Official statement
Other statements from this video 13 ▾
- □ Pourquoi Google préfère-t-il les données structurées au machine learning pour comprendre vos pages ?
- □ Faut-il encore se fatiguer avec les données structurées si le machine learning fait le boulot ?
- □ Google vérifie-t-il réellement l'exactitude de vos données structurées ?
- □ Pourquoi Google recommande-t-il de commencer par les données structurées génériques ?
- □ Pourquoi votre Schema.org valide peut être rejeté par Google ?
- □ Faut-il implémenter des données structurées même si Google ne les utilise pas encore ?
- □ Les données structurées influencent-elles vraiment la compréhension du sujet d'une page par Google ?
- □ Les données structurées sont-elles vraiment utiles si Google comprend déjà votre page ?
- □ Faut-il vraiment bourrer vos pages de données structurées pour mieux ranker ?
- □ Faut-il abandonner JSON-LD au profit de Microdata pour les données structurées ?
- □ Le JSON-LD externe pose-t-il vraiment des problèmes de synchronisation pour Google ?
- □ Les outils de test Google sont-ils vraiment fiables pour détecter vos données structurées manquantes ?
- □ Les données structurées doivent-elles systématiquement refléter le contenu visible de la page ?
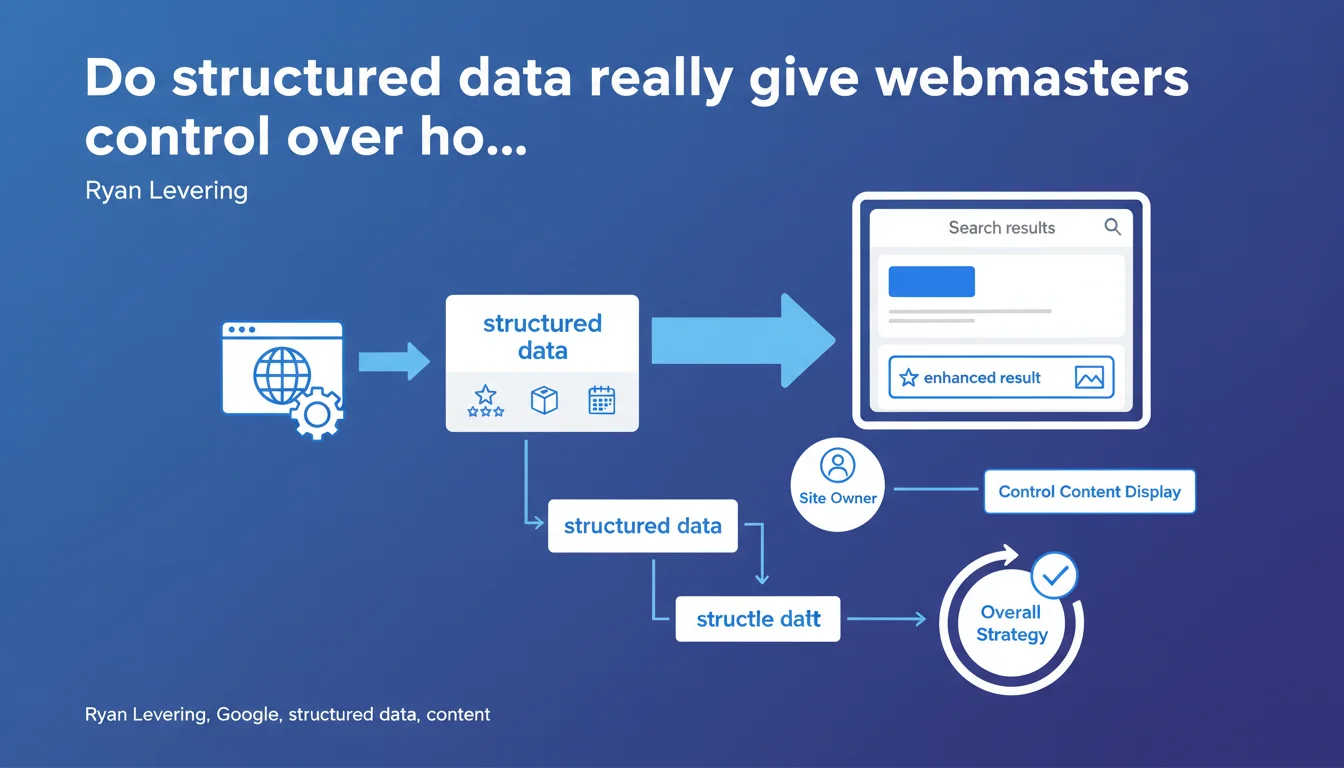
Google claims that structured data allows site owners to control the content displayed in search results. It's presented as a strategic tool to master the representation of your data. But the question remains: how far does this "control" really extend?
