Official statement
Other statements from this video 16 ▾
- □ Le crawl budget est-il vraiment négligeable pour votre site ?
- □ Faut-il publier plus souvent pour être crawlé plus régulièrement par Google ?
- □ Faut-il vraiment s'inquiéter de la duplication de contenu interne ?
- □ Le contenu récent bénéficie-t-il vraiment d'un boost de ranking automatique ?
- □ Le hreflang fonctionne-t-il vraiment page par page et non pour tout un site ?
- □ Comment Google mesure-t-il réellement la Page Experience dans son algorithme ?
- □ Chrome et Analytics influencent-ils vraiment le classement Google ?
- □ Le hreflang modifie-t-il vraiment le ranking ou se contente-t-il de permuter les URLs ?
- □ Faut-il vraiment choisir entre redirection 301 et canonical pour une migration ?
- □ Top Stories sans AMP : faut-il encore optimiser la vitesse de vos pages ?
- □ Search Console compte-t-elle vraiment toutes vos impressions SEO ?
- □ Les URLs découvertes en JavaScript gaspillent-elles vraiment votre crawl budget ?
- □ Pourquoi Google refuse-t-il d'indexer certaines pages de votre site ?
- □ Faut-il supprimer les pages à faible trafic pour améliorer son SEO ?
- □ Les erreurs de balisage breadcrumb entraînent-elles une pénalité Google ?
- □ Le contenu unique booste-t-il vraiment le ranking global d'un site ?
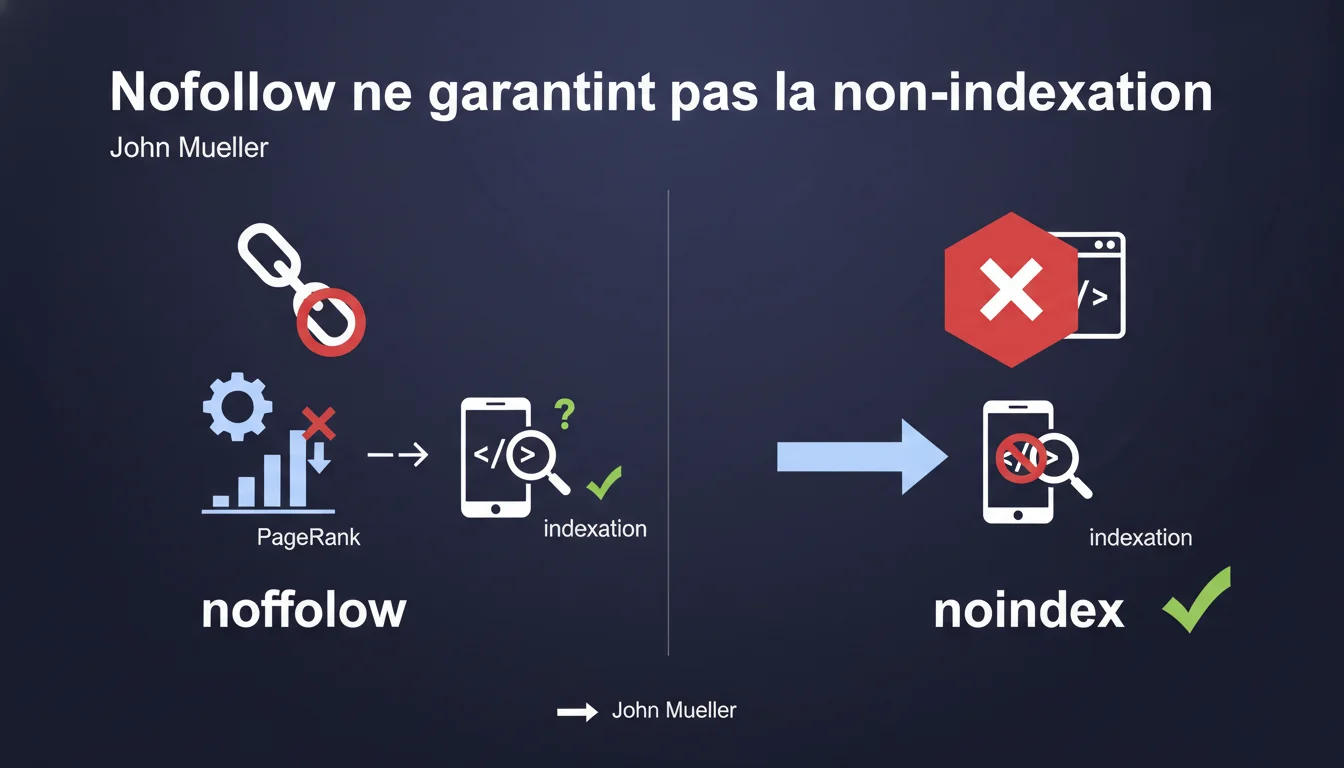
The rel='nofollow' attribute only blocks PageRank transmission, not indexing. If Google finds other pathways to a URL (external links, sitemaps, navigation), it may index it despite your internal nofollow links. To formally disallow indexing, only the noindex tag is binding.
