Declaration officielle
Autres déclarations de cette vidéo 12 ▾
- □ Peut-on vraiment piloter Googlebot News et Googlebot Search avec des balises meta robots distinctes ?
- □ Peut-on vraiment empiler plusieurs directives meta robots dans une seule balise ?
- □ L'en-tête HTTP X-Robots peut-il remplacer la balise meta robots ?
- □ Où faut-il vraiment placer le fichier robots.txt pour qu'il soit pris en compte ?
- □ Faut-il gérer un robots.txt distinct pour chaque sous-domaine ?
- □ Le fichier robots.txt est-il vraiment respecté par tous les moteurs de recherche ?
- □ Faut-il utiliser les wildcards dans robots.txt pour mieux contrôler son crawl ?
- □ Faut-il vraiment déclarer son sitemap XML dans le fichier robots.txt ?
- □ Pourquoi ne faut-il jamais combiner robots.txt et meta noindex sur la même page ?
- □ Pourquoi robots.txt empêche-t-il Google de désindexer vos pages ?
- □ Robots.txt bloque-t-il vraiment l'indexation de vos pages ?
- □ Le rapport robots.txt de Google Search Console change-t-il vraiment la donne pour le crawl ?
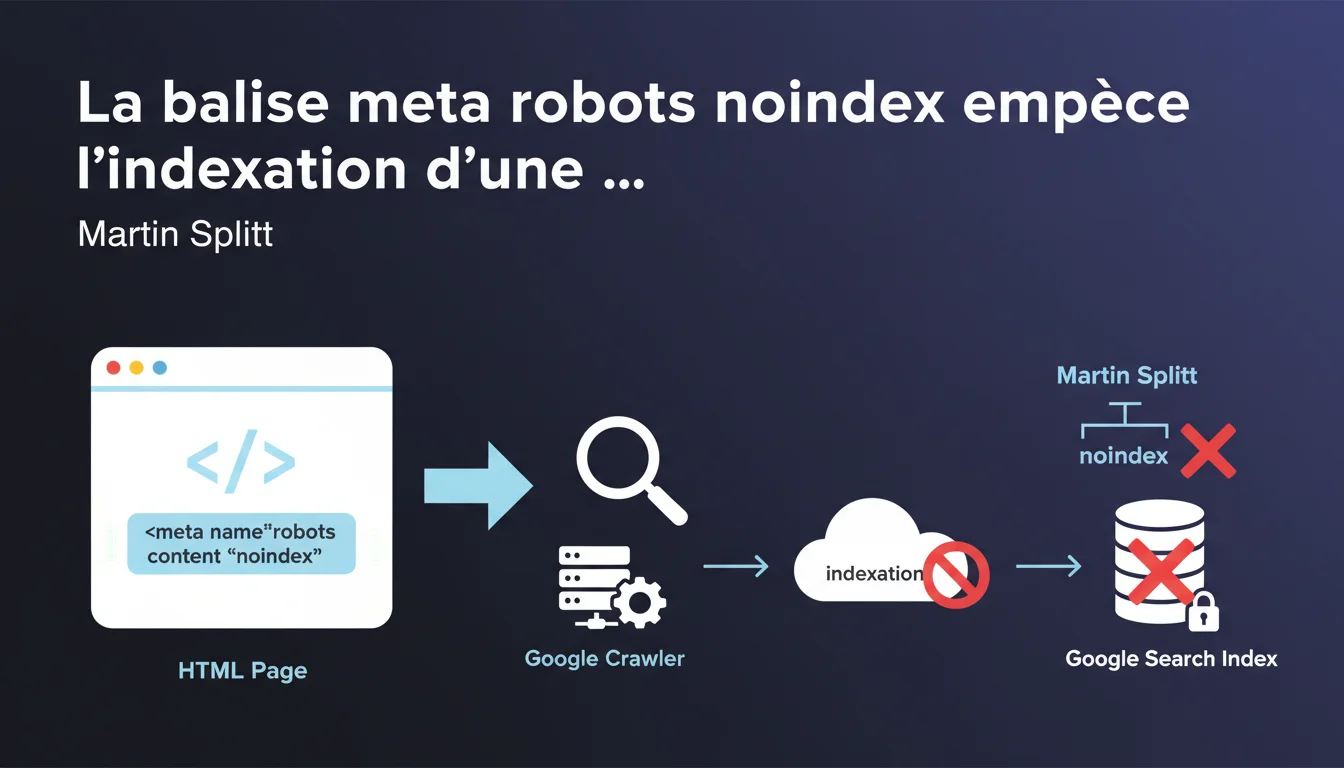
Google confirme que la balise meta robots noindex placée dans le <head> d'une page HTML empêche son indexation dans les résultats de recherche. Cette directive reste la méthode privilégiée pour exclure des pages de l'index, à condition que Google puisse crawler la page pour lire cette instruction.
Ce qu'il faut comprendre
Pourquoi cette balise reste-t-elle le standard de déindexation ?
La balise meta robots noindex fonctionne comme une instruction explicite adressée aux moteurs de recherche lors du crawl. Contrairement au robots.txt qui bloque l'accès en amont, cette directive laisse Google accéder au contenu tout en lui demandant de ne pas l'indexer.
Cette approche présente un avantage décisif : Google peut suivre les liens sortants de la page et transmettre le PageRank, ce qui n'est pas possible avec un blocage robots.txt. La page reste dans le graphe de liens mais disparaît des SERP.
Quelles sont les conditions pour que cette balise fonctionne ?
Google doit pouvoir crawler la page pour lire la balise. Si vous bloquez l'URL dans le robots.txt, le bot ne verra jamais l'instruction noindex et la page pourrait rester indexée avec un snippet générique.