What you need to understand
What exactly does Google mean by "control"?
Google suggests that implementing structured data offers webmasters a form of control over how their content appears in SERPs. Concretely, by properly marking up your pages with Schema.org, you tell Google which information to prioritize when generating rich snippets, knowledge panels, or other enriched formats.
However, the term "control" deserves nuance. You don't dictate to Google what it must display — you suggest structured data that it can choose to use or ignore. The engine remains master of the final decision, especially if your data is deemed irrelevant or manipulative.
Why does Ryan Levering emphasize "the overall strategy"?
This mention is not insignificant. Structured data doesn't work in isolation. It must integrate into a coherent information architecture: content hierarchy, internal linking, semantic relevance.
If your Schema.org tags contradict visible content or are inconsistent from one page to another, Google will likely ignore them. "Control" only exists if the technical and editorial foundation is solid.
What is the political dimension of this statement?
Levering emphasizes that owners must "be able to control their data." This is a formulation that echoes debates about content ownership and how big platforms use data.
By offering this control lever via Schema.org, Google indirectly responds to criticism about content extraction without compensation. It's also an argument against regulators: "we provide the tools, webmasters decide."
- Structured data allow you to guide SERP display, not impose it
- Google remains the final judge of relevance and can ignore your Schema tags
- The effectiveness of structured data depends on site-wide consistency
- This approach also addresses political issues around content ownership
SEO Expert opinion
Is this promise of "control" consistent with real-world reality?
Partially. Structured data works well for specific use cases: events, recipes, products, FAQs. In these contexts, correct implementation genuinely generates predictable rich snippets.
But "control" erodes as soon as you move beyond these standardized formats. On complex editorial content, Google often extracts what it wants, ignoring your Article or NewsArticle in favor of its own parsing. Featured snippets, for example, almost never depend on structured data — Google generates them algorithmically. [To verify] the extent to which Speakable or HowTo tags really influence display.
When does this "control" become illusory?
As soon as Google detects over-optimization or data that doesn't match visible content. I've seen dozens of sites lose their rich snippets after attempting to manipulate tags — inflated prices in Product, fake reviews in Review, inconsistent event dates.
The real problem: Google doesn't always warn you. Your tags may be technically valid according to the validator, but simply ignored in production. You believe you have control, but you only have a false sense of mastery.
Should we see this as Google's recognition of responsibility?
Levering talks about "allowing people to control their data" in a context where platforms are accused of scraping content without compensation. It's a clever defensive position: "we provide the tools, it's up to you to use them."
But in practice, this transfer of responsibility also means that if your content is poorly represented in SERPs and you haven't marked it up correctly, it's your fault, not Google's. A rather clever reversal of burden.
Practical impact and recommendations
Which structured data formats deserve real investment?
Focus on formats with proven ROI: Product for e-commerce, Recipe if you're in food, Event for anything with a date, Organization and LocalBusiness for your entity. FAQ and HowTo have variable impact depending on your niche — test on key pages before rolling out widely.
Article and NewsArticle tags? Implement them properly for the Google News and Discover ecosystem, but don't expect miracles on classic search. The time invested in BreadcrumbList is always worthwhile: it structures navigation and improves breadcrumb trails in SERPs.
How do you verify that your structured data are actually being used?
The Google validator tells you if your code is syntactically correct, not whether Google uses it. For that, you need to monitor actual SERPs: search for your pages with their target queries and verify the actual display.
Use the "Enhancements" report in Search Console to track errors, but also coverage variations. If Google detects 150 products with Product tags then suddenly 80, it's ignoring 70 pages — find out why.
- Audit existing implementation with Screaming Frog or OnCrawl to identify pages without structured data
- Prioritize high-impact formats: Product, FAQ, LocalBusiness, BreadcrumbList
- Test each implementation with the Rich Results Test before deployment
- Verify consistency between visible content and marked-up content — any divergence will be penalized
- Monitor actual SERPs, not just validators
- Follow the Search Console "Enhancements" report to detect silent rejections
- Document your markup choices to maintain consistency over time
❓ Frequently Asked Questions
Les données structurées améliorent-elles directement le classement dans Google ?
Pourquoi mes données structurées valides ne génèrent-elles pas de rich snippets ?
Faut-il implémenter tous les types de Schema.org disponibles ?
Les données structurées en JSON-LD sont-elles préférables aux microdonnées ?
Comment savoir si Google utilise réellement mes données structurées ?
🎥 From the same video 13
Other SEO insights extracted from this same Google Search Central video · published on 07/04/2022
🎥 Watch the full video on YouTube →
💬 Comments (0)
Be the first to comment.