Declaration officielle
Autres déclarations de cette vidéo 12 ▾
- □ La balise meta robots noindex suffit-elle vraiment à empêcher l'indexation d'une page ?
- □ Peut-on vraiment piloter Googlebot News et Googlebot Search avec des balises meta robots distinctes ?
- □ Peut-on vraiment empiler plusieurs directives meta robots dans une seule balise ?
- □ L'en-tête HTTP X-Robots peut-il remplacer la balise meta robots ?
- □ Où faut-il vraiment placer le fichier robots.txt pour qu'il soit pris en compte ?
- □ Faut-il gérer un robots.txt distinct pour chaque sous-domaine ?
- □ Le fichier robots.txt est-il vraiment respecté par tous les moteurs de recherche ?
- □ Faut-il utiliser les wildcards dans robots.txt pour mieux contrôler son crawl ?
- □ Faut-il vraiment déclarer son sitemap XML dans le fichier robots.txt ?
- □ Pourquoi ne faut-il jamais combiner robots.txt et meta noindex sur la même page ?
- □ Pourquoi robots.txt empêche-t-il Google de désindexer vos pages ?
- □ Le rapport robots.txt de Google Search Console change-t-il vraiment la donne pour le crawl ?
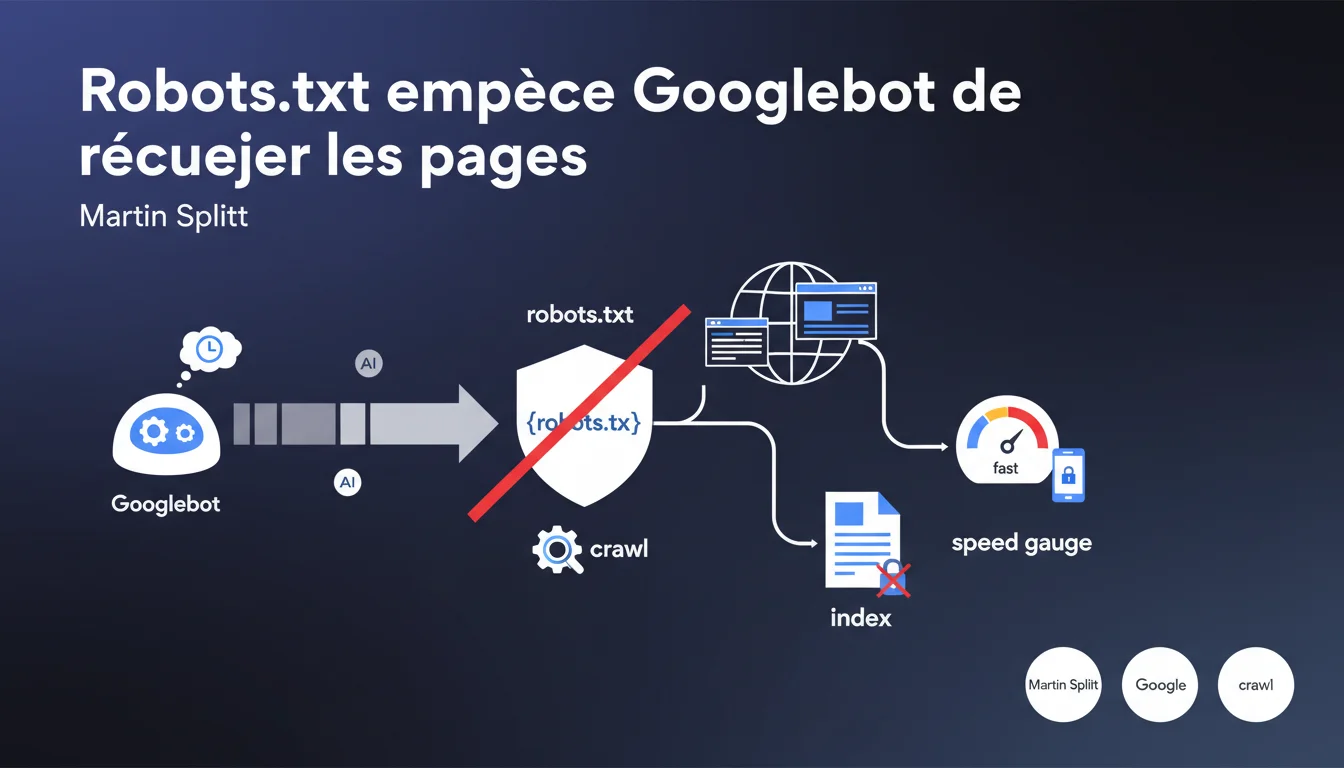
Le robots.txt empêche Googlebot de crawler des pages, mais ne les bloque pas à l'indexation. Google peut très bien indexer une URL sans jamais l'avoir crawlée. Si vous voulez vraiment empêcher l'indexation, c'est la balise noindex qu'il faut utiliser, pas robots.txt.
