Official statement
Other statements from this video 13 ▾
- □ Pourquoi Google préfère-t-il les données structurées au machine learning pour comprendre vos pages ?
- □ Faut-il encore se fatiguer avec les données structurées si le machine learning fait le boulot ?
- □ Les données structurées donnent-elles vraiment du contrôle aux webmasters sur l'affichage Google ?
- □ Google vérifie-t-il réellement l'exactitude de vos données structurées ?
- □ Pourquoi Google recommande-t-il de commencer par les données structurées génériques ?
- □ Pourquoi votre Schema.org valide peut être rejeté par Google ?
- □ Faut-il implémenter des données structurées même si Google ne les utilise pas encore ?
- □ Les données structurées influencent-elles vraiment la compréhension du sujet d'une page par Google ?
- □ Les données structurées sont-elles vraiment utiles si Google comprend déjà votre page ?
- □ Faut-il vraiment bourrer vos pages de données structurées pour mieux ranker ?
- □ Faut-il abandonner JSON-LD au profit de Microdata pour les données structurées ?
- □ Le JSON-LD externe pose-t-il vraiment des problèmes de synchronisation pour Google ?
- □ Les outils de test Google sont-ils vraiment fiables pour détecter vos données structurées manquantes ?
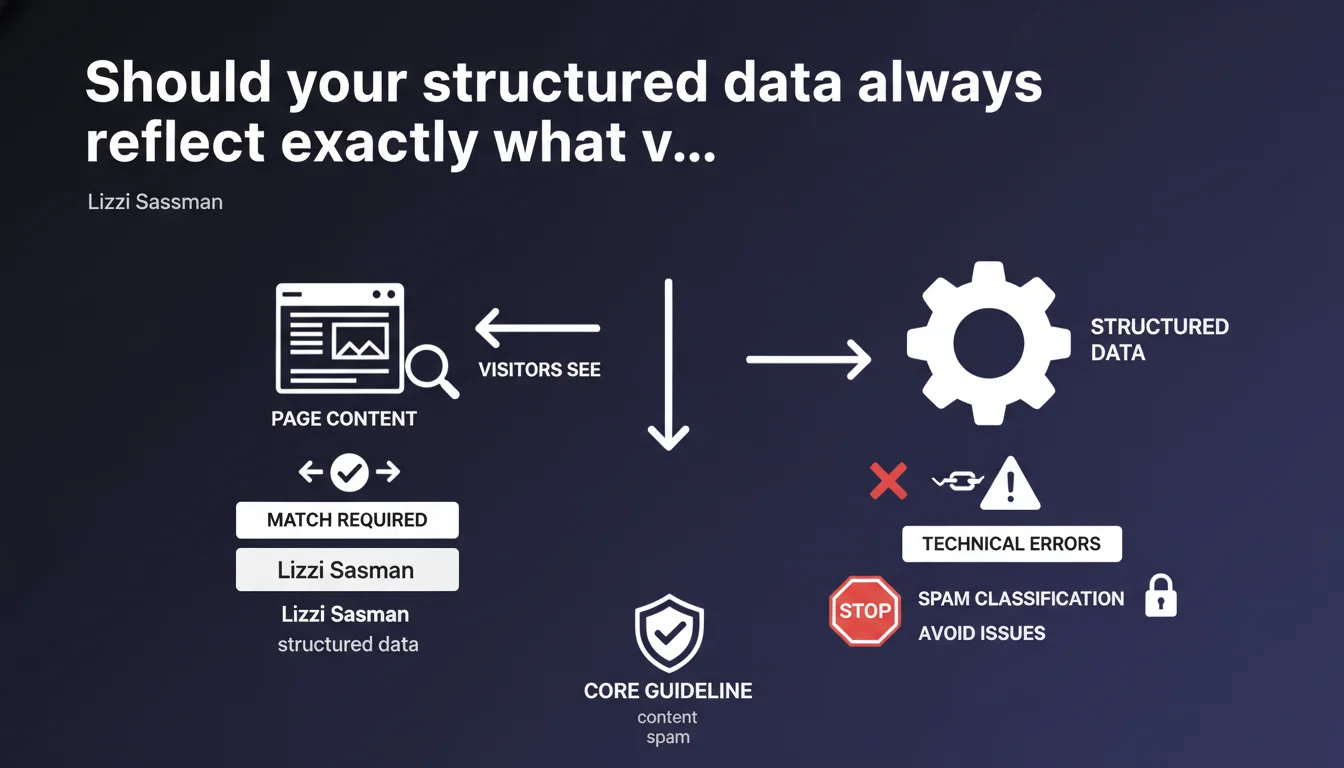
Google requires structured data to strictly match visible page content, or it risks being flagged as spam. This rule aims to prevent manipulation, though Google tolerates unintentional technical errors. However, the boundary between honest mistakes and abuse remains unclear.