La balise doit être placée dans la section <head> du HTML, avant tout JavaScript qui pourrait retarder son interprétation. Google la détecte généralement au premier crawl, mais le retrait de l'index peut prendre quelques jours.
Cette méthode couvre-t-elle tous les cas de figure ?
Non. La balise meta robots ne protège pas contre l'indexation si d'autres sites créent des backlinks massifs vers l'URL avant que Google ne la crawle. Dans ce cas, l'URL peut apparaître dans l'index avec la mention « Aucune information disponible ».
Pour les sites générés côté client en JavaScript, vérifiez que Google exécute bien le JS et voit la balise. Utilisez l'outil d'inspection d'URL de la Search Console pour confirmer que le rendu final inclut le noindex.
- La balise meta robots noindex empêche l'indexation si Google peut crawler la page
- Ne bloquez jamais une URL noindexée dans le robots.txt, sinon Google ne lit pas la directive
- Le retrait de l'index prend quelques jours après le premier crawl avec la balise
- Les backlinks externes peuvent forcer une indexation partielle avant le crawl
- Vérifiez le rendu JavaScript pour les sites dynamiques
Avis d'un expert SEO
Cette déclaration est-elle alignée avec les observations terrain ?
Oui, dans 95% des cas. La balise noindex fonctionne de manière fiable quand elle est correctement implémentée. Les échecs surviennent généralement à cause d'erreurs de configuration : blocage robots.txt simultané, balise placée après le <body>, ou JavaScript qui l'injecte trop tard.
Un piège fréquent : les sites qui basculent une page de « index » à « noindex » puis la bloquent dans le robots.txt avant que Google n'ait recrawlé. Résultat : l'URL reste dans l'index indéfiniment parce que Google ne peut plus lire l'instruction de déindexation.
Quelles nuances Martin Splitt ne mentionne-t-il pas ici ?
Il ne parle pas du délai de propagation. Entre le moment où vous ajoutez la balise et le retrait effectif de l'index, il peut s'écouler plusieurs semaines pour des pages rarement crawlées. La Search Console reste floue sur ce timing.
Autre point : Google respecte noindex, mais d'autres moteurs comme Bing ou Yandex peuvent avoir des délais différents. Si votre problématique couvre plusieurs moteurs, il faut tester chacun séparément. [À vérifier] selon les retours Bing Webmaster Tools.
Dans quels cas cette règle ne suffit-elle pas ?
Pour les urgences. Si une page confidentielle ou dupliquée apparaît dans l'index et que vous devez la retirer immédiatement, la balise noindex ne suffit pas — elle demande un recrawl. Dans ce cas, utilisez l'outil de suppression d'URL de la Search Console pour un retrait temporaire en 24-48h.
Pour les facettes e-commerce ou les archives paginées, combiner noindex avec canonical peut créer des signaux contradictoires. Google suit généralement le canonical en priorité, donc si vous canonicalisez vers une page indexable, le noindex peut être ignoré.
Impact pratique et recommandations
Que faut-il faire concrètement pour bien implémenter le noindex ?
Placez la balise <meta name="robots" content="noindex"> dans le <head> de vos pages à exclure. Vérifiez qu'elle apparaît dans le code source brut, avant toute injection JavaScript tardive.
Testez avec l'outil d'inspection d'URL de la Search Console. Si la balise n'apparaît pas dans le rendu HTML final, Google ne la verra pas. Corrigez votre implémentation JS ou passez par un rendu côté serveur.
Ne combinez jamais noindex et blocage robots.txt sur la même URL. Si vous devez absolument bloquer le crawl (pour économiser du budget), acceptez que la page puisse rester dans l'index avec un snippet vide.
Quelles erreurs éviter dans la gestion du noindex ?
Ne retirez pas la balise trop vite. Si vous déindexez une page puis la réindexez 48h plus tard, Google peut la considérer comme instable et ralentir son crawl. Laissez au moins 2 semaines avant de changer d'avis.
Évitez les noindex en cascade sur des sections entières sans stratégie claire. Chaque page noindexée perd sa capacité à ranker mais continue de consommer du crawl budget. Mieux vaut parfois supprimer définitivement avec des 404 ou 410.
Attention aux CMS qui appliquent le noindex par défaut sur certains templates (pages auteur, tags, archives). Vérifiez systématiquement après une migration ou un changement de thème.
Comment auditer et corriger un site avec des problèmes d'indexation ?
- Crawlez votre site avec Screaming Frog ou Sitebulb pour lister toutes les pages avec meta robots noindex
- Croisez cette liste avec les URL indexées dans la Search Console (rapport Couverture)
- Identifiez les incohérences : pages noindex encore dans l'index, ou pages stratégiques noindexées par erreur
- Vérifiez le rendu JavaScript pour chaque type de page critique (PDP, catégories, articles)
- Contrôlez que le robots.txt n'interfère pas avec les URL noindexées
- Suivez l'évolution du nombre de pages indexées semaine après semaine pour détecter les anomalies
❓ Questions frequentes
Combien de temps faut-il pour qu'une page noindexée disparaisse de l'index Google ?
Peut-on utiliser noindex et canonical sur la même page ?
Le noindex empêche-t-il Google de suivre les liens sortants ?
Faut-il retirer les pages noindexées du sitemap XML ?
Le noindex fonctionne-t-il dans les en-têtes HTTP ou seulement en HTML ?
🎥 De la même vidéo 12
Autres enseignements SEO extraits de cette même vidéo Google Search Central · publiée le 04/12/2024
🎥 Voir la vidéo complète sur YouTube →
💬 Commentaires (0)
Soyez le premier à commenter.