Official statement
Other statements from this video 16 ▾
- □ Google attribue-t-il vraiment le même poids à tous vos backlinks ?
- □ L'emplacement des liens internes a-t-il vraiment un impact sur le SEO ?
- □ Google classe-t-il vraiment les sites dans des catégories fixes ?
- □ La cohérence NAP impacte-t-elle vraiment le référencement local ou seulement le Knowledge Graph ?
- □ Comment éviter que Google se trompe à cause d'informations conflictuelles entre votre site et votre profil d'établissement ?
- □ Les liens réciproques sont-ils vraiment sans risque pour votre SEO ?
- □ La fréquence des mots-clés influence-t-elle vraiment le classement Google ?
- □ Faut-il vraiment nettoyer TOUTES les pages hackées ou peut-on laisser Google faire le tri ?
- □ Pourquoi Google refuse-t-il d'indexer une partie de votre site même s'il est techniquement parfait ?
- □ Les emojis dans les balises title et meta description apportent-ils un avantage SEO ?
- □ L'API Search Console et l'interface affichent-elles vraiment les mêmes données ?
- □ Pourquoi vos FAQ n'apparaissent-elles pas en rich results malgré un balisage correct ?
- □ Faut-il vraiment réutiliser la même URL pour les pages saisonnières chaque année ?
- □ Les Core Web Vitals n'affectent-ils vraiment ni le crawl ni l'indexation ?
- □ Pourquoi Google réinitialise-t-il l'évaluation d'un site lors d'une migration de sous-domaine vers domaine principal ?
- □ Le TLD .edu booste-t-il vraiment votre référencement ?
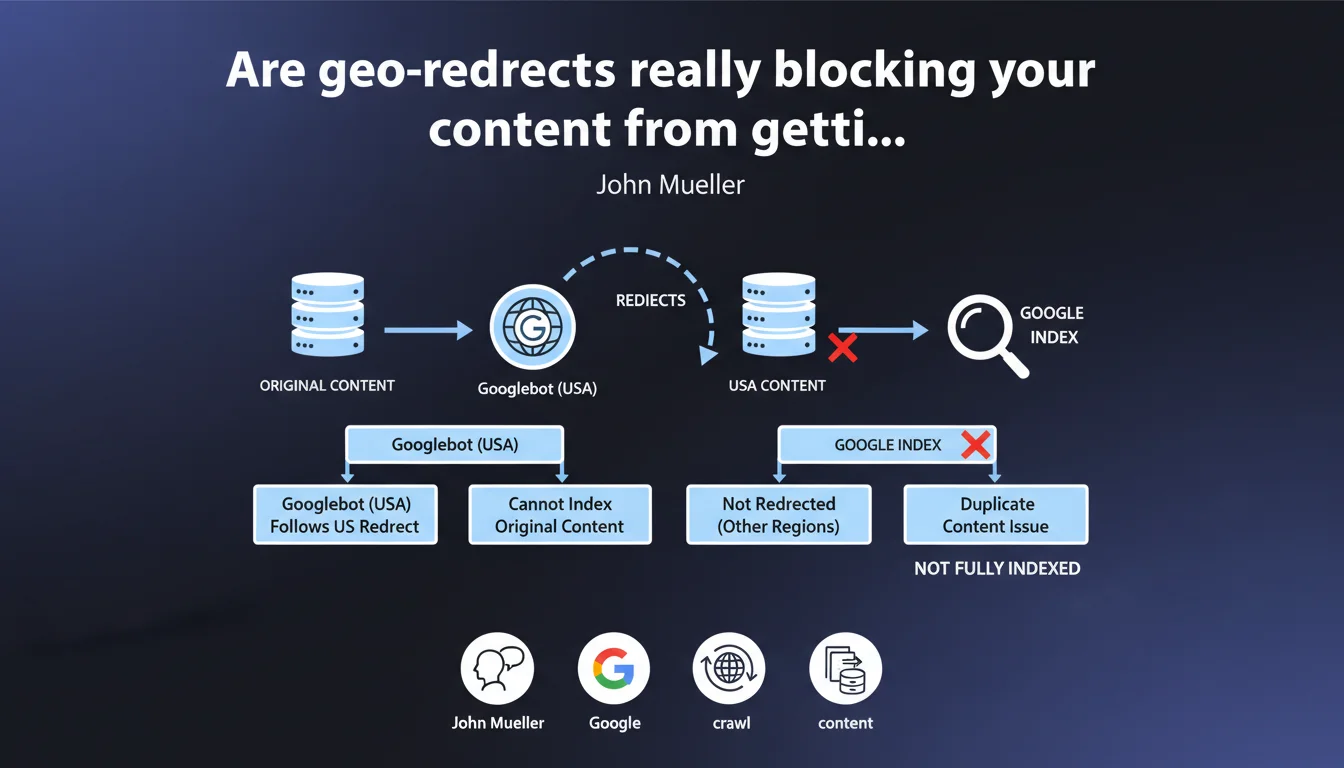
Googlebot crawls from a single geographic location. If your site automatically redirects US visitors and Googlebot follows that redirect, the original content becomes invisible to Google. It's not cloaking according to Mueller, but it remains a devastating technical trap that creates duplication and fragments your indexation.
