Declaration officielle
Autres déclarations de cette vidéo 16 ▾
- □ Le crawl budget est-il vraiment négligeable pour votre site ?
- □ Faut-il publier plus souvent pour être crawlé plus régulièrement par Google ?
- □ Faut-il vraiment s'inquiéter de la duplication de contenu interne ?
- □ Le contenu récent bénéficie-t-il vraiment d'un boost de ranking automatique ?
- □ Le hreflang fonctionne-t-il vraiment page par page et non pour tout un site ?
- □ Comment Google mesure-t-il réellement la Page Experience dans son algorithme ?
- □ Chrome et Analytics influencent-ils vraiment le classement Google ?
- □ Le hreflang modifie-t-il vraiment le ranking ou se contente-t-il de permuter les URLs ?
- □ Faut-il vraiment choisir entre redirection 301 et canonical pour une migration ?
- □ Top Stories sans AMP : faut-il encore optimiser la vitesse de vos pages ?
- □ Search Console compte-t-elle vraiment toutes vos impressions SEO ?
- □ Les URLs découvertes en JavaScript gaspillent-elles vraiment votre crawl budget ?
- □ Pourquoi Google refuse-t-il d'indexer certaines pages de votre site ?
- □ Faut-il supprimer les pages à faible trafic pour améliorer son SEO ?
- □ Les erreurs de balisage breadcrumb entraînent-elles une pénalité Google ?
- □ Le contenu unique booste-t-il vraiment le ranking global d'un site ?
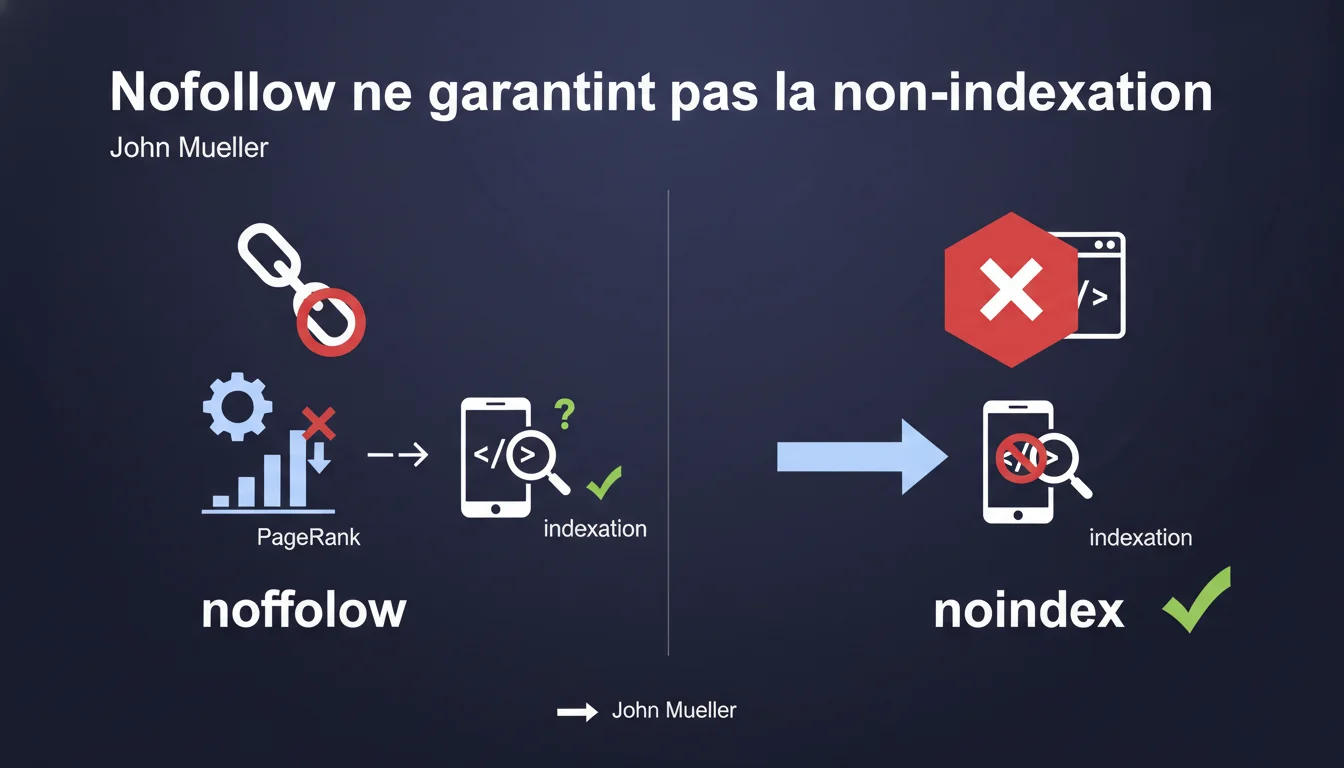
L'attribut rel='nofollow' bloque uniquement la transmission de PageRank, pas l'indexation. Si Google trouve d'autres chemins vers une URL (liens externes, sitemaps, navigation), il peut l'indexer malgré vos liens nofollow internes. Pour interdire formellement l'indexation, seule la balise noindex est contraignante.
Ce qu'il faut comprendre
Quelle est la différence réelle entre nofollow et noindex ?
Le nofollow est une instruction destinée au crawl et au calcul du PageRank — il indique à Google de ne pas suivre ce lien pour transmettre de la valeur, mais n'empêche en rien la découverte ou l'indexation de la page cible.
Le noindex, lui, est une directive d'indexation explicite : il ordonne à Google de ne jamais afficher cette URL dans les résultats de recherche, même si elle a été crawlée.
Pourquoi Google indexe-t-il des pages pointées uniquement en nofollow ?
Parce que Google découvre les URLs via plusieurs canaux simultanés : liens externes, sitemaps XML, historique de navigation, mentions sur d'autres sites. Un lien interne en nofollow n'isole donc jamais totalement une page.
Dès qu'une URL est connue et jugée pertinente, Google peut décider de l'indexer — indépendamment de l'attribut nofollow sur les liens internes.
Dans quels cas cette confusion pose-t-elle problème ?
Certains SEO pensent encore qu'ajouter rel='nofollow' sur des liens internes suffit à bloquer l'indexation de pages sensibles (staging, filtres à facettes, pages intermédiaires). C'est faux et risqué.
Le résultat ? Des URLs indésirables qui apparaissent dans l'index, diluent le crawl budget, créent du contenu dupliqué ou exposent des pages techniques jamais destinées au public.
- Nofollow = pas de transmission de PageRank via ce lien
- Noindex = interdiction formelle d'apparaître dans les SERP
- Google peut indexer une page même si tous vos liens internes sont en nofollow
- Pour bloquer l'indexation : balise
meta name="robots" content="noindex"ou en-tête HTTPX-Robots-Tag: noindex - Le nofollow ne protège pas contre la découverte par d'autres sources (backlinks, sitemaps)
Avis d'un expert SEO
Cette déclaration corrige-t-elle une pratique répandue ?
Oui, et elle devrait mettre fin à un malentendu vieux de plusieurs années. Beaucoup de SEO utilisent encore le nofollow comme un outil de gestion de l'indexation — probablement par confusion avec le comportement historique des robots.txt.
Mais soyons honnêtes : Google l'a déjà dit plusieurs fois, et pourtant cette pratique persiste. Pourquoi ? Parce que certains outils SEO affichent le nofollow comme une solution d'optimisation du crawl budget, ce qui entretient la confusion.
Peut-on vraiment faire confiance au noindex ?
Le noindex est la seule instruction contraignante pour bloquer l'indexation, mais encore faut-il que Google puisse y accéder. Si vous bloquez une URL en robots.txt, Google ne peut pas crawler la page et donc ne voit jamais la balise noindex — résultat, l'URL peut rester dans l'index avec une description vide.
C'est un piège classique : robots.txt bloque le crawl, mais pas nécessairement la présence dans l'index si l'URL est connue par ailleurs. [À vérifier] dans vos propres logs : certaines URLs bloquées en robots.txt apparaissent-elles quand même dans la Search Console ?
Quelles nuances faut-il apporter sur le terrain ?
Le nofollow reste utile pour le sculpting interne — orienter le PageRank vers vos pages stratégiques, éviter de gaspiller du crawl budget sur des liens annexes. Mais il ne remplace jamais le noindex pour les pages sensibles.
Impact pratique et recommandations
Que faut-il faire concrètement sur votre site ?
Auditez toutes les pages que vous pensiez protégées par des liens nofollow internes. Vérifiez dans la Search Console si elles apparaissent dans l'index. Si oui, ajoutez immédiatement une balise noindex.
Pour les pages techniques, de pagination complexe, ou les variantes de filtres — le noindex est votre seul rempart. Le nofollow peut compléter cette stratégie, mais jamais la remplacer.
Quelles erreurs éviter absolument ?
Ne bloquez jamais en robots.txt une page que vous voulez désindexer. Google ne pourra pas crawler la balise noindex et l'URL risque de rester visible dans les SERP avec la mention « Aucune information disponible ».
Ne comptez pas sur le nofollow pour isoler des pages de test, de staging ou des contenus confidentiels. Si un backlink externe pointe dessus, Google l'indexera — nofollow ou pas.
Comment vérifier que votre site est conforme ?
- Listez toutes les URLs que vous ne voulez jamais voir indexées (admin, filtres, doublons)
- Vérifiez qu'elles portent toutes une balise noindex (meta ou X-Robots-Tag)
- Assurez-vous que ces URLs ne sont pas bloquées en robots.txt — sinon Google ne verra jamais la directive noindex
- Lancez un crawl avec Screaming Frog ou Sitebulb pour détecter les incohérences (pages en nofollow interne mais indexables)
- Surveillez la Search Console pour repérer les URLs indexées qui ne devraient pas l'être
- Documentez votre stratégie de gestion des liens internes : nofollow pour le sculpting, noindex pour l'exclusion
❓ Questions frequentes
Puis-je utiliser le nofollow pour empêcher Google d'indexer une page ?
Si tous mes liens internes vers une page sont en nofollow, sera-t-elle indexée ?
Faut-il bloquer en robots.txt les pages en noindex ?
Le nofollow a-t-il encore une utilité en SEO ?
Comment savoir si des pages non désirées sont indexées ?
🎥 De la même vidéo 16
Autres enseignements SEO extraits de cette même vidéo Google Search Central · publiée le 09/01/2022
🎥 Voir la vidéo complète sur YouTube →
💬 Commentaires (0)
Soyez le premier à commenter.