Declaration officielle
Autres déclarations de cette vidéo 13 ▾
- □ Pourquoi Google préfère-t-il les données structurées au machine learning pour comprendre vos pages ?
- □ Faut-il encore se fatiguer avec les données structurées si le machine learning fait le boulot ?
- □ Google vérifie-t-il réellement l'exactitude de vos données structurées ?
- □ Pourquoi Google recommande-t-il de commencer par les données structurées génériques ?
- □ Pourquoi votre Schema.org valide peut être rejeté par Google ?
- □ Faut-il implémenter des données structurées même si Google ne les utilise pas encore ?
- □ Les données structurées influencent-elles vraiment la compréhension du sujet d'une page par Google ?
- □ Les données structurées sont-elles vraiment utiles si Google comprend déjà votre page ?
- □ Faut-il vraiment bourrer vos pages de données structurées pour mieux ranker ?
- □ Faut-il abandonner JSON-LD au profit de Microdata pour les données structurées ?
- □ Le JSON-LD externe pose-t-il vraiment des problèmes de synchronisation pour Google ?
- □ Les outils de test Google sont-ils vraiment fiables pour détecter vos données structurées manquantes ?
- □ Les données structurées doivent-elles systématiquement refléter le contenu visible de la page ?
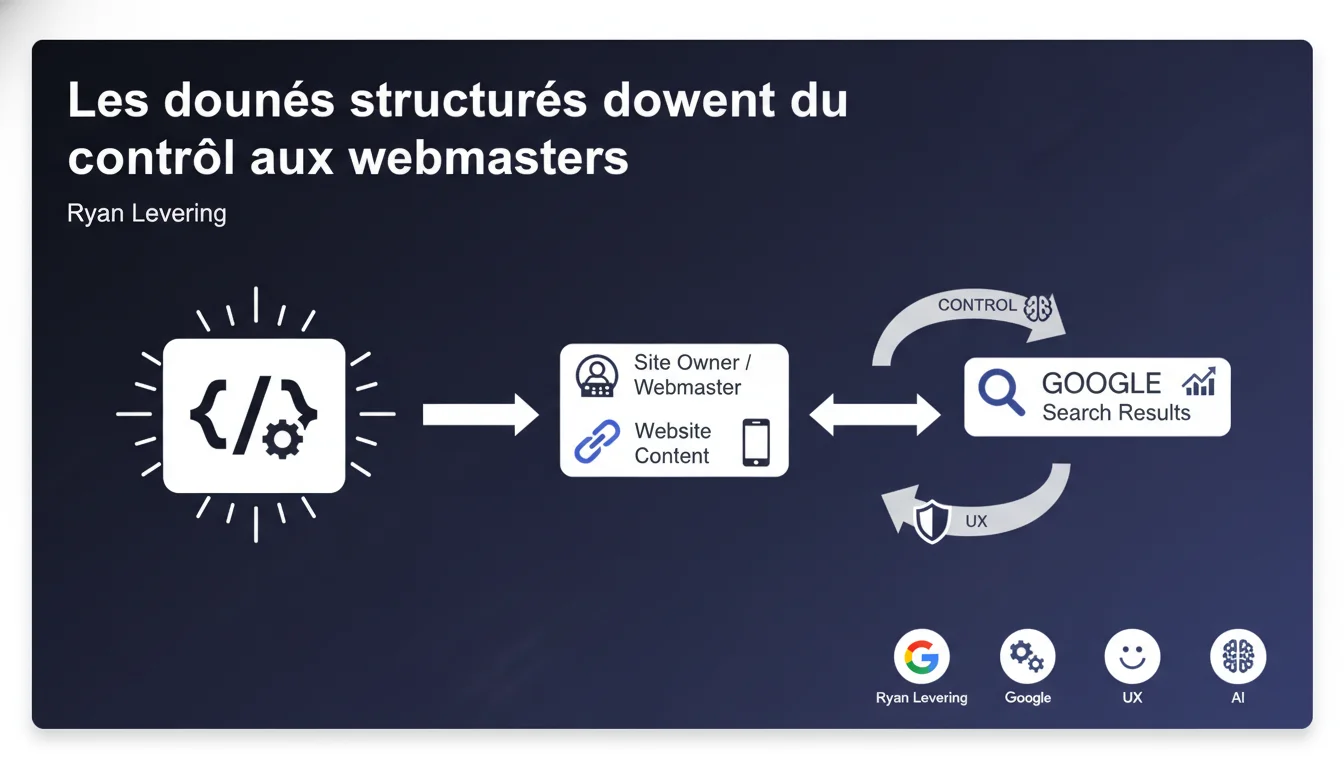
Google affirme que les données structurées permettent aux propriétaires de sites de contrôler le contenu affiché dans les résultats de recherche. C'est présenté comme un outil stratégique pour maîtriser la représentation de ses données. Reste à savoir jusqu'où ce « contrôle » s'étend réellement.
Ce qu'il faut comprendre
Que veut dire Google par « contrôle » exactement ?
Google suggère que l'implémentation de données structurées offre aux webmasters une forme de contrôle sur la manière dont leur contenu apparaît dans les SERP. Concrètement, en balisant correctement vos pages avec Schema.org, vous indiquez à Google quelles informations privilégier pour générer des rich snippets, knowledge panels ou autres formats enrichis.
Le terme « contrôle » mérite cependant d'être nuancé. Vous ne dictez pas à Google ce qu'il doit afficher — vous lui suggérez des données structurées qu'il peut choisir d'utiliser ou d'ignorer. Le moteur reste maître de la décision finale, notamment si vos données sont jugées peu pertinentes ou manipulatrices.
