Official statement
Other statements from this video 29 ▾
- □ Un fichier robots.txt volumineux pénalise-t-il vraiment votre SEO ?
- □ Soumettre son sitemap dans robots.txt ou Search Console : y a-t-il vraiment une différence ?
- □ Les balises H1-H6 ont-elles encore un impact réel sur le classement Google ?
- □ Faut-il vraiment respecter une hiérarchie stricte des balises Hn pour le SEO ?
- □ Combien de temps faut-il réellement pour qu'une migration de domaine soit prise en compte par Google ?
- □ Une migration de site peut-elle vraiment booster votre SEO ou tout faire planter ?
- □ Googlebot crawle-t-il vraiment depuis un seul endroit pour indexer vos contenus géolocalisés ?
- □ Le noindex sur pages géolocalisées peut-il faire disparaître tout votre site des résultats Google ?
- □ Faut-il vraiment abandonner les redirections géolocalisées pour une simple bannière ?
- □ Faut-il créer des pages de destination pour chaque ville ou se limiter aux régions ?
- □ Faut-il rediriger les utilisateurs mobiles vers votre application mobile ?
- □ Faut-il vraiment traduire mot pour mot ses pages pour que le hreflang fonctionne ?
- □ Fichier Disavow : pourquoi la directive domaine permet-elle de contourner la limite de 2MB ?
- □ Faut-il vraiment utiliser le fichier Disavow uniquement pour les liens achetés ?
- □ Le HTML sémantique booste-t-il vraiment votre référencement naturel ?
- □ AMP est-il encore un critère de ranking dans Google Search ?
- □ AMP est-il vraiment un facteur de classement pour Google ?
- □ Supprimer AMP boost-t-il le crawl de vos pages classiques ?
- □ Faut-il tester la suppression de son fichier Disavow de manière incrémentale ?
- □ Pourquoi les panels de connaissance s'affichent-ils différemment selon les appareils ?
- □ Le système de synonymes de Google fonctionne-t-il vraiment sans intervention humaine ?
- □ Faut-il vraiment créer une page distincte par localisation pour le schema Local Business ?
- □ Faut-il vraiment marquer TOUT son contenu en données structurées ?
- □ Faut-il vraiment afficher toutes les questions du schema FAQ sur la page ?
- □ Le contenu masqué dans les accordéons peut-il vraiment apparaître dans les featured snippets ?
- □ Pourquoi Google ne veut-il pas indexer l'intégralité de votre site web ?
- □ Faut-il supprimer des pages pour améliorer l'indexation de son site ?
- □ Le volume de recherche des ancres influence-t-il vraiment la valeur d'un lien interne ?
- □ Faut-il vraiment ajouter du contenu unique sur vos pages produit en e-commerce ?
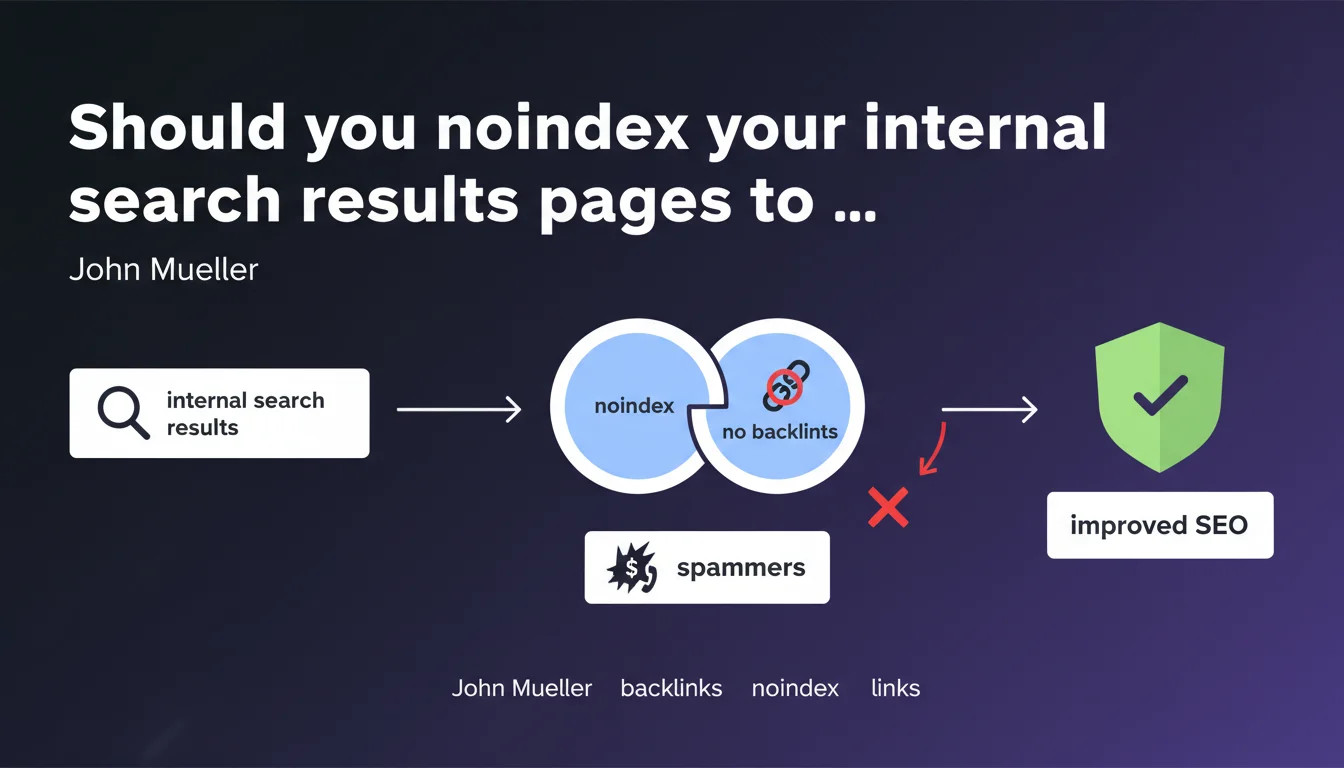
John Mueller recommends setting internal search results pages (or those with long query strings) to noindex to prevent spam sites from creating backlinks containing their phone numbers or URLs. A simple solution against a spam technique that exploits your internal search functionality to generate indexed pages containing their contact information.