Ce qu'il faut comprendre
Quelle est la différence entre crawl et indexation ?
Le crawl désigne l'action de Googlebot qui visite une page pour en récupérer le contenu. L'indexation, c'est la décision de Google d'ajouter cette page à son index et de la rendre accessible dans les résultats de recherche.
Bloquer le crawl via robots.txt n'empêche pas Google d'indexer l'URL — surtout si elle dispose de backlinks externes. Google peut indexer une page sans jamais l'avoir visitée, en se basant uniquement sur les ancres de liens pointant vers elle.
Pourquoi cette confusion persiste-t-elle chez tant de praticiens ?
Pendant des années, les SEO ont utilisé robots.txt pour "cacher" des contenus à Google. Ça marchait... jusqu'à ce que Google affine son algorithme et commence à indexer des URLs bloquées au crawl, créant des résultats fantômes dans la SERP.
Le piège est tenace : beaucoup voient "Disallow" dans robots.txt et pensent "interdit d'indexer". Faux. Googlebot obéit au robots.txt pour le crawl, mais l'indexation suit d'autres règles.
Quand utiliser robots.txt alors ?
Le fichier robots.txt sert à optimiser le crawl budget en évitant que Googlebot ne gaspille du temps sur des ressources inutiles : résultats de recherche interne, paramètres d'URL multiples, pages de pagination infinies, assets CSS/JS volumineux.
C'est un outil de gestion technique, pas un bouclier anti-indexation. Si vous voulez vraiment qu'une page disparaisse de l'index, c'est noindex qu'il faut utiliser — et pour ça, Googlebot doit pouvoir crawler la page pour lire la directive.
- Robots.txt : gère le crawl, pas l'indexation
- Noindex : empêche l'indexation (mais nécessite que la page soit crawlée)
- Bloquer au crawl une page avec backlinks = risque d'indexation fantôme
- Robots.txt est utile pour le crawl budget, pas pour masquer du contenu
Avis d'un expert SEO
Cette déclaration est-elle cohérente avec les observations terrain ?
Oui, complètement. On voit régulièrement des URLs bloquées en robots.txt apparaître dans les SERP avec la mention "Aucune information disponible pour cette page". Classique sur les sites e-commerce qui bloquent leurs filtres ou leurs pages de connexion.
Le problème, c'est que ces pages fantômes consomment du crawl budget et diluent l'autorité du site. Google perd du temps à réévaluer des URLs qu'il ne peut pas crawler, tout en les maintenant dans l'index par précaution.
Quelles nuances faut-il apporter dans la pratique ?
Martin Splitt dit que robots.txt "évite que Googlebot ne passe du temps sur certaines ressources". Soyons honnêtes : cette formulation est trompeuse. Si vous bloquez une URL avec 50 backlinks, Google va quand même revenir vérifier périodiquement si le robots.txt a changé.
Le vrai gain de crawl budget est marginal sur les petits sites. Sur un site de 500 pages, bloquer 20 URLs en robots.txt change peu de chose. Sur un site de 500 000 pages avec 200 000 URLs paramétrées inutiles — là, oui, robots.txt devient stratégique.
