
Dois-je déclarer chaque sous-domaine séparément dans Search Console ?
🎥 De la même vidéo 12
Autres enseignements SEO extraits de cette même vidéo Google Search Central · publiée le 04/12/2024
🎥 Voir la vidéo complète sur YouTube →
💬 Commentaires (0)
Soyez le premier à commenter.