Official statement
Other statements from this video 15 ▾
- □ Pourquoi Google limite-t-il les sitemaps à 50 000 URLs, index compris ?
- □ Les attributs ARIA améliorent-ils vraiment le SEO de votre site ?
- □ Faut-il vraiment rediriger les URL canonicalisées pour améliorer son référencement ?
- □ Google ignore-t-il vraiment les fragments d'URL (#) pour le référencement ?
- □ Pourquoi l'optimisation technique seule ne fait-elle plus ranker un site ?
- □ Comment vérifier si votre site est sous pénalité manuelle dans Search Console ?
- □ Pourquoi le balisage Product ne sert à rien pour l'immobilier ?
- □ Hreflang fonctionne-t-il vraiment pour du contenu non traduit mais ciblant des pays différents ?
- □ Le contraste des couleurs impacte-t-il vraiment le référencement naturel ?
- □ La balise HTML <article> améliore-t-elle vraiment le référencement ?
- □ Liens relatifs vs absolus : y a-t-il vraiment un impact SEO ?
- □ Faut-il vraiment imposer l'anglais dans les données structurées pour les jours de la semaine ?
- □ Comment vérifier qu'un crawler est réellement Googlebot et bloquer les imposteurs ?
- □ Faut-il vraiment utiliser prefetch et prerender pour améliorer son SEO ?
- □ Pourquoi Google indexe-t-il du contenu qui n'existe pas sur votre site ?
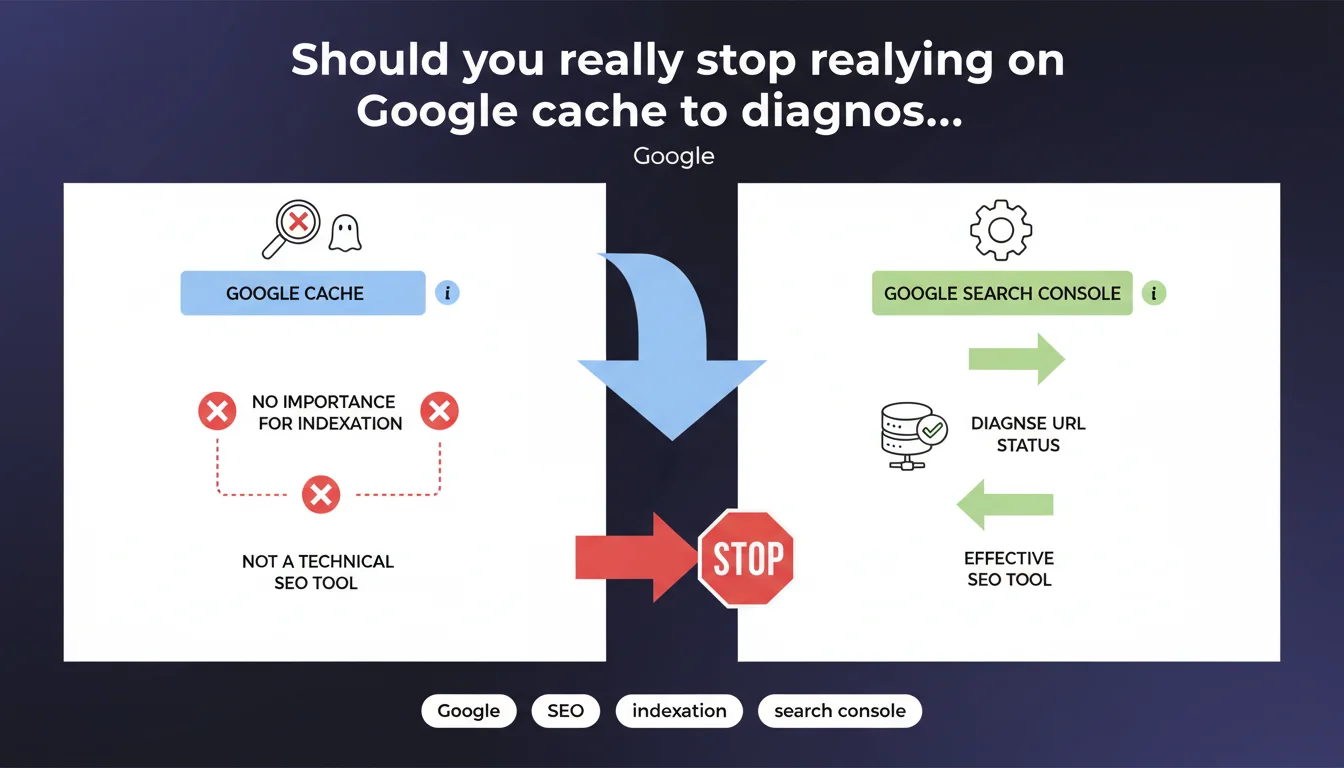
Google states that its cache has no importance for indexation and should not be considered a SEO diagnostic tool. Google Search Console remains the sole reference for verifying a URL's indexation status. This position definitively ends a practice that has been deeply rooted in many SEO professionals' workflows for years.
