Official statement
Other statements from this video 11 ▾
- □ Googlebot est-il vraiment un seul programme ou une infrastructure distribuée ?
- □ Le crawl Google fonctionne-t-il vraiment par API avec des paramètres configurables ?
- □ Pourquoi Google ne documente-t-il pas tous ses crawlers dans sa liste officielle ?
- □ Crawlers vs Fetchers : pourquoi Google utilise-t-il deux systèmes distincts pour accéder à vos pages ?
- □ Google réutilise-t-il vraiment le cache entre ses différents crawlers ?
- □ Pourquoi Google ne crawle-t-il pas massivement votre contenu géobloqué ?
- □ Pourquoi le géoblocage peut-il nuire au crawl de votre site par Google ?
- □ Le crawl budget est-il vraiment protégé automatiquement par Google ?
- □ Pourquoi Google impose-t-il une limite de 15 Mo par page crawlée ?
- □ Pourquoi Google impose-t-il une limite de 2 Mo pour crawler vos pages web ?
- □ Pourquoi Google limite-t-il le crawl des PDFs à 64 Mo alors que le HTML plafonne à 2 Mo ?
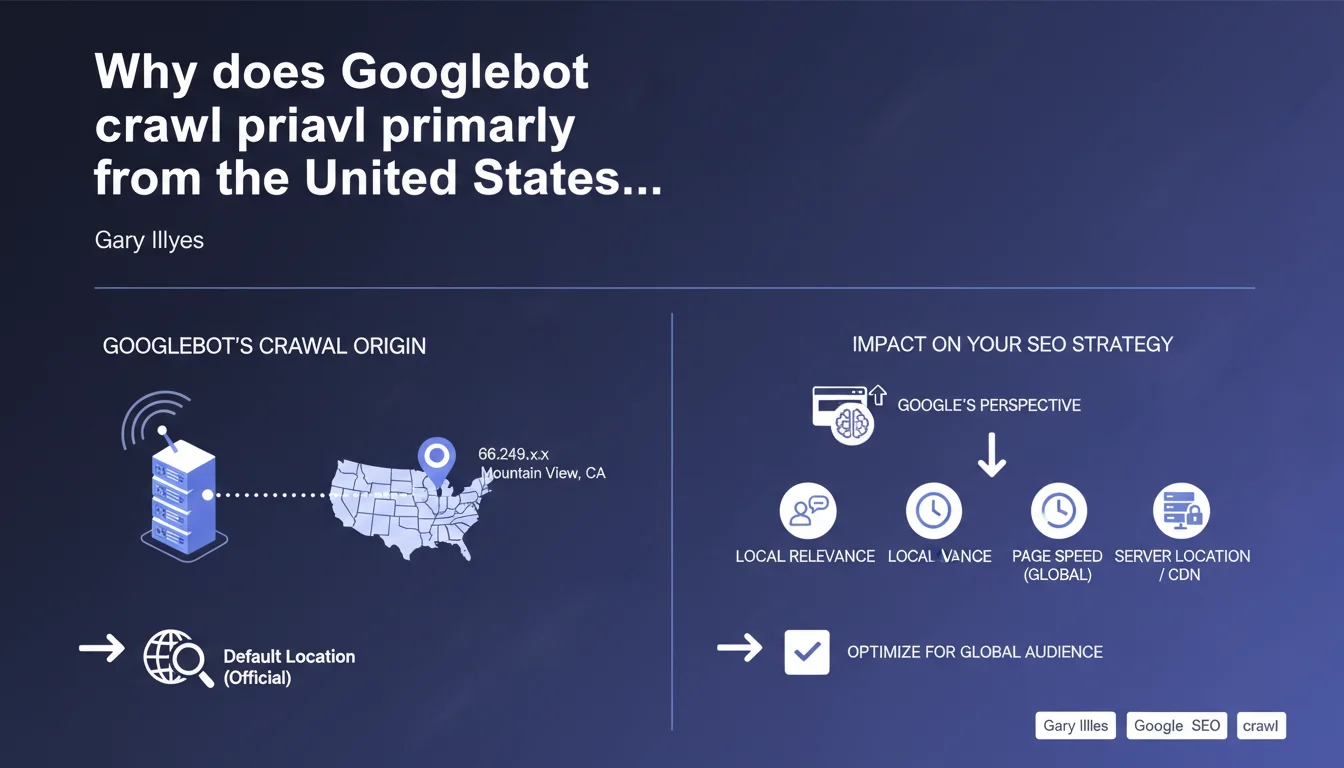
Googlebot primarily uses American IP addresses (66.249.x.x) based in Mountain View, California. This default crawl location has direct implications for server geolocation, geo-targeted content detection, and international optimization strategies.
What you need to understand
What does this statement reveal about Googlebot's technical operation?
Gary Illyes confirms that Googlebot primarily uses American IP addresses to crawl the web. These IPs start with 66.249 (not 66.129 as sometimes mistakenly mentioned) and are geographically assigned to Mountain View, California — Google's headquarters.