Pourquoi Ryan Levering insiste sur « la stratégie globale » ?
Cette mention n'est pas anodine. Les données structurées ne fonctionnent pas en silo. Elles doivent s'intégrer dans une architecture d'information cohérente : hiérarchie des contenus, maillage interne, pertinence sémantique.
Si vos balises Schema.org contredisent le contenu visible ou si elles sont incohérentes d'une page à l'autre, Google les ignorera probablement. Le « contrôle » n'existe que si la fondation technique et éditoriale est solide.
Quelle est la dimension politique de cette déclaration ?
Levering souligne que les propriétaires doivent « pouvoir contrôler leurs données ». C'est une formulation qui fait écho aux débats sur la propriété des contenus et l'utilisation des données par les grandes plateformes.
En offrant ce levier de contrôle via Schema.org, Google répond indirectement aux critiques sur l'extraction de contenu sans contrepartie. C'est aussi un argument face aux régulateurs : « nous donnons les outils, les webmasters décident ».
- Les données structurées permettent de guider l'affichage dans les SERP, pas de l'imposer
- Google reste juge final de la pertinence et peut ignorer vos balises Schema
- L'efficacité des données structurées dépend de la cohérence globale du site
- Cette approche répond aussi à des enjeux politiques autour de la propriété des contenus
Avis d'un expert SEO
Cette promesse de « contrôle » est-elle cohérente avec la réalité terrain ?
Partiellement. Les données structurées fonctionnent bien pour des cas d'usage précis : événements, recettes, produits, FAQ. Dans ces contextes, l'implémentation correcte génère effectivement des rich snippets prévisibles.
Mais le « contrôle » s'effrite dès qu'on sort de ces formats standardisés. Sur des contenus éditoriaux complexes, Google extrait souvent ce qu'il veut, ignorant vos Article ou NewsArticle au profit de son propre parsing. Les featured snippets, par exemple, ne dépendent presque jamais des données structurées — Google les génère algorithmiquement. [A vérifier] dans quelle mesure les balises Speakable ou HowTo influencent réellement l'affichage.
Quand ce « contrôle » devient-il illusoire ?
Dès que Google détecte une sur-optimisation ou des données non conformes au contenu visible. J'ai vu des dizaines de sites perdre leurs rich snippets après avoir tenté de manipuler les balises — prix gonflés dans Product, avis fictifs dans Review, dates d'événements incohérentes.
Le vrai problème : Google ne vous prévient pas toujours. Vos balises peuvent être techniquement valides selon le validateur, mais simplement ignorées en production. Vous croyez avoir du contrôle, vous n'avez qu'une fausse impression de maîtrise.
Faut-il y voir une reconnaissance de responsabilité de Google ?
Levering parle de « permettre aux gens de contrôler leurs données » dans un contexte où les plateformes sont accusées d'aspirer du contenu sans contrepartie. C'est une position défensive habile : « nous donnons les outils, à vous de les utiliser ».
Mais dans les faits, ce transfert de responsabilité signifie aussi que si votre contenu est mal représenté dans les SERP et que vous n'avez pas balisé correctement, c'est votre faute, pas celle de Google. Un renversement de charge assez malin.
Impact pratique et recommandations
Quelles données structurées méritent vraiment un investissement ?
Concentrez-vous sur les formats à ROI prouvé : Product pour l'e-commerce, Recipe si vous êtes dans la food, Event pour tout ce qui a une date, Organization et LocalBusiness pour votre entité. FAQ et HowTo ont un impact variable selon les niches — testez sur des pages clés avant de déployer massivement.
Les balises Article et NewsArticle ? Implémentez-les proprement pour l'écosystème Google News et Discover, mais n'en attendez pas de miracle sur la recherche classique. Le temps investi sur BreadcrumbList est en revanche toujours rentable : ça structure la navigation et améliore les fils d'Ariane dans les SERP.
Comment vérifier que vos données structurées sont réellement utilisées ?
Le validateur de Google vous dit si votre code est syntaxiquement correct, pas si Google l'utilise. Pour ça, il faut monitorer les SERP réelles : cherchez vos pages avec leurs requêtes cibles et vérifiez l'affichage effectif.
Utilisez le rapport « Améliorations » dans Search Console pour suivre les erreurs, mais aussi les variations de couverture. Si Google détecte 150 produits avec balises Product puis soudain 80, c'est qu'il ignore 70 pages — cherchez pourquoi.
- Auditez l'existant avec Screaming Frog ou OnCrawl pour identifier les pages sans données structurées
- Priorisez les formats à fort impact : Product, FAQ, LocalBusiness, BreadcrumbList
- Testez chaque implémentation avec le Rich Results Test avant déploiement
- Vérifiez la cohérence entre contenu visible et contenu balisé — toute divergence sera sanctionnée
- Monitorez les SERP réelles, pas seulement les validateurs
- Suivez le rapport Search Console « Améliorations » pour détecter les rejets silencieux
- Documentez vos choix de balisage pour maintenir la cohérence à long terme
❓ Questions frequentes
Les données structurées améliorent-elles directement le classement dans Google ?
Pourquoi mes données structurées valides ne génèrent-elles pas de rich snippets ?
Faut-il implémenter tous les types de Schema.org disponibles ?
Les données structurées en JSON-LD sont-elles préférables aux microdonnées ?
Comment savoir si Google utilise réellement mes données structurées ?
🎥 De la même vidéo 13
Autres enseignements SEO extraits de cette même vidéo Google Search Central · publiée le 07/04/2022
🎥 Voir la vidéo complète sur YouTube →
💬 Commentaires (0)
Soyez le premier à commenter.