Declaration officielle
Autres déclarations de cette vidéo 15 ▾
- □ Pourquoi Google limite-t-il les sitemaps à 50 000 URLs, index compris ?
- □ Les attributs ARIA améliorent-ils vraiment le SEO de votre site ?
- □ Faut-il vraiment rediriger les URL canonicalisées pour améliorer son référencement ?
- □ Google ignore-t-il vraiment les fragments d'URL (#) pour le référencement ?
- □ Pourquoi l'optimisation technique seule ne fait-elle plus ranker un site ?
- □ Comment vérifier si votre site est sous pénalité manuelle dans Search Console ?
- □ Pourquoi le balisage Product ne sert à rien pour l'immobilier ?
- □ Hreflang fonctionne-t-il vraiment pour du contenu non traduit mais ciblant des pays différents ?
- □ Le contraste des couleurs impacte-t-il vraiment le référencement naturel ?
- □ La balise HTML <article> améliore-t-elle vraiment le référencement ?
- □ Liens relatifs vs absolus : y a-t-il vraiment un impact SEO ?
- □ Faut-il vraiment imposer l'anglais dans les données structurées pour les jours de la semaine ?
- □ Faut-il vraiment utiliser prefetch et prerender pour améliorer son SEO ?
- □ Faut-il vraiment oublier le cache Google pour diagnostiquer l'indexation ?
- □ Pourquoi Google indexe-t-il du contenu qui n'existe pas sur votre site ?
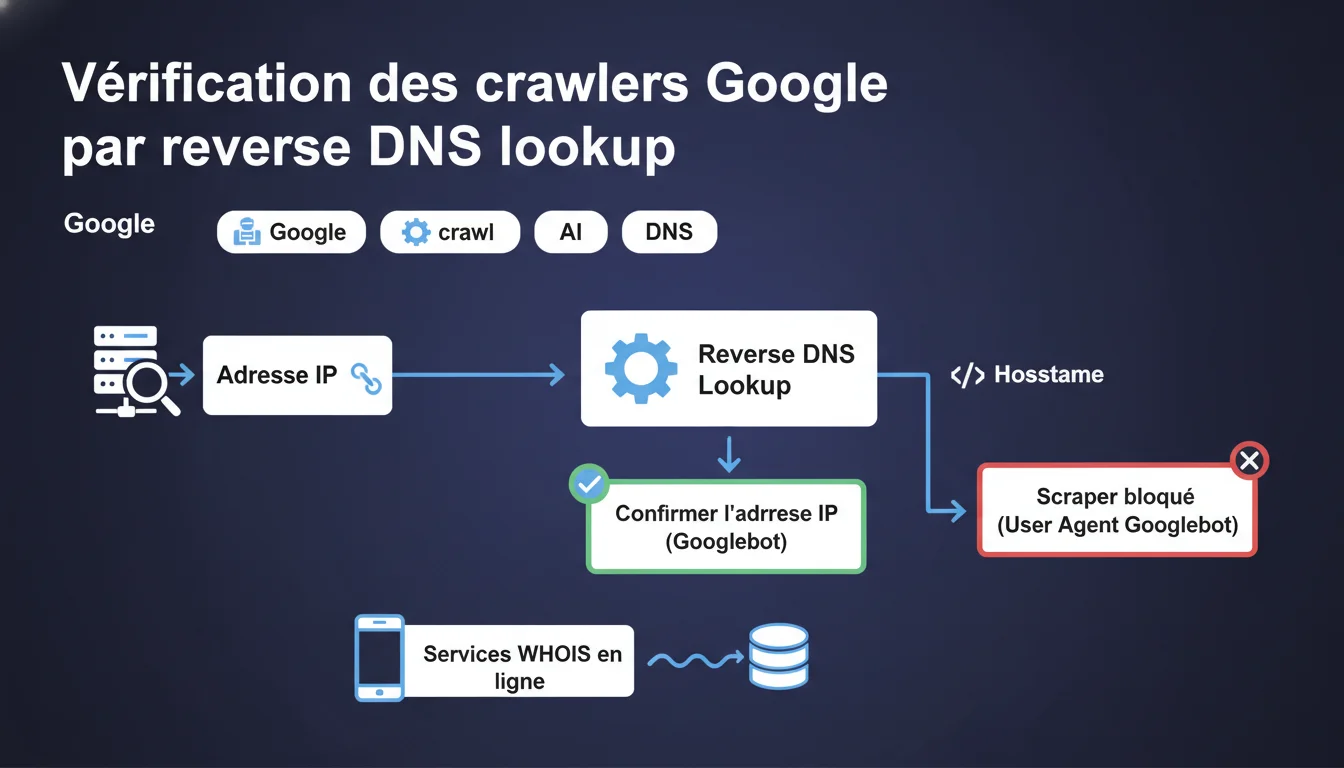
Google recommande de vérifier l'authenticité de Googlebot via un reverse DNS lookup : récupérez le hostname depuis l'IP, puis confirmez l'IP depuis ce hostname. Les scrapers se faisant passer pour Googlebot avec un user agent falsifié peuvent être bloqués sans risque pour votre référencement.
Ce qu'il faut comprendre
Pourquoi cette vérification est-elle nécessaire ?
De nombreux scrapers et bots malveillants usurpent l'identité de Googlebot en utilisant son user agent. L'objectif ? Contourner les règles de blocage que vous avez mises en place pour protéger votre contenu ou votre infrastructure.
Le problème, c'est que bloquer aveuglément sur la base du user agent risque de bloquer le vrai Googlebot si vous vous trompez, ou de laisser passer des imposteurs si vous ne vérifiez rien. Google fournit donc une méthode de vérification fiable basée sur le DNS.
