Declaration officielle
Autres déclarations de cette vidéo 12 ▾
- □ La balise meta robots noindex suffit-elle vraiment à empêcher l'indexation d'une page ?
- □ Peut-on vraiment piloter Googlebot News et Googlebot Search avec des balises meta robots distinctes ?
- □ Peut-on vraiment empiler plusieurs directives meta robots dans une seule balise ?
- □ Où faut-il vraiment placer le fichier robots.txt pour qu'il soit pris en compte ?
- □ Faut-il gérer un robots.txt distinct pour chaque sous-domaine ?
- □ Le fichier robots.txt est-il vraiment respecté par tous les moteurs de recherche ?
- □ Faut-il utiliser les wildcards dans robots.txt pour mieux contrôler son crawl ?
- □ Faut-il vraiment déclarer son sitemap XML dans le fichier robots.txt ?
- □ Pourquoi ne faut-il jamais combiner robots.txt et meta noindex sur la même page ?
- □ Pourquoi robots.txt empêche-t-il Google de désindexer vos pages ?
- □ Robots.txt bloque-t-il vraiment l'indexation de vos pages ?
- □ Le rapport robots.txt de Google Search Console change-t-il vraiment la donne pour le crawl ?
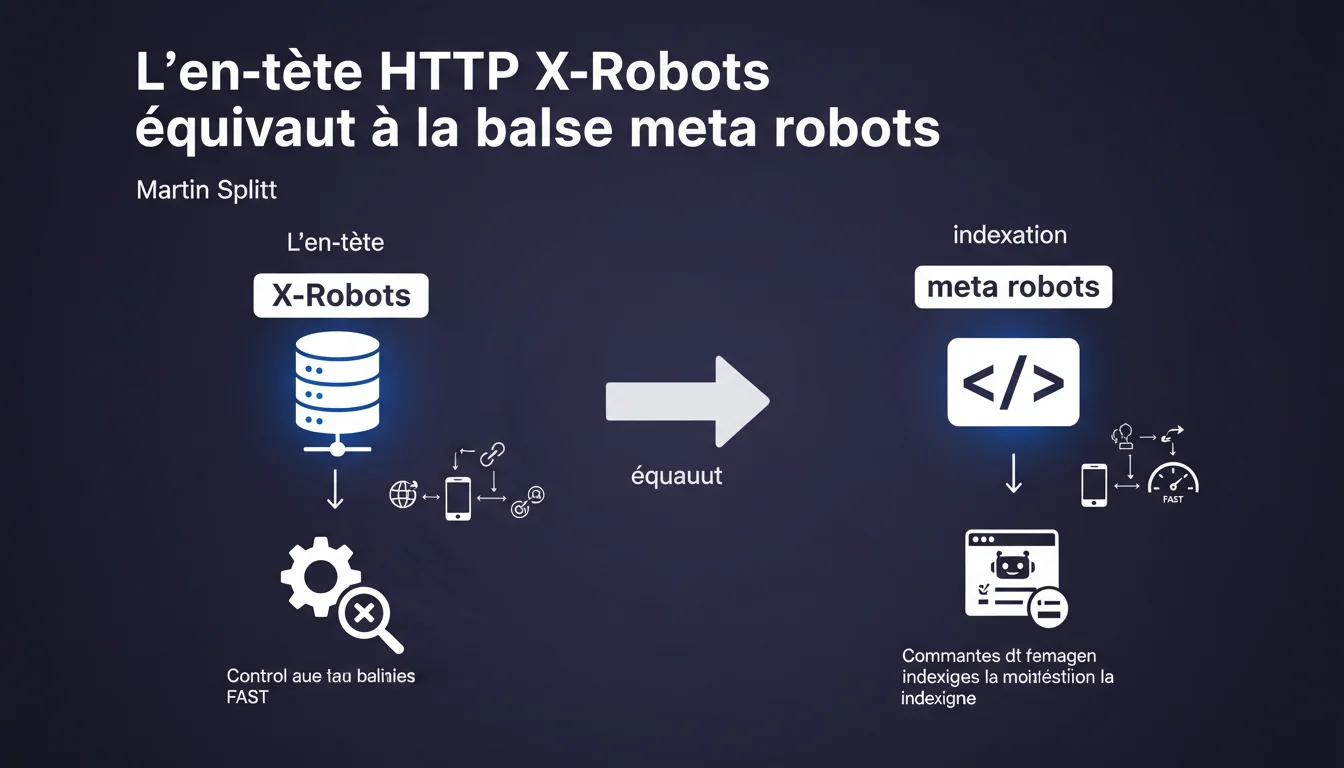
Google confirme que l'en-tête HTTP X-Robots-Tag accepte strictement les mêmes valeurs que la balise meta robots et constitue une alternative valable pour contrôler l'indexation. Cette méthode offre une flexibilité technique intéressante, notamment pour les fichiers non-HTML, mais elle reste moins visible et plus complexe à auditer que son équivalent HTML.
Ce qu'il faut comprendre
Pourquoi Google propose-t-il deux méthodes pour contrôler l'indexation ?
La balise meta robots s'insère dans le <head> d'une page HTML — c'est la méthode classique, visible, facile à vérifier. Mais elle présente une limite : elle ne fonctionne que sur des documents HTML.
L'en-tête HTTP X-Robots-Tag intervient au niveau du serveur, avant même que le navigateur ou Googlebot ne traite le contenu. Il s'applique à n'importe quel type de fichier : PDF, images, vidéos, flux XML. C'est cette portée élargie qui justifie son existence.
Quelles valeurs peut-on utiliser dans X-Robots-Tag ?