What you need to understand
Why is Google making such a point about this now?
For years, checking the Google cache was a reflex to verify if a page was indexed and how the search engine perceived it. This practice became so ingrained in diagnostic workflows that it became almost automatic.
Google is clear: the cache was never designed as a SEO diagnostic tool. It was a user feature to access a saved version of a page that was temporarily unavailable — nothing more.
What does "cache has no importance for indexation" really mean?
Google clearly separates two concepts that are often confused: the indexation process and the cache system. A page can be perfectly indexed without appearing in the cache, or conversely appear in the cache without being properly indexed for certain queries.
The cache simply reflects a dated snapshot, not necessarily the active version in the search index. Relying on it to diagnose indexation problems is like confusing a photo of an event with the event itself.
What concrete alternative does Google propose?
The recommendation is unambiguous: Search Console and only Search Console. The URL inspection tool provides access to real data about indexation status, errors detected by Googlebot, and the last successful crawl.
- Precise indexation status: URL indexed or not, documented exclusion reasons
- Complete HTML rendering: what Googlebot actually sees after JavaScript execution
- Error diagnosis: robots.txt blocks, redirects, server errors, canonicalization issues
- Crawl data: last crawl date, blocked resources, mobile/desktop version
- Reindexation request: ability to submit a modified URL directly
SEO Expert opinion
Is this statement consistent with what we observe in the field?
Let's be honest: many of us have noticed unexplained discrepancies between the cache and actual indexation. Pages absent from the cache that ranked perfectly, or obsolete cached versions when the URL was freshly reindexed.
Google is finally putting words to what field experience has shown for a long time — the cache is not reliable as an indicator. This clarification doesn't fundamentally change our practices if we were already using Search Console extensively, but it definitively kills a reflex inherited from another era of SEO.
What nuances should we add to this position?
The cache retains marginal utility in specific cases: quickly checking how Googlebot interprets visible text content (aside from complex JavaScript enhancements), or noting that a dated version persists despite recent changes — a signal of potential crawl problems.
But be careful — [To verify]: if the cache shows a very old version while Search Console indicates recent crawling, this can reveal an inconsistency in Google's systems rather than a problem on your side. In this case, cross-referencing with other tools (server logs, rendering tests) becomes essential.
Does this directive really simplify SEO diagnosis?
In theory, yes — a single reference tool avoids confusion. In practice, Search Console has its own limitations: data reporting delays, sometimes several hours or even days before a change becomes visible in the interface.
Experienced SEOs know that no single tool is sufficient. Server logs, independent rendering tests (Screaming Frog, OnCrawl), and manual source code inspection remain necessary complements to diagnose technical issues in depth. Google simplifies the message for the general public, but the reality of technical diagnosis remains multifaceted.
Practical impact and recommendations
What needs to change concretely in your SEO audits?
First immediate consequence: remove any reference to the cache from your documented diagnostic processes. If your audit reports still mention "check Google cache," replace it with "inspect the URL in Search Console."
Train your teams — and your clients — about this new reality. The "cache: URL" reflex in Google Search is dying definitively. It will likely be disabled soon anyway, so you might as well anticipate.
How do you structure a reliable indexation diagnosis now?
Your workflow should revolve around three complementary pillars: Search Console for official status, server logs for actual Googlebot activity, and rendering tests to validate JavaScript execution.
- Systematically use the URL inspection tool in Search Console for each problematic page
- Check the coverage report to identify exclusion patterns at scale
- Cross-reference with server logs: is Googlebot actually crawling the relevant URLs? How frequently?
- Test JavaScript rendering with third-party tools if content depends on modern frameworks
- Analyze server response times and 5xx errors that block indexation without always reporting clearly
- Document time gaps between modifying a page and updating it in Search Console
- Stop wasting time looking for explanations in a cache that means nothing
What mistakes must you absolutely avoid from now on?
Never conclude that a page isn't indexed solely because it doesn't appear in the cache. This is the most common pitfall — and the exact one Google wants to eliminate with this communication.
Conversely, don't get too reassured because a cached version exists. It can be obsolete, deindexed for other reasons, or simply inactive in actual search results despite its phantom presence in the cache.
❓ Frequently Asked Questions
Peut-on encore utiliser cache:URL dans Google pour vérifier une page ?
Si une page apparaît dans le cache mais pas dans Search Console, laquelle croire ?
Comment savoir si Googlebot voit bien mon contenu JavaScript sans le cache ?
Le cache Google va-t-il disparaître complètement ?
Quels outils alternatifs utiliser si Search Console tarde à rafraîchir les données ?
🎥 From the same video 15
Other SEO insights extracted from this same Google Search Central video · published on 09/08/2023
🎥 Watch the full video on YouTube →
💬 Comments (0)
Be the first to comment.