Official statement
Other statements from this video 15 ▾
- □ Pourquoi Google limite-t-il les sitemaps à 50 000 URLs, index compris ?
- □ Les attributs ARIA améliorent-ils vraiment le SEO de votre site ?
- □ Faut-il vraiment rediriger les URL canonicalisées pour améliorer son référencement ?
- □ Google ignore-t-il vraiment les fragments d'URL (#) pour le référencement ?
- □ Pourquoi l'optimisation technique seule ne fait-elle plus ranker un site ?
- □ Comment vérifier si votre site est sous pénalité manuelle dans Search Console ?
- □ Pourquoi le balisage Product ne sert à rien pour l'immobilier ?
- □ Hreflang fonctionne-t-il vraiment pour du contenu non traduit mais ciblant des pays différents ?
- □ Le contraste des couleurs impacte-t-il vraiment le référencement naturel ?
- □ La balise HTML <article> améliore-t-elle vraiment le référencement ?
- □ Liens relatifs vs absolus : y a-t-il vraiment un impact SEO ?
- □ Faut-il vraiment imposer l'anglais dans les données structurées pour les jours de la semaine ?
- □ Faut-il vraiment utiliser prefetch et prerender pour améliorer son SEO ?
- □ Faut-il vraiment oublier le cache Google pour diagnostiquer l'indexation ?
- □ Pourquoi Google indexe-t-il du contenu qui n'existe pas sur votre site ?
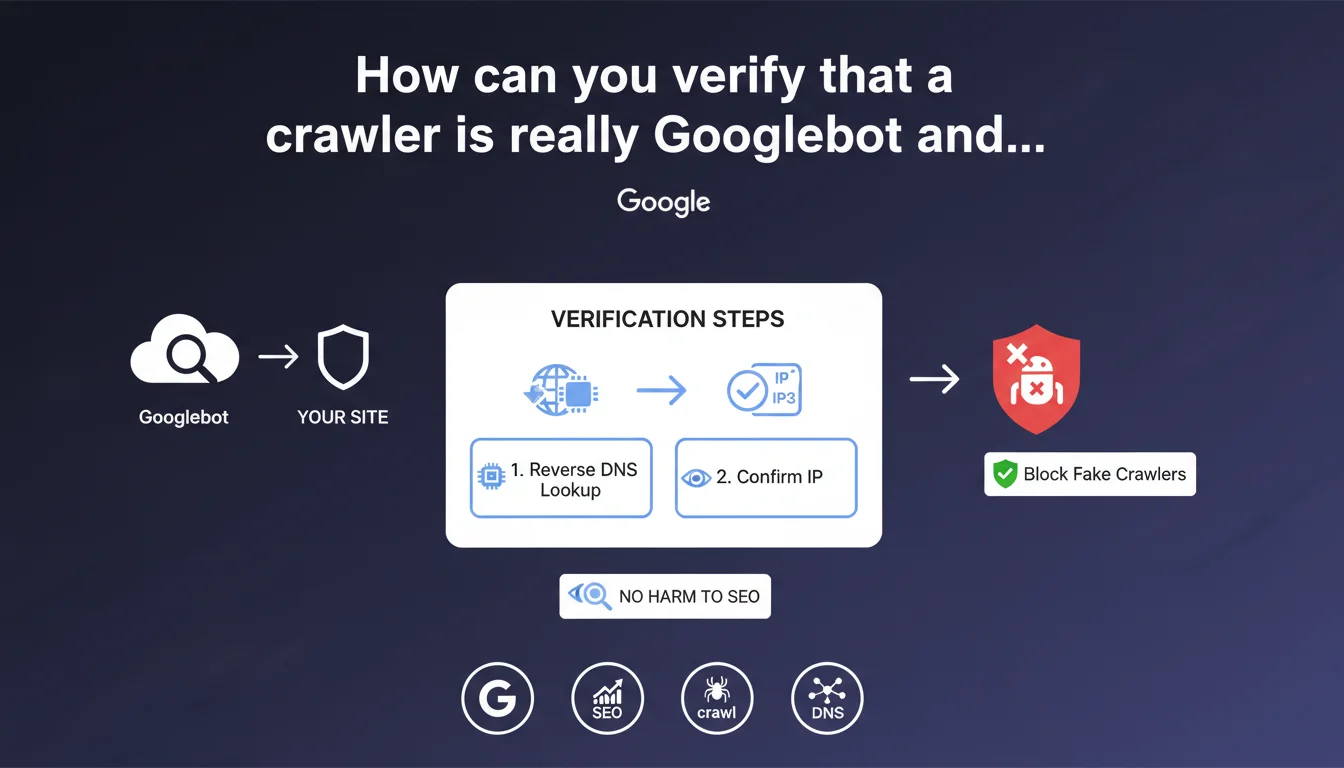
Google recommends verifying Googlebot's authenticity through reverse DNS lookup: retrieve the hostname from the IP, then confirm the IP from that hostname. Scrapers impersonating Googlebot with a spoofed user agent can be safely blocked without any risk to your search rankings.