Martin Splitt est formel : exactement les mêmes valeurs que la balise meta robots. Donc noindex, nofollow, noarchive, nosnippet, max-snippet, max-image-preview, max-video-preview, unavailable_after.
Concrètement, si vous bloquez l'indexation avec <meta name="robots" content="noindex">, vous obtiendrez le même résultat avec X-Robots-Tag: noindex dans la réponse HTTP. Aucune différence de traitement côté Google.
Dans quels cas cette méthode devient-elle pertinente ?
Trois scénarios principaux se dégagent. D'abord, les fichiers non-HTML — impossible d'y coller une balise meta, donc l'en-tête HTTP est la seule option.
Ensuite, les architectures complexes où modifier le HTML est laborieux ou risqué, mais où ajuster la configuration Apache/Nginx reste simple. Enfin, les cas où vous devez appliquer des règles d'indexation par pattern ou par type de fichier — une ligne de config serveur évite de toucher à des centaines de templates.
- L'en-tête X-Robots-Tag offre la même fonction que la balise meta robots
- Il s'applique à tous les types de fichiers, pas seulement HTML
- Les valeurs acceptées sont strictement identiques
- Le choix entre les deux dépend du contexte technique et de la facilité d'implémentation
Avis d'un expert SEO
Cette déclaration est-elle cohérente avec les observations terrain ?
Oui, sans ambiguïté. Les tests montrent que Googlebot respecte l'en-tête X-Robots-Tag exactement comme la balise meta. Aucun écart de comportement documenté entre les deux méthodes depuis leur mise en place.
Là où ça coince parfois : la détection. Un audit SEO standard scanne le DOM, pas les en-têtes HTTP. Résultat : des sites utilisent X-Robots-Tag pour bloquer l'indexation sans que personne ne s'en aperçoive pendant des mois. La visibilité reste l'avantage numéro un de la balise meta.
Quelles nuances faut-il apporter à cette affirmation ?
Martin Splitt parle d'équivalence stricte, mais il ne mentionne pas la priorité en cas de conflit. Si vous avez noindex en meta ET index en X-Robots-Tag — ou l'inverse —, quelle directive l'emporte ? [A vérifier] Les tests terrain suggèrent que Google applique la directive la plus restrictive, mais aucune documentation officielle ne le confirme explicitement.
Autre point : l'en-tête HTTP peut cibler des user-agents spécifiques avec la syntaxe X-Robots-Tag: googlebot: noindex. Cette granularité n'existe pas dans la balise meta classique — il faut passer par <meta name="googlebot" content="noindex">, ce qui reste moins flexible.
Dans quels cas cette méthode pose-t-elle problème ?
Trois écueils classiques. D'abord, l'auditabilité — difficile de repérer une erreur de config enfouie dans un .htaccess ou un nginx.conf. Les outils SEO standards ne remontent pas ces directives aussi clairement qu'une balise HTML.
Ensuite, la maintenance. Une règle d'en-tête mal fichue peut bloquer l'indexation de centaines de pages sans que personne ne le voie. Avec la balise meta, l'erreur reste localisée à une page ou un template.
Impact pratique et recommandations
Faut-il privilégier l'en-tête HTTP ou la balise meta ?
Ça dépend du contexte. Pour du contenu HTML standard, la balise meta reste plus simple à gérer et à auditer. Pour des fichiers PDF, images ou flux, l'en-tête HTTP est la seule option viable.
Si vous gérez un site avec des milliers de pages générées dynamiquement et que modifier les templates est un cauchemar, une règle serveur ciblée peut économiser du temps. Mais cette économie initiale se paie en complexité de diagnostic plus tard.
Comment vérifier que l'en-tête X-Robots-Tag fonctionne correctement ?
Ouvrez les DevTools de votre navigateur, onglet Network, rechargez la page et inspectez les en-têtes de réponse HTTP. Cherchez X-Robots-Tag dans la liste. Si vous ne le voyez pas, testez avec curl ou un outil comme Screaming Frog qui affiche les en-têtes HTTP dans ses exports.
Vérifiez aussi la Google Search Console. Si des pages disparaissent de l'index sans raison apparente, inspectez les en-têtes HTTP en priorité — c'est souvent la cause invisible.
Quelles erreurs éviter avec cette méthode ?
- Ne jamais mélanger balise meta et en-tête HTTP avec des directives contradictoires — privilégiez une seule méthode par ressource
- Documenter toute règle X-Robots-Tag dans vos configs serveur pour éviter les oublis lors des migrations
- Tester systématiquement après un changement de CDN ou de reverse proxy — ces services peuvent filtrer ou modifier les en-têtes custom
- Utiliser des outils d'audit qui inspectent les en-têtes HTTP, pas seulement le DOM (Screaming Frog, OnCrawl, Botify)
- Pour les fichiers PDF ou images stratégiques, vérifier manuellement que l'en-tête X-Robots-Tag est bien présent et correctement configuré
❓ Questions frequentes
Peut-on utiliser X-Robots-Tag et meta robots en même temps sur une même page ?
L'en-tête X-Robots-Tag fonctionne-t-il pour Bing et les autres moteurs ?
Comment bloquer l'indexation d'un PDF avec X-Robots-Tag sur Apache ?
Les outils d'audit SEO détectent-ils automatiquement l'en-tête X-Robots-Tag ?
Peut-on cibler un moteur spécifique avec X-Robots-Tag ?
🎥 De la même vidéo 12
Autres enseignements SEO extraits de cette même vidéo Google Search Central · publiée le 04/12/2024
🎥 Voir la vidéo complète sur YouTube →
💬 Commentaires (0)
Soyez le premier à commenter.