[A vérifier] : Google ne documente jamais précisément combien de temps Googlebot "économise" en bloquant des ressources. Les gains réels varient énormément selon l'architecture du site et la fréquence de crawl naturelle.
Dans quels cas cette règle ne s'applique-t-elle pas ?
Si vous bloquez une page au crawl ET qu'elle n'a aucun backlink externe, Google finira par la désindexer — mais ça prend du temps. Parfois des mois. Ce n'est pas une méthode fiable pour nettoyer un index.
Autre piège : bloquer une page en robots.txt puis ajouter noindex dedans... ne sert à rien. Googlebot ne crawlera jamais la page pour lire la directive noindex. Résultat : l'URL reste indexée indéfiniment.
Impact pratique et recommandations
Que faut-il faire concrètement pour contrôler l'indexation ?
Première règle : séparez crawl et indexation dans votre stratégie. Si vous voulez qu'une page disparaisse de Google, utilisez la balise noindex en HTTP header ou en meta tag. Laissez Googlebot la crawler pour lire cette directive.
Une fois la page désindexée (vérifiez dans Search Console), vous pouvez décider de bloquer le crawl en robots.txt pour économiser du crawl budget. Mais jamais dans l'autre sens.
Quelles erreurs éviter absolument ?
Erreur classique n°1 : bloquer en robots.txt des pages sensibles (admin, compte utilisateur) en pensant que ça les cache. Si elles ont des backlinks ou apparaissent dans un sitemap, elles seront indexées quand même.
Erreur n°2 : bloquer des ressources CSS/JS critiques au rendu. Google a besoin de ces fichiers pour évaluer correctement la page — les bloquer peut nuire au crawl ET au référencement.
Erreur n°3 : sur-optimiser le robots.txt en bloquant trop d'URLs. Sur un site moyen, un robots.txt trop restrictif fait plus de mal que de bien. Laissez Google découvrir naturellement votre structure, puis affinez si nécessaire.
Comment vérifier que votre configuration est correcte ?
- Auditez Search Console : cherchez des URLs indexées avec "Bloquée par robots.txt" — c'est le signe d'une config bancale
- Testez votre robots.txt avec l'outil de test de Google (dans Search Console, section Robots.txt)
- Vérifiez que les pages noindex sont bien crawlables (pas bloquées en robots.txt)
- Listez vos pages bloquées en robots.txt et vérifiez qu'elles n'ont pas de backlinks externes via Ahrefs/Semrush
- Utilisez site:votredomaine.com dans Google pour repérer les URLs fantômes indexées sans contenu
- Documentez votre stratégie crawl/indexation pour éviter les incohérences lors des mises à jour
La distinction entre crawl et indexation est fondamentale, mais elle reste contre-intuitive pour beaucoup de praticiens. Robots.txt gère le premier, noindex gère le second — mélanger les deux crée des problèmes difficiles à diagnostiquer.
Sur des architectures complexes avec des milliers de pages, ces optimisations deviennent vite techniques et nécessitent une analyse fine du crawl budget, de la structure des liens internes et des directives d'indexation. Si votre site dépasse les quelques centaines de pages ou si vous constatez des URLs fantômes dans l'index, faire appel à une agence SEO spécialisée peut vous faire gagner un temps précieux et éviter des erreurs coûteuses. Un accompagnement personnalisé permet d'auditer précisément votre configuration et d'ajuster robots.txt, noindex et sitemap de manière cohérente.
❓ Questions frequentes
Peut-on utiliser robots.txt pour cacher du duplicate content à Google ?
Si je bloque une page en robots.txt, combien de temps avant qu'elle sorte de l'index ?
Faut-il bloquer les filtres et facettes d'un site e-commerce en robots.txt ?
Googlebot peut-il ignorer le robots.txt dans certains cas ?
Comment désindexer rapidement une page déjà bloquée en robots.txt ?
🎥 De la même vidéo 12
Autres enseignements SEO extraits de cette même vidéo Google Search Central · publiée le 04/12/2024
🎥 Voir la vidéo complète sur YouTube →
💬 Commentaires (0)
Soyez le premier à commenter.