What you need to understand
Why is this verification necessary?
Many malicious scrapers and bots impersonate Googlebot by using its user agent. The goal? To bypass the blocking rules you've put in place to protect your content or infrastructure.
The problem is that blindly blocking based on user agent risks blocking the real Googlebot if you make a mistake, or letting impostors through if you don't verify anything. Google therefore provides a reliable verification method based on DNS.
What does reverse DNS lookup involve?
The principle: you start with the IP address that requested your server. You perform a reverse DNS lookup to get the associated hostname (e.g., crawl-66-249-66-1.googlebot.com). Then, you perform a standard DNS lookup on that hostname to find the original IP.
If the IP matches and the hostname ends with googlebot.com or google.com, it's definitely Googlebot. Otherwise, it's an impostor you can safely block.
What alternatives does Google suggest?
Google also mentions online WHOIS services as a verification solution. Less technical, but also less precise — WHOIS doesn't necessarily guarantee that the IP belongs to Google at that moment in time.
The DNS method remains the most reliable and the one every professional should prioritize for automating server-side verification.
- Verify the IP via reverse DNS lookup then direct DNS lookup
- The hostname must end with .googlebot.com or .google.com
- Scrapers spoofing the user agent can be blocked
- WHOIS services are a less technical but less reliable alternative
SEO Expert opinion
Is this method truly reliable in practice?
Yes, it's the official method and the most secure. The reverse DNS lookup followed by a direct lookup validates consistency between IP and hostname. Google controls its IP ranges and DNS records — an impostor cannot fake that.
However, note that this verification must be automated on the server side. Doing this manually for each suspicious request makes no sense at scale. If you notice patterns of abuse, script the verification or integrate it into your security stack (WAF, middleware, etc.).
What are the limitations of this approach?
First limitation: DNS latency. A reverse lookup then a direct lookup takes time. If you need to verify each request in real-time, you risk slowing down your server. It's better to implement caching or a whitelist of validated IPs.
Second limitation: Google provides no indication of the rotation frequency of its IP ranges. [To verify] It's impossible to know if an IP validated today will still be valid in 3 months. Setting up a periodic revalidation system is prudent.
Should you systematically block fake Googlebot?
Let's be honest: yes. A bot impersonating Googlebot has no legitimate reason to do so. It's either a content scraper, a bot for reconnaissance for future attacks, or a competitor trying to steal your data.
Google explicitly states it's acceptable to block them. No SEO risk, no ambiguity. Once you've confirmed the IP is fake, block it at the firewall or web server level.
Practical impact and recommendations
How do you implement this verification on your server?
First step: identify suspicious requests. Check your server logs and filter user agents containing "Googlebot". Extract the associated IPs.
Second step: script the verification. In Bash, it looks like:
host [IP] → retrieve the hostname
host [hostname] → verify that the IP matches
If you're running Apache or Nginx, you can integrate this logic via a verification module or middleware script. For a more complex environment, consider a configured WAF to handle this validation automatically.
What mistakes should you absolutely avoid?
Classic mistake: blocking an IP range without DNS verification because it's generating a lot of traffic. You risk blocking the real Googlebot and getting your site deindexed.
Another mistake: relying solely on user agent. A user agent is a text string that can be modified at will — it's never proof of identity.
Finally, don't validate an IP just once and whitelist it forever. Google may change its IP ranges without warning. Revalidate periodically.
What should you do if you detect impostors?
Block them immediately at the firewall or web server level. You can also log these attempts to analyze attack patterns and anticipate other threats.
If the volume of impostors is significant, consider implementing rate limiting on requests claiming to come from Googlebot before validation. This slows down scrapers without impacting the real crawler.
- Extract IPs from "Googlebot" user agents from your logs
- Automate reverse DNS lookup + direct DNS lookup
- Verify that the hostname ends with .googlebot.com or .google.com
- Block IPs that fail verification at the firewall or server level
- Implement caching of validated IPs to minimize latency
- Periodically revalidate whitelisted IPs (e.g., every 30 days)
- Log impersonation attempts for analysis
❓ Frequently Asked Questions
Peut-on bloquer un crawler qui se fait passer pour Googlebot sans risque SEO ?
Le reverse DNS lookup ralentit-il le serveur ?
Quels hostnames indiquent que c'est bien Googlebot ?
Faut-il utiliser les services WHOIS pour vérifier Googlebot ?
Google change-t-il souvent ses plages d'IP ?
🎥 From the same video 15
Other SEO insights extracted from this same Google Search Central video · published on 09/08/2023
🎥 Watch the full video on YouTube →
💬 Comments (0)
Be the first to comment.