What you need to understand
Malicious sites exploit the internal search engines of third-party websites to create indexable pages containing their own contact information. The mechanics are simple: they generate search URLs on your site that include their phone number or domain, then create backlinks to these pages.
Google indexes these results pages, and there you have it — the spammer gets an indexed page on a legitimate domain, with their number visible in the SERPs. It's pure parasitism.
Why do spammers specifically target internal search results pages?
Internal search results pages are dynamic and indexable by default on many sites. They generate unique content from the query, which can seem relevant to Google if the site doesn't block their indexation.
The spammer needs no backend access — they only need to manipulate the public URL of your search form. Once the page is created and crawled, it can rank in search results for queries including the spammer's number or domain.
What does it actually mean to noindex these pages?
The noindex directive prevents Google from including these pages in its index, even if they remain crawlable. Spammers can still create backlinks, but these links will lead to no indexed page — their strategy falls apart.
Mueller suggests two approaches: block all search results pages, or target only those containing long queries (often more likely to be spam). The second approach requires server-side detection.
- Internal search pages are often indexable by default
- Spammers exploit this loophole to create parasitic content
- Noindex stops this technique without requiring crawl blocking
- Two strategies: global noindex or conditional based on query length
SEO Expert opinion
Is this recommendation really sufficient for all sites?
For a typical e-commerce site or blog, yes — setting internal search results to noindex is a standard best practice. These pages rarely generate SEO value, they dilute crawl budget, and create duplicate content.
But be careful: some sites must index their search results. Classifieds aggregators, price comparison sites, job boards — their model relies on indexing combinations of filters. Blindly blocking can destroy their organic visibility.
Is long query detection really reliable against spam?
Let's be honest: it's a partial solution. Spammers can easily use short queries. A simple phone number is 10 characters — hard to define a universal threshold without false positives.
Real protection comes from server-side validation: detection of suspicious patterns (numbers, URLs), rate limiting on unique queries, or even CAPTCHA on search. Noindex addresses the symptom, not the cause. [To verify]: no public data shows whether this spam technique is truly widespread or just a marginal case Mueller encountered.
Does Google penalize sites that are victims of this backlink spam?
Nothing in Mueller's statement suggests the host site risks a penalty. The problem is the pollution of your index and dilution of crawl budget — not a direct algorithmic risk.
The spam backlinks themselves are normally ignored by Google through link filtering. But having hundreds of indexed pages with parasitic content degrades user experience and can affect how algorithms perceive your site's quality.
Practical impact and recommendations
What exactly should you do to block this exploitation?
First step: check if your internal search pages are currently indexed. A site:yourdomain.com inurl:search query (or equivalent to your URL pattern) in Google will give you the answer.
If they are, set them to noindex via the meta robots tag or the X-Robots-Tag HTTP header. Add a rule in your CMS or server to apply noindex to all search results URLs.
If you want to be more selective, implement conditional logic: noindex only if the query exceeds X characters, contains suspicious patterns (regex for phone numbers, URLs), or if the user isn't authenticated.
- Audit current indexation of your internal search pages
- Add a
<meta name="robots" content="noindex, follow">tag to these pages - Verify that noindex is present in rendered source code (not blocked by JavaScript)
- Monitor Search Console to confirm gradual deindexation
- Implement suspicious pattern detection if you want conditional noindex
- Keep crawl allowed (follow) to avoid breaking internal linking if these pages link to indexable content
Mueller's solution is pragmatic and low-risk for most sites. Noindex on internal search results protects against a parasitic spam form without affecting your legitimate SEO — provided these pages aren't already generating organic traffic.
For complex sites with filter architectures or millions of pages, implementation may require thorough analysis. A misconfiguration could deindex entire sections. In these cases, guidance from a specialized SEO agency helps avoid mistakes and adapt the strategy to your specific editorial model.
❓ Frequently Asked Questions
Le noindex empêche-t-il Google de crawler les pages de recherche interne ?
Dois-je aussi bloquer les pages de recherche dans le robots.txt ?
Cette technique de spam de backlinks affecte-t-elle mon autorité de domaine ?
Comment détecter si mon site est victime de ce type de spam ?
Faut-il supprimer les pages déjà indexées ou juste ajouter le noindex ?
🎥 From the same video 29
Other SEO insights extracted from this same Google Search Central video · published on 14/01/2022
🎥 Watch the full video on YouTube →
💬 Comments (0)
Be the first to comment.