En quoi consiste le reverse DNS lookup ?
Le principe : vous partez de l'adresse IP qui a requêté votre serveur. Vous faites un reverse DNS lookup pour obtenir le hostname associé (ex : crawl-66-249-66-1.googlebot.com). Ensuite, vous faites un DNS lookup classique sur ce hostname pour retrouver l'IP de départ.
Si l'IP correspond et que le hostname termine par googlebot.com ou google.com, c'est bien Googlebot. Sinon, c'est un imposteur que vous pouvez bloquer sans scrupule.
Quelles sont les alternatives proposées par Google ?
Google mentionne aussi les services WHOIS en ligne comme solution de vérification. Moins technique, mais moins précis aussi — le WHOIS ne vous garantit pas forcément que l'IP appartient bien à Google au moment T.
La méthode DNS reste la plus fiable et celle que tout professionnel devrait privilégier pour automatiser la vérification côté serveur.
- Vérifiez l'IP via reverse DNS lookup puis DNS lookup direct
- Le hostname doit se terminer par .googlebot.com ou .google.com
- Les scrapers usurpant le user agent peuvent être bloqués
- Les services WHOIS sont une alternative moins technique mais moins fiable
Avis d'un expert SEO
Cette méthode est-elle vraiment fiable en pratique ?
Oui, c'est la méthode officielle et la plus sûre. Le reverse DNS lookup suivi d'un lookup direct permet de valider la cohérence entre IP et hostname. Google contrôle ses plages d'IP et ses enregistrements DNS — un imposteur ne peut pas falsifier ça.
Attention toutefois : cette vérification doit être automatisée côté serveur. Faire ça manuellement à chaque requête suspecte n'a aucun sens à l'échelle. Si vous constatez des patterns d'abus, scriptez la vérification ou intégrez-la dans votre stack de sécurité (WAF, middleware, etc.).
Quelles sont les limites de cette approche ?
Première limite : la latence DNS. Un reverse lookup puis un lookup direct, ça prend du temps. Si vous devez vérifier chaque requête en temps réel, vous risquez de ralentir votre serveur. Mieux vaut mettre en place un cache ou une whitelist des IP validées.
Deuxième limite : Google ne donne aucune indication sur la fréquence de rotation de ses plages d'IP. [A vérifier] Impossible de savoir si une IP validée aujourd'hui le sera encore dans 3 mois. Prévoir un système de revalidation périodique est prudent.
Faut-il bloquer systématiquement les faux Googlebot ?
Soyons honnêtes : oui. Un bot qui usurpe l'identité de Googlebot n'a aucune raison légitime de le faire. C'est soit un scraper de contenu, soit un bot de reconnaissance pour des attaques futures, soit un concurrent qui veut aspirer vos données.
Google dit explicitement que c'est acceptable de les bloquer. Pas de risque SEO, pas d'ambiguïté. Si vous avez confirmé que l'IP est fake, bloquez-la au niveau firewall ou serveur web.
Impact pratique et recommandations
Comment mettre en place cette vérification sur votre serveur ?
Première étape : identifiez les requêtes suspectes. Consultez vos logs serveur et filtrez les user agents contenant "Googlebot". Extrayez les IP associées.
Deuxième étape : scriptez la vérification. En Bash, ça donne :
host [IP] → récupérer le hostname
host [hostname] → vérifier que l'IP correspond
Si vous êtes sous Apache ou Nginx, vous pouvez intégrer cette logique via un module de vérification ou un script middleware. Pour un environnement plus complexe, envisagez un WAF configuré pour faire cette validation automatiquement.
Quelles erreurs faut-il éviter absolument ?
Erreur classique : bloquer une plage d'IP sans vérification DNS parce qu'elle génère beaucoup de trafic. Vous risquez de bloquer le vrai Googlebot et de vous faire désindexer.
Autre erreur : se fier uniquement au user agent. Un user agent est une chaîne de texte modifiable à volonté — ce n'est jamais une preuve d'identité.
Enfin, ne validez pas une IP une seule fois et ne la whitelistez pas pour l'éternité. Google peut changer ses plages d'IP sans prévenir. Revalidez périodiquement.
Que faire si vous détectez des imposteurs ?
Bloquez-les immédiatement au niveau du pare-feu ou du serveur web. Vous pouvez aussi logger ces tentatives pour analyser les patterns d'attaque et anticiper d'autres menaces.
Si le volume d'imposteurs est important, envisagez de limiter le rate limiting sur les requêtes prétendant venir de Googlebot avant validation. Ça ralentit les scrapers sans impacter le vrai crawler.
- Extraire les IP des user agents "Googlebot" depuis vos logs
- Automatiser le reverse DNS lookup + DNS lookup direct
- Vérifier que le hostname se termine par .googlebot.com ou .google.com
- Bloquer les IP qui échouent la vérification au niveau firewall ou serveur
- Mettre en place un cache des IP validées pour limiter la latence
- Revalider périodiquement les IP whitelistées (ex : tous les 30 jours)
- Logger les tentatives d'usurpation pour analyse
❓ Questions frequentes
Peut-on bloquer un crawler qui se fait passer pour Googlebot sans risque SEO ?
Le reverse DNS lookup ralentit-il le serveur ?
Quels hostnames indiquent que c'est bien Googlebot ?
Faut-il utiliser les services WHOIS pour vérifier Googlebot ?
Google change-t-il souvent ses plages d'IP ?
🎥 De la même vidéo 15
Autres enseignements SEO extraits de cette même vidéo Google Search Central · publiée le 09/08/2023
🎥 Voir la vidéo complète sur YouTube →
💬 Commentaires (0)
Soyez le premier à commenter.