What you need to understand
Why can't Googlebot see all your geo-localized content?
Googlebot crawls primarily from American datacenters. When a site detects this US origin and applies automatic geo-redirection, the bot gets stuck on a single version of the site.
In concrete terms? If your French site automatically redirects US visitors to example.com/us/, Googlebot will never see the original French content. It will only discover the American version, creating a gaping hole in your indexation.
Does Google consider this cloaking?
No, according to Mueller. Cloaking implies an intention to deceive by serving different content to the bot. Here, it's a non-intentional technical behavior — the redirect applies uniformly based on detected IP geolocation.
So the problem isn't a penalty, but a pure and simple indexation failure. Your content exists, but Google can't see it. That's even worse than a penalty: you're invisible without even knowing it.
What are the duplication risks mentioned?
If certain geographic versions are not redirected but remain accessible via different URLs (/fr/, /de/, /uk/), Google can index multiple similar versions. You then create content duplication across regions.
The worst scenario: some pages redirect, others don't. Google indexes an incoherent patchwork of regional versions without understanding your architecture. Result — signal dilution, cannibalization between versions.
- Googlebot crawls from a single location, primarily from American IPs
- Geo-redirects block access to the original content for the bot
- It's not cloaking, but a technical accessibility problem
- Duplication appears if redirects are inconsistent between versions
- Indexation becomes fragmented and unpredictable
SEO Expert opinion
Does this statement really reflect what we observe in the field?
Yes, and it's actually worse than what Mueller describes. We regularly see international sites lose 40-60% of their indexed pages due to misconfigured geo-redirects. The diagnosis is complex because Search Console shows cryptic crawl errors without clearly indicating that geo-redirection is the culprit.
The real trap? These redirects are often implemented at the CDN level (Cloudflare, Akamai) or via JavaScript scripts. Googlebot can follow some JS redirects but not all — [To be verified] depending on implementation complexity and execution timing.
What nuances should be added to this official position?
Mueller doesn't mention that Googlebot can sometimes crawl from other locations for sites with properly configured hreflang. Google sporadically uses European or Asian IPs to validate local versions — but it's rare, unpredictable, and should never serve as your primary strategy.
Another point: he says it's "not cloaking," but be careful. If you serve different content intentionally to the bot (by detecting its user-agent rather than its IP), that becomes pure cloaking. The distinction is subtle but critical.
In what cases does this rule not apply completely?
If you use hreflang annotations correctly and your regional URLs remain accessible without forced redirection, Google can index all versions. The key: let Googlebot freely access each linguistic/regional version via its canonical URL.
Geo-redirects based on user acceptance (pop-up "Would you like to see the US version?") generally don't pose problems — Googlebot doesn't click pop-ups and accesses the default content. But honestly, it's a disastrous UX for humans.
Practical impact and recommendations
What concrete steps should you take to avoid this trap?
First priority: audit all your geo-localized redirects. Use a VPN or proxies to test access from different countries. Verify that Googlebot can reach each version without being forcibly redirected.
Configure your server or CDN to never redirect the Googlebot user-agent — identify it and let it access the original content. This is technically different from cloaking since you're not changing the content, just preventing automatic redirection.
How should you properly structure a multilingual/multi-regional site?
Prioritize manual language/region selection via a persistent menu rather than automatic redirects. Serve a default version accessible to everyone (usually English or your main market language).
Implement hreflang tags on all pages to indicate linguistic/regional variants to Google. Ensure each URL remains directly accessible without redirection — hreflang tells Google which version to display to which user, without blocking bot access.
What tools should you use to verify your configuration works?
Search Console remains your first indicator. Look at the Coverage tab: if international URLs appear as "Discovered, currently not indexed," you likely have a geo-redirect problem.
Use the URL Inspection tool to test Googlebot access to each regional version. If Google shows a redirect or cannot access the content, you've identified the culprit.
- Audit all geo-redirect rules (server, CDN, JS scripts)
- Exclude Googlebot from automatic IP-based redirects
- Implement hreflang tags on all linguistic variants
- Keep each regional URL accessible without forced redirection
- Favor manual language/region selector over automatic
- Test access from different locations with VPN/proxies
- Check indexation coverage in Search Console by language version
- Use URL Inspection to validate Googlebot access to each variant
❓ Frequently Asked Questions
Est-ce que je risque une pénalité Google si j'utilise des géo-redirects ?
Comment savoir si mes géo-redirects bloquent Googlebot ?
Les hreflang suffisent-ils à remplacer les géo-redirects ?
Puis-je exclure uniquement Googlebot des géo-redirects sans risque ?
Que faire si j'ai déjà perdu des pages indexées à cause de géo-redirects ?
🎥 From the same video 16
Other SEO insights extracted from this same Google Search Central video · published on 30/01/2022
🎥 Watch the full video on YouTube →
💬 Comments (0)
Be the first to comment.