Declaration officielle
Autres déclarations de cette vidéo 12 ▾
- □ La balise meta robots noindex suffit-elle vraiment à empêcher l'indexation d'une page ?
- □ Peut-on vraiment piloter Googlebot News et Googlebot Search avec des balises meta robots distinctes ?
- □ Peut-on vraiment empiler plusieurs directives meta robots dans une seule balise ?
- □ L'en-tête HTTP X-Robots peut-il remplacer la balise meta robots ?
- □ Faut-il gérer un robots.txt distinct pour chaque sous-domaine ?
- □ Le fichier robots.txt est-il vraiment respecté par tous les moteurs de recherche ?
- □ Faut-il utiliser les wildcards dans robots.txt pour mieux contrôler son crawl ?
- □ Faut-il vraiment déclarer son sitemap XML dans le fichier robots.txt ?
- □ Pourquoi ne faut-il jamais combiner robots.txt et meta noindex sur la même page ?
- □ Pourquoi robots.txt empêche-t-il Google de désindexer vos pages ?
- □ Robots.txt bloque-t-il vraiment l'indexation de vos pages ?
- □ Le rapport robots.txt de Google Search Console change-t-il vraiment la donne pour le crawl ?
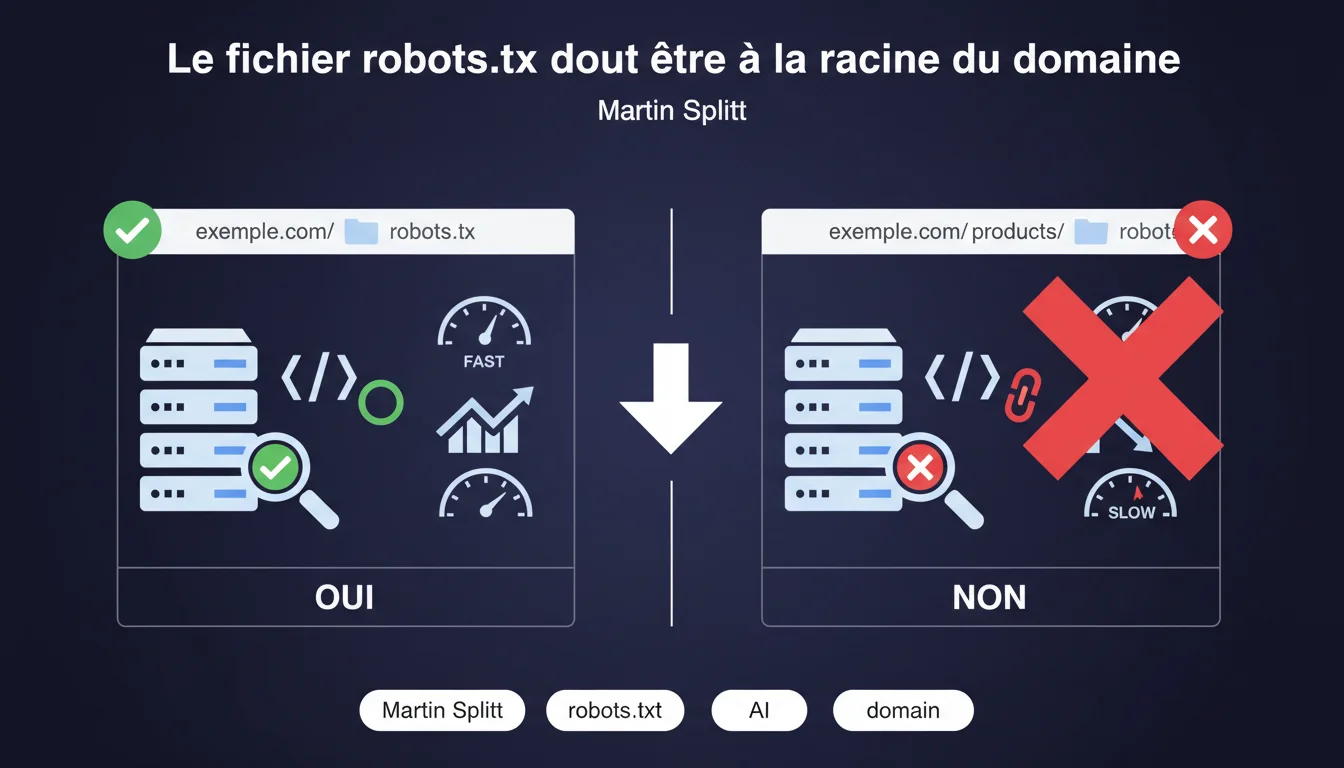
Le fichier robots.txt doit impérativement être à la racine du domaine (exemple.com/robots.txt). Tout autre emplacement, y compris dans un sous-répertoire, rendra le fichier invisible pour les moteurs de recherche. Cette règle technique ne souffre aucune exception.
Ce qu'il faut comprendre
Pourquoi le robots.txt ne peut-il être que sur la racine du domaine ?
Les spécifications du protocole d'exclusion des robots, définies dès 1994, imposent cette contrainte. Lorsqu'un crawler arrive sur un site, il ne cherche le fichier qu'à un seul endroit : la racine du domaine.
