Declaration officielle
Autres déclarations de cette vidéo 13 ▾
- □ Pourquoi Google préfère-t-il les données structurées au machine learning pour comprendre vos pages ?
- □ Faut-il encore se fatiguer avec les données structurées si le machine learning fait le boulot ?
- □ Les données structurées donnent-elles vraiment du contrôle aux webmasters sur l'affichage Google ?
- □ Google vérifie-t-il réellement l'exactitude de vos données structurées ?
- □ Pourquoi Google recommande-t-il de commencer par les données structurées génériques ?
- □ Pourquoi votre Schema.org valide peut être rejeté par Google ?
- □ Faut-il implémenter des données structurées même si Google ne les utilise pas encore ?
- □ Les données structurées influencent-elles vraiment la compréhension du sujet d'une page par Google ?
- □ Les données structurées sont-elles vraiment utiles si Google comprend déjà votre page ?
- □ Faut-il vraiment bourrer vos pages de données structurées pour mieux ranker ?
- □ Faut-il abandonner JSON-LD au profit de Microdata pour les données structurées ?
- □ Le JSON-LD externe pose-t-il vraiment des problèmes de synchronisation pour Google ?
- □ Les outils de test Google sont-ils vraiment fiables pour détecter vos données structurées manquantes ?
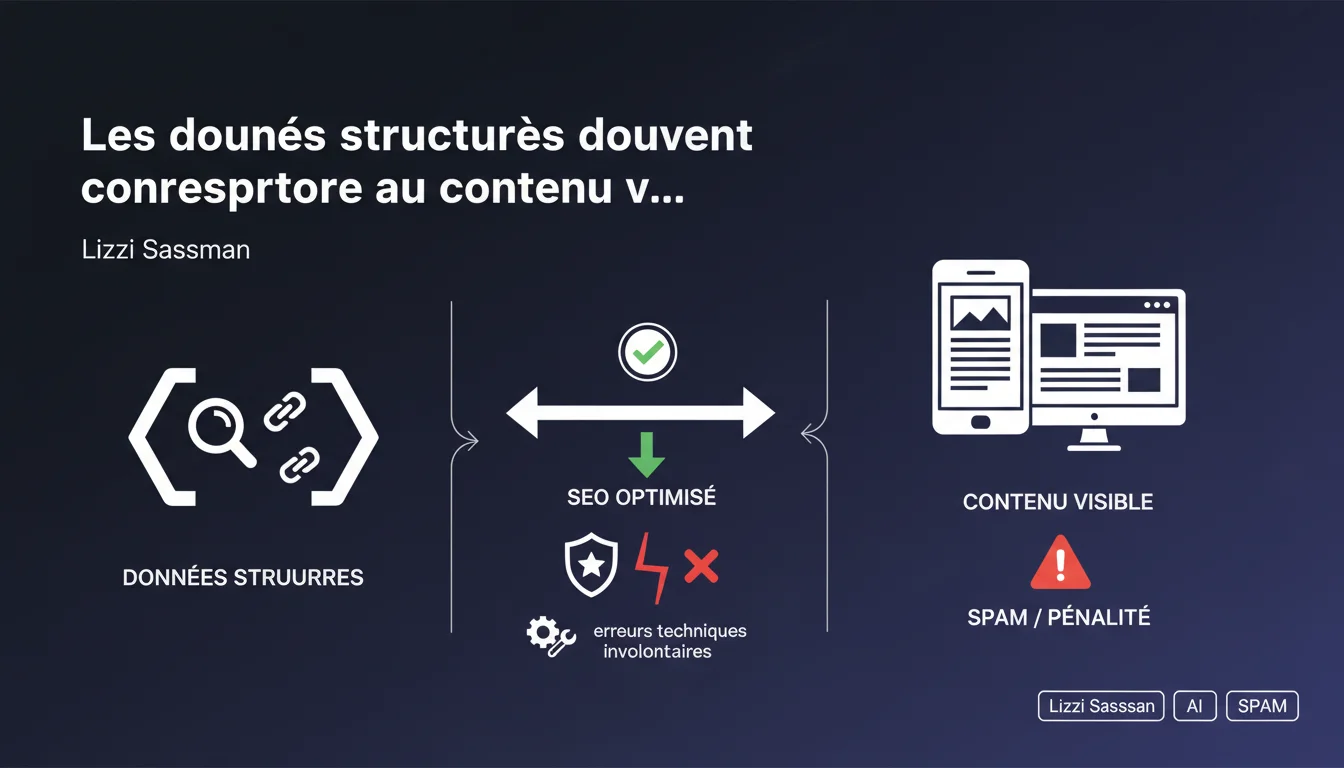
Google exige que les données structurées correspondent strictement au contenu visible de la page, sous peine d'être considérées comme du spam. Cette règle vise à éviter les manipulations, mais Google tolère les erreurs techniques involontaires. La frontière entre erreur et abus reste floue.
Ce qu'il faut comprendre
Pourquoi Google impose-t-elle cette correspondance stricte ?
Google cherche à combattre les abus de schema markup où des sites ajoutent des données structurées pour afficher des résultats enrichis sans que le contenu correspondant soit réellement présent sur la page. Un exemple classique : injecter des avis 5 étoiles en schema.org alors qu'aucun système d'avis n'existe sur le site.