What you need to understand
Why does Google enforce this strict matching requirement?
Google is determined to crack down on schema markup abuse where websites inject structured data to display rich results without corresponding content actually existing on the page. A classic example: adding 5-star review schema.org markup when no review system exists on the site.
This requirement is spelled out clearly in Google's official structured data guidelines. The goal is to ensure that rich snippets appearing in search results genuinely reflect what users will find when they land on your page.
What exactly qualifies as "visible content"?
The concept of visible content seems straightforward on the surface, but it conceals significant gray areas. Is content hidden behind a JavaScript tab considered visible? What about a price that only appears after selecting a product variant?
Google doesn't specify precisely where the line is drawn. Lizzi Sassman's statement intentionally remains vague, which leaves room for interpretation — and therefore risk.
How do you distinguish between technical error and intentional manipulation?
Google claims to tolerate unintentional technical errors, but doesn't explain how its algorithm tells the difference between an honest mistake and an attempted manipulation. This ambiguity is problematic for practitioners.
In reality? Will a one-off misalignment caused by a CMS update bug be treated differently from systematically inflated schema markup? The statement doesn't answer that.
- Structured data must match content that actually exists on the page
- Any discrepancy can be interpreted as spam under the guidelines
- Google officially tolerates unintentional errors without specifying distinction criteria
- The gray area around what counts as "visible" remains substantial
- Sites risk manual actions or loss of rich results
SEO Expert opinion
Does this statement actually provide real clarity?
Let's be frank: this communication changes nothing. The requirement for structured data to match visible content has been in the guidelines for years. Lizzi Sassman is simply restating an existing rule without providing new precision.
The real problem is that edge cases remain unanswered. What about content loaded via AJAX after user interaction? Information present in mobile version but absent on desktop? [To verify]: Google has never published explicit criteria for settling these situations.
Does the "unintentional error" argument actually hold up?
Google claims to distinguish between technical errors and manipulation. In practice, this distinction is impossible to automate reliably. How can an algorithm determine intent behind a data mismatch?
The outcome: either Google is bluffing and applies the rule mechanically, or manual actions are required to arbitrate — meaning only large, visible sites will actually face scrutiny. Small sites with legitimate errors risk being penalized automatically.
What are the practical limitations of this rule?
Certain schema markup types create structural challenges. Take Recipe schema: must you display the entire ingredient list as visible text, or is JSON-LD sufficient if ingredients appear in an interactive table?
Google doesn't weigh in. Webmasters are stuck between following a strict interpretation that hurts UX, or taking a calculated risk with a more flexible implementation. Sassman's statement doesn't help resolve these dilemmas.
Practical impact and recommendations
How do you verify your structured data is compliant?
Your first move: systematically compare your schema markup against the content actually displayed. Use Google's Rich Results Test and cross-reference the extracted data with what a real user sees on the page.
Don't rely solely on automated tools — perform manual verification on a representative sample of pages. The most problematic gaps often involve small details: a publication date that differs slightly, a price shown excluding tax in schema but including it on-page, and so on.
Which errors should you avoid at all costs?
Never add structured data for content that doesn't appear on the page. This is the most blatant and risky manipulation. If you don't display customer reviews, don't include AggregateRating schema.
Also watch out for conditional content: if a price only shows after selecting a product variant, your Product schema must reflect this logic, not display a default price that could be misleading.
- Audit all pages containing structured data (schema.org, JSON-LD, microdata)
- Compare markup content against visible content as a human would see it
- Remove any schema markup for content not present on the page
- Test using Google's Rich Results Test and analyze discrepancies
- Verify consistency between mobile and desktop versions if schemas differ
- Document your implementation choices for edge cases (interactive content, tabs, etc.)
- Set up regular monitoring to catch drifts after updates
❓ Frequently Asked Questions
Un contenu caché derrière un onglet JavaScript peut-il être utilisé dans les données structurées ?
Que se passe-t-il si mes données structurées contiennent une erreur involontaire ?
Faut-il dupliquer tout le contenu visible en JSON-LD ou une synthèse suffit-elle ?
Les différences entre version mobile et desktop posent-elles problème ?
Peut-on perdre ses résultats enrichis à cause d'un écart mineur ?
🎥 From the same video 13
Other SEO insights extracted from this same Google Search Central video · published on 07/04/2022
🎥 Watch the full video on YouTube →
💬 Comments (0)
Be the first to comment.