Un robots.txt placé dans exemple.com/blog/robots.txt ou exemple.com/fr/robots.txt sera tout simplement ignoré. Googlebot ne scannera jamais ces chemins pour y chercher des directives de crawl.
Cette règle s'applique-t-elle à tous les sous-domaines ?
Chaque sous-domaine est traité comme un domaine distinct. Si vous avez blog.exemple.com, il nécessite son propre fichier robots.txt à blog.exemple.com/robots.txt.
Un robots.txt placé sur exemple.com/robots.txt n'aura strictement aucun effet sur blog.exemple.com. Les deux entités sont totalement indépendantes du point de vue du crawl.
Quelles sont les conséquences d'un mauvais placement ?
Le crawler interprétera l'absence de robots.txt comme une autorisation totale de crawl. Toutes vos directives Disallow seront purement et simplement ignorées.
- Perte de contrôle sur le crawl budget : les sections que vous vouliez bloquer seront explorées
- Risque d'indexation de contenus sensibles : pages de test, paramètres d'URL, environnements de staging
- Gaspillage de ressources serveur : crawl non optimisé sur des zones sans valeur SEO
- Impossibilité de déclarer le sitemap : la directive Sitemap dans robots.txt ne sera pas lue
Avis d'un expert SEO
Cette règle technique est-elle aussi rigide qu'elle en a l'air ?
Oui, sans la moindre marge de manœuvre. Contrairement à d'autres aspects du SEO où Google montre une certaine flexibilité, le placement du robots.txt relève d'une norme protocolaire stricte.
J'ai testé sur dizaines de domaines : un robots.txt mal placé équivaut à son absence pure et simple. Aucune exception, aucun cas particulier où Google irait le chercher ailleurs « par gentillesse ».
Pourquoi cette erreur reste-t-elle fréquente malgré sa simplicité ?
Plusieurs architectures web modernes créent de la confusion. Les sites multilingues avec structure en répertoires (/fr/, /en/) poussent certains développeurs à vouloir des robots.txt distincts par langue — ce qui ne fonctionne pas.
Les plateformes e-commerce avec plusieurs boutiques sous un même domaine génèrent aussi cette erreur. exemple.com/boutique-a/ et exemple.com/boutique-b/ partagent forcément le même robots.txt racine.
Quelles nuances faut-il apporter à cette déclaration ?
La seule subtilité concerne les sous-domaines. Beaucoup confondent répertoire et sous-domaine : exemple.com/mobile/ est un répertoire (même robots.txt), mobile.exemple.com est un sous-domaine (robots.txt distinct nécessaire).
Pour les sites avec architecture complexe — multilangue, multi-pays, multi-catalogues — la gestion devient vite cornélienne. Un seul robots.txt doit gérer l'ensemble des directives, ce qui peut rapidement devenir difficile à maintenir et à auditer.
Impact pratique et recommandations
Comment vérifier que mon robots.txt est correctement placé ?
Le test est immédiat : tapez votredomaine.com/robots.txt dans un navigateur. Si le fichier s'affiche, l'emplacement est correct. Si vous obtenez une 404, le fichier n'existe pas ou est mal placé.
Utilisez également la Search Console dans Paramètres > robots.txt. Google vous indique s'il détecte un fichier et vous permet de tester des URL contre vos directives.
Que faire si mon architecture nécessite des règles différentes par section ?
Toutes vos directives doivent être consolidées dans un unique fichier racine. Structurez-le avec des commentaires clairs pour séparer les blocs par section ou langue.
Si votre besoin de granularité est vraiment important — contrôler différemment le crawl selon les zones du site — la solution passe par des règles conditionnelles côté serveur ou, mieux encore, par l'utilisation de la balise meta robots dans les pages concernées.
Quelles erreurs éviter absolument ?
- Ne jamais créer de robots.txt dans un sous-répertoire en pensant qu'il sera pris en compte
- Ne pas oublier qu'un sous-domaine nécessite son propre fichier robots.txt
- Ne pas confondre disponibilité HTTP (le fichier est accessible) et reconnaissance par les crawlers (seule la racine compte)
- Éviter les redirections 301/302 sur le robots.txt — Google suit la redirection mais c'est une mauvaise pratique qui peut créer des latences
- Vérifier que le fichier renvoie un code 200 et un Content-Type text/plain
❓ Questions frequentes
Puis-je avoir plusieurs fichiers robots.txt sur différentes parties de mon domaine ?
Mon CMS génère automatiquement un robots.txt dans un sous-répertoire, que faire ?
Comment gérer un site multilingue avec un seul robots.txt ?
Un sous-domaine hérite-t-il du robots.txt du domaine principal ?
Que se passe-t-il si je redirige /robots.txt vers un autre emplacement ?
🎥 De la même vidéo 12
Autres enseignements SEO extraits de cette même vidéo Google Search Central · publiée le 04/12/2024
🎥 Voir la vidéo complète sur YouTube →
💬 Commentaires (0)
Soyez le premier à commenter.