What you need to understand
What is the real difference between nofollow and noindex?
The nofollow is an instruction meant for crawling and PageRank calculation — it tells Google not to follow this link to pass value, but it does not prevent the discovery or indexing of the target page.
The noindex, on the other hand, is an explicit indexing directive: it orders Google to never display this URL in search results, even if it has been crawled.
Why does Google index pages that are only pointed to by nofollow?
Because Google discovers URLs through multiple simultaneous channels: external links, XML sitemaps, browsing history, mentions on other sites. An internal nofollow link never completely isolates a page.
As soon as a URL is known and deemed relevant, Google may choose to index it — regardless of the nofollow attribute on internal links.
In what situations does this confusion cause issues?
Some SEOs still believe that adding rel='nofollow' to internal links is enough to block the indexing of sensitive pages (staging, faceted filters, intermediary pages). This is false and risky.
The result? Undesired URLs appear in the index, dilute crawl budget, create duplicate content, or expose technical pages never intended for the public.
- Nofollow = no transmission of PageRank via this link
- Noindex = formal prohibition from appearing in the SERPs
- Google can index a page even if all your internal links are nofollow
- To block indexing:
meta name="robots" content="noindex"tag or HTTP headerX-Robots-Tag: noindex - Nofollow does not protect against discovery from other sources (backlinks, sitemaps)
SEO Expert opinion
Does this statement correct a widespread practice?
Yes, and it should put an end to a misunderstanding that has persisted for several years. Many SEOs still use nofollow as an indexing management tool — likely due to confusion with the historical behavior of robots.txt.
But let's be honest: Google has said this several times, yet this practice continues. Why? Because some SEO tools display nofollow as a crawl budget optimization solution, which perpetuates the confusion.
Can we really trust noindex?
Noindex is the only binding instruction to block indexing, but Google must be able to access it. If you block a URL with robots.txt, Google cannot crawl the page and thus never sees the noindex tag — resulting in the URL potentially remaining in the index with an empty description.
This is a classic trap: robots.txt blocks the crawl, but not necessarily the presence in the index if the URL is known from elsewhere. [To be checked] in your own logs: do some URLs blocked in robots.txt still appear in Search Console?
What nuances should be added on the ground?
Nofollow is still useful for internal sculpting — directing PageRank to your strategic pages, avoiding wasting crawl budget on ancillary links. But it never replaces noindex for sensitive pages.
Practical impact and recommendations
What should you do practically on your site?
Audit all the pages you thought were protected by internal nofollow links. Check in Search Console if they appear in the index. If so, immediately add a noindex tag.
For technical pages, complex pagination, or filter variants — noindex is your only safeguard. Nofollow can complement this strategy but never replace it.
What mistakes should you absolutely avoid?
Never block any page you want to deindex in robots.txt. Google won’t be able to crawl the noindex tag, and the URL risks remaining visible in the SERPs with the mention “No information available”.
Don’t rely on nofollow to isolate test, staging, or confidential content pages. If an external backlink points to them, Google will index it — nofollow or not.
How can you check that your site is compliant?
- List all the URLs you never want to see indexed (admin, filters, duplicates)
- Check that they all have a noindex tag (meta or X-Robots-Tag)
- Ensure that these URLs are not blocked in robots.txt — otherwise Google will never see the noindex directive
- Run a crawl with Screaming Frog or Sitebulb to detect inconsistencies (internally nofollowed pages but indexable)
- Monitor Search Console for indexed URLs that shouldn’t be indexed
- Document your internal link management strategy: nofollow for sculpting, noindex for exclusion
❓ Frequently Asked Questions
Puis-je utiliser le nofollow pour empêcher Google d'indexer une page ?
Si tous mes liens internes vers une page sont en nofollow, sera-t-elle indexée ?
Faut-il bloquer en robots.txt les pages en noindex ?
Le nofollow a-t-il encore une utilité en SEO ?
Comment savoir si des pages non désirées sont indexées ?
🎥 From the same video 16
Other SEO insights extracted from this same Google Search Central video · published on 09/01/2022
🎥 Watch the full video on YouTube →
💬 Comments (0)
Be the first to comment.