Official statement
Other statements from this video 13 ▾
- □ Pourquoi Google préfère-t-il les données structurées au machine learning pour comprendre vos pages ?
- □ Faut-il encore se fatiguer avec les données structurées si le machine learning fait le boulot ?
- □ Les données structurées donnent-elles vraiment du contrôle aux webmasters sur l'affichage Google ?
- □ Google vérifie-t-il réellement l'exactitude de vos données structurées ?
- □ Pourquoi Google recommande-t-il de commencer par les données structurées génériques ?
- □ Pourquoi votre Schema.org valide peut être rejeté par Google ?
- □ Les données structurées influencent-elles vraiment la compréhension du sujet d'une page par Google ?
- □ Les données structurées sont-elles vraiment utiles si Google comprend déjà votre page ?
- □ Faut-il vraiment bourrer vos pages de données structurées pour mieux ranker ?
- □ Faut-il abandonner JSON-LD au profit de Microdata pour les données structurées ?
- □ Le JSON-LD externe pose-t-il vraiment des problèmes de synchronisation pour Google ?
- □ Les outils de test Google sont-ils vraiment fiables pour détecter vos données structurées manquantes ?
- □ Les données structurées doivent-elles systématiquement refléter le contenu visible de la page ?
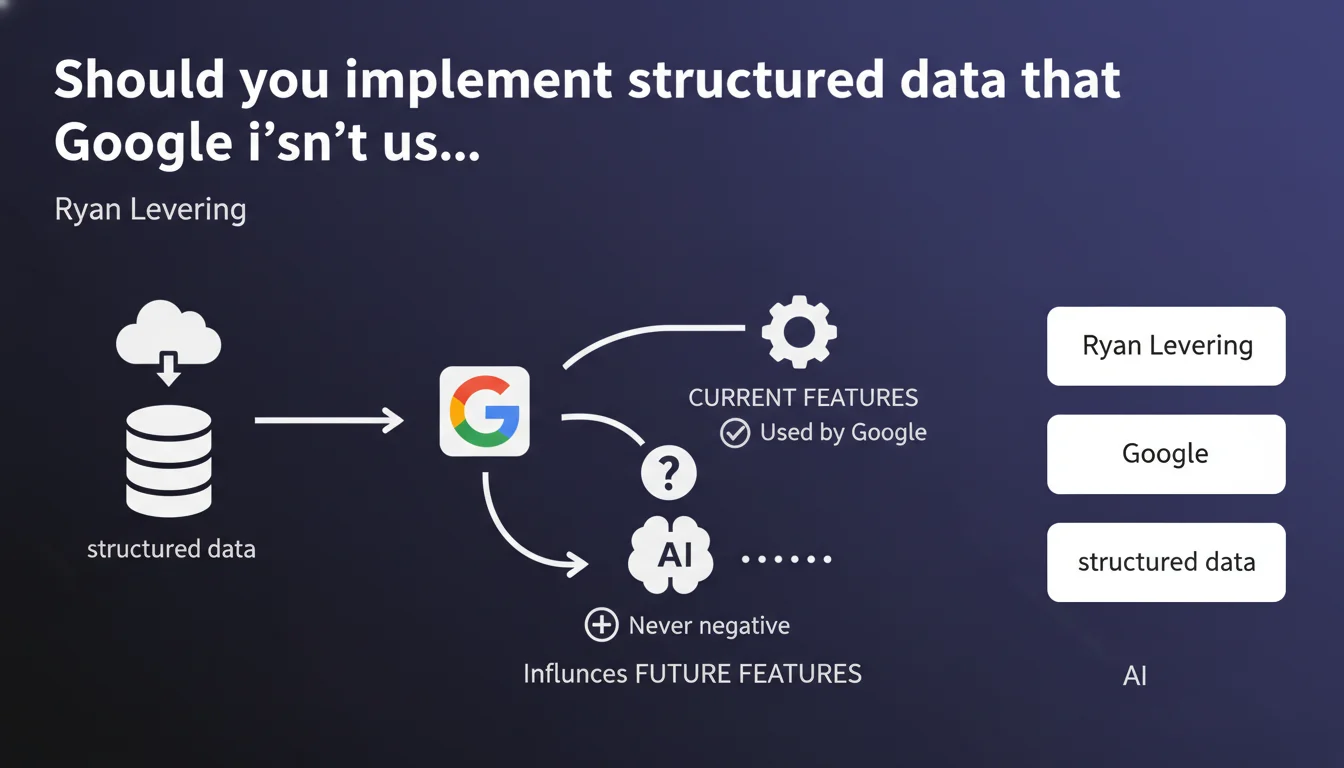
Google confirms that adding structured data not currently exploited has no negative effect. This data signals to Google the availability of these types at scale, which can influence the development of future Search features. Bottom line: broad markup costs nothing and can pay dividends tomorrow.
What you need to understand
Ryan Levering answers here a recurring question: is it worth spending time implementing schemas that generate no visible rich results today? The official answer is unambiguous — it's never counterproductive.
This statement fits into a product development logic at Google. The search engine detects the volumes of structured data available on the Web to prioritize its feature roadmaps.
Why does Google encourage data it isn't using yet?
The mechanism is simple: Google develops new features based on the availability and quality of structured data in its index. If 3% of the Web has marked up one type of content versus 40% for another, guess which one will be prioritized for a new rich snippet.
In short, you vote with your code. The more widespread a schema is, the more reason Google has to exploit it in the SERP.
What types of structured data are involved?
All Schema.org types supported by Google but without a dedicated feature currently. For example: MedicalEntity, Course (outside carousel), SoftwareApplication (outside mobile app), EducationalOccupationalCredential, and dozens of others.
Google maintains an official list of supported types — but supported doesn't mean displayed. That's the whole nuance.
- No risk of penalty in marking up content even if Google doesn't display it
- Unexploited data is crawled, indexed, and serves as a statistical signal to Google
- It's a bet on the future: you're in pole position if Google launches a feature tomorrow
- The technical cost is marginal if you're already using JSON-LD on your templates
Does this logic apply to all websites?
Yes, but with discernment. An e-commerce site has an interest in marking up Product even without a rich snippet — a personal blog with 10 articles per year can focus on Article and BreadcrumbList.
The priority remains to correctly implement schemas that generate active features (FAQ, HowTo, Product, Recipe, etc.). Schemas in « dormant » status come second, not as absolute priority.
SEO Expert opinion
Is this statement consistent with field observations?
Absolutely. We've observed for years that Google tests features on verticals where structured data is already massive. Recipe carousels emerged because millions of sites had already marked up their recipes.
Conversely, niche schemas like SpecialAnnouncement (launched for COVID) struggle to gain traction due to lack of critical volume. Google doesn't develop features in a vacuum.
What nuances should be added?
Levering says « never negative, » but watch out for markup errors. Malformed JSON-LD, missing required properties, or misleading markup can trigger manual actions or degrade algorithmic trust.
The principle is: mark up broadly, yes — but mark up correctly. An incomplete or fanciful schema is worse than no schema at all.
In what cases does this logic not apply?
If your technical budget is limited, focus on schemas with immediate ROI. Marking up Product with reviews and pricing for e-commerce takes priority over EducationalOccupationalCredential.
Another case: proprietary schemas not supported by Google. Inventing your own types outside Schema.org is strictly useless for Search, even if semantically valid.
Practical impact and recommendations
What should you do concretely?
Audit your content and identify Schema.org types that faithfully describe your offering, even without an active Google feature. E-learning? Mark up Course. SaaS? SoftwareApplication. Media? Complete VideoObject.
Implement in clean JSON-LD, test with the Rich Results Test and Search Console. No critical errors tolerated.
What errors should you avoid?
Don't over-mark. A blog post isn't a Product, a fake FAQ for keyword stuffing will be detected. Google values semantic relevance, not markup volume.
Also avoid duplicating the same data across multiple conflicting schemas on the same page. A product can't be simultaneously an Article and an Event — choose the primary type.
- List all content types on your site (products, articles, videos, courses, etc.)
- Identify corresponding Schema.org types, Google feature or not
- Implement in JSON-LD with all required + recommended properties
- Validate via Rich Results Test and fix any errors
- Monitor Search Console to detect warnings
- Document your markup choices to maintain consistency over time
How do you prioritize if resources are limited?
Start with schemas with immediate ROI: those generating rich results today (FAQ, Product, Recipe, HowTo, etc.). Then gradually extend to dormant schemas on your strategic content.
A Screaming Frog or OnCrawl crawler can automate detection of unmarked content. Then prioritize by traffic and business objectives.
❓ Frequently Asked Questions
Les données structurées inutilisées comptent-elles dans le ranking ?
Combien de temps avant que Google exploite un nouveau type de schema ?
Faut-il baliser tous les schemas Schema.org disponibles ?
Les schemas sans feature Google apparaissent-ils dans la Search Console ?
Un schema mal implémenté peut-il pénaliser mon site ?
🎥 From the same video 13
Other SEO insights extracted from this same Google Search Central video · published on 07/04/2022
🎥 Watch the full video on YouTube →
💬 Comments (0)
Be the first to comment.