Official statement
Other statements from this video 11 ▾
- □ Le crawl intensif garantit-il vraiment un site de qualité ?
- □ Faut-il forcer Google à crawler davantage pour améliorer son classement ?
- □ Peut-on vraiment augmenter le crawl budget de son site en contactant Google ?
- □ Pourquoi Google crawle-t-il certains sites plus souvent que d'autres ?
- □ Pourquoi Google insiste-t-il sur l'implémentation du header If-Modified-Since ?
- □ Les paramètres d'URL créent-ils vraiment un espace de crawl infini pour Google ?
- □ Pourquoi les hashtags et ancres d'URL compliquent-ils le crawl de Google ?
- □ Pourquoi Google insiste-t-il autant sur les statistiques d'exploration dans Search Console ?
- □ Pourquoi un temps de réponse serveur lent tue-t-il votre crawl budget ?
- □ Faut-il vraiment optimiser le crawl budget si Google a des ressources illimitées ?
- □ Les sitemaps sont-ils vraiment indispensables pour optimiser le crawl de votre site ?