Cette exigence figure noir sur blanc dans les guidelines officielles sur les données structurées. L'objectif est de garantir que les snippets enrichis dans les SERP reflètent fidèlement ce que l'utilisateur trouvera une fois sur la page.
Qu'est-ce qui compte comme « contenu visible » exactement ?
La notion de contenu visible semble simple, mais elle cache des zones grises importantes. Un contenu caché derrière un onglet JavaScript est-il visible ? Un prix affiché uniquement après sélection d'une variante produit ?
Google ne détaille pas précisément où se situe la limite. La déclaration de Lizzi Sassman reste volontairement générale, ce qui laisse une marge d'interprétation — et donc de risque.
Quelle différence entre erreur technique et manipulation volontaire ?
Google affirme tolérer les erreurs techniques involontaires, mais ne précise pas comment son algorithme distingue une erreur honnête d'une tentative de manipulation. Cette ambiguïté est problématique pour les praticiens.
Concrètement ? Un décalage ponctuel causé par un bug de mise à jour CMS sera-t-il traité différemment d'un schema markup systématiquement gonflé ? La déclaration ne répond pas.
- Les données structurées doivent correspondre au contenu réellement présent sur la page
- Tout écart peut être interprété comme du spam selon les guidelines
- Google tolère officiellement les erreurs involontaires, sans préciser les critères de distinction
- La zone grise autour de la notion de « visible » reste importante
- Les sites risquent des actions manuelles ou une perte de résultats enrichis
Avis d'un expert SEO
Cette déclaration apporte-t-elle vraiment de la clarté ?
Soyons honnêtes : cette communication ne change rien. L'exigence de correspondance entre schema markup et contenu visible figure dans les guidelines depuis des années. Lizzi Sassman rappelle une règle existante sans apporter de précision nouvelle.
Le problème, c'est que les cas limites restent sans réponse. Qu'en est-il des contenus chargés en AJAX après interaction utilisateur ? Des informations présentes en version mobile mais absentes en desktop ? [À vérifier] : Google n'a jamais publié de critères précis pour trancher ces situations.
L'argument des « erreurs involontaires » tient-il la route ?
Google prétend faire la différence entre erreur technique et manipulation. Sur le terrain, cette distinction est impossible à automatiser de manière fiable. Comment un algorithme peut-il déterminer l'intention derrière un décalage de données ?
Résultat : soit Google bluff et applique la règle de manière binaire, soit les actions manuelles sont nécessaires pour trancher — ce qui signifie que seuls les gros sites visibles seront réellement scrutés. Les petits sites avec des erreurs légitimes risquent d'être pénalisés automatiquement.
Quelles sont les limites pratiques de cette règle ?
Certains types de schema markup posent des problèmes structurels. Prenez le schema Recipe : faut-il afficher l'intégralité de la liste d'ingrédients en texte visible, ou une version JSON-LD suffit-elle si les ingrédients apparaissent dans un tableau interactif ?
Google ne tranche pas. Les webmasters sont coincés entre respecter une interprétation stricte qui alourdit l'UX, ou prendre un risque calculé avec une implémentation plus souple. La déclaration de Sassman n'aide pas à arbitrer ces dilemmes.
Impact pratique et recommandations
Comment vérifier la conformité de vos données structurées ?
Premier réflexe : comparer systématiquement votre schema markup au contenu effectivement affiché. Utilisez le Rich Results Test de Google et confrontez les données extraites avec ce qu'un utilisateur voit réellement sur la page.
Ne vous fiez pas uniquement aux outils automatiques — faites une vérification manuelle sur un échantillon représentatif de pages. Les décalages les plus problématiques concernent souvent des détails : une date de publication légèrement différente, un prix affiché hors taxe en schema mais TTC en visible, etc.
Quelles erreurs éviter absolument ?
Ne jamais ajouter de données structurées pour du contenu absent de la page. C'est la manipulation la plus flagrante et la plus risquée. Si vous n'affichez pas d'avis clients, ne mettez pas de schema AggregateRating.
Méfiez-vous également des contenus conditionnels : si un prix n'apparaît qu'après sélection d'une variante, votre schema Product doit refléter cette logique, pas afficher un prix par défaut potentiellement trompeur.
- Auditer toutes les pages avec données structurées (schema.org, JSON-LD, microdata)
- Comparer le contenu du markup avec le contenu visible pour un humain
- Supprimer tout schema markup pour du contenu non présent sur la page
- Tester avec le Rich Results Test de Google et analyser les écarts
- Vérifier la cohérence entre versions mobile et desktop si les schemas diffèrent
- Documenter les choix d'implémentation pour les cas limites (contenus interactifs, onglets, etc.)
- Mettre en place un monitoring régulier pour détecter les dérives après mises à jour
❓ Questions frequentes
Un contenu caché derrière un onglet JavaScript peut-il être utilisé dans les données structurées ?
Que se passe-t-il si mes données structurées contiennent une erreur involontaire ?
Faut-il dupliquer tout le contenu visible en JSON-LD ou une synthèse suffit-elle ?
Les différences entre version mobile et desktop posent-elles problème ?
Peut-on perdre ses résultats enrichis à cause d'un écart mineur ?
🎥 De la même vidéo 13
Autres enseignements SEO extraits de cette même vidéo Google Search Central · publiée le 07/04/2022
🎥 Voir la vidéo complète sur YouTube →
💬 Commentaires (0)
Soyez le premier à commenter.