In practical terms? When your server receives a crawl request, it comes in the vast majority of cases from an infrastructure located in the United States. This default configuration applies regardless of which Google version is targeted (Google.fr, Google.de, Google.co.uk, etc.).
Does this location impact how Google accesses my content?
Yes, and this is where problems can arise. If your site applies IP-based geo-restriction or automatic redirection based on geographic origin, Googlebot will see the American version or the default version. Not the one you intended for your French, German, or Japanese users.
CDNs configured to serve different content based on geographic location can also cause issues. Googlebot risks crawling a non-optimized version or encountering different latencies than your actual end users.
Does Google use other locations to crawl?
Officially, Mountain View remains the documented default location. However, Google has crawling infrastructure distributed worldwide for specific cases — particularly to test regional availability or validate geo-targeted content.
These secondary crawls remain minimal and are not the norm. The bulk of Googlebot traffic genuinely comes from California IP addresses, which explains why your server logs show this origin overwhelmingly.
- Googlebot IP addresses: Primarily 66.249.x.x, assigned to Mountain View, California
- Impact on crawling: Geo-restrictions and IP-based redirections affect which version of content Googlebot indexes
- CDN and latency: Geographic CDN configuration can create gaps between user experience and what the bot sees
- Secondary crawls: Google occasionally uses other locations, but this remains the exception
SEO Expert opinion
Does this statement align with real-world observations?
Absolutely. Analysis of server logs confirms that 90% to 95% of Googlebot traffic genuinely comes from the 66.249.x.x IP ranges. Log files I've examined across international sites show this trend consistently.
The nuance — and it's an important one — is that Google can occasionally use other sources for regional availability tests or to validate hreflang configurations. These crawls are anecdotal but do exist, particularly for sites with strong geographic components.
What are the real implications for international SEO?
Let's be honest: if you're relying on automatic geolocation detection to serve the right content, you're heading straight for disaster. Googlebot will see the American version or the default one, not the one intended for your target markets.
Hreflang tags remain the only reliable method to tell Google which language version and geographic version corresponds to which audience. IP-based redirections? Googlebot ignores them or treats them as potential cloaking. [To be verified]: Google has never precisely documented how it handles these redirections in all scenarios, but real-world feedback is unequivocal — it doesn't work as intended.
Does the CDN become a critical factor in this context?
More than ever. If your CDN serves different content based on IP geolocation, you're creating a divergence between what Googlebot indexes and what your users see. This inconsistency can impact your rankings, especially since Core Web Vitals now incorporate actual user experience.
The solution? Configure your CDN to serve the same content to Googlebot as to your users, relying on User-Agent rather than IP geolocation. And test your loading times from the United States — that's what Googlebot measures by default.
Practical impact and recommendations
How do I adapt my server and CDN configuration?
First step: audit your server logs to identify Googlebot IP ranges and verify that no firewall or geo-blocking rules affect them. The 66.249.x.x IPs must have full and fast access to your content.
Configure your CDN to serve content based on User-Agent, not IP geolocation. If you use Cloudflare, Akamai, or Fastly, create specific rules for Googlebot that bypass automatic geographic redirections.
What should I verify for international sites?
Systematically test your hreflang tags — they must be present, correct, and consistent across all language versions of your site. Google Search Console alerts you to errors, but a crawl with Screaming Frog from a US IP often reveals problems that are otherwise invisible.
Validate that your 301/302 redirections don't create loops or inconsistencies for Googlebot. A redirection based on IP that systematically sends an American bot to a .com version while your hreflang points to localized versions? That's a contradictory signal that disrupts indexation.
What critical mistakes should you absolutely avoid?
Never block American IPs on principle, even if your site exclusively targets a European or Asian market. You're cutting off access to the majority of Googlebot traffic. If you must apply geographic restrictions for legal reasons, create an explicit exception for verified Googlebot User-Agent.
Avoid configurations that serve radically different content based on geographic origin without a bot detection mechanism. Google may consider this cloaking, especially if the gap between the crawled version and the user version is significant.
- Verify that 66.249.x.x IPs are not blocked by firewall or WAF
- Configure CDN to serve content based on User-Agent, not IP geolocation
- Audit hreflang tags across all language versions of your site
- Test loading time from the United States (what Googlebot measures by default)
- Create explicit exceptions for Googlebot in geo-restriction rules
- Validate that no automatic redirection creates loops or inconsistencies for the bot
- Monitor server logs to identify any crawl blocks or slowdowns
❓ Frequently Asked Questions
Googlebot utilise-t-il toujours des IP américaines pour crawler mon site français ?
Mon CDN sert du contenu différent selon la géolocalisation. Est-ce un problème pour le SEO ?
Puis-je bloquer les IP non-européennes tout en restant crawlable par Google ?
Les temps de chargement mesurés depuis les États-Unis affectent-ils mon classement en Europe ?
Comment vérifier qu'une IP est bien celle de Googlebot et pas un faux bot ?
🎥 From the same video 11
Other SEO insights extracted from this same Google Search Central video · published on 12/03/2026
🎥 Watch the full video on YouTube →
💬 Comments (0)
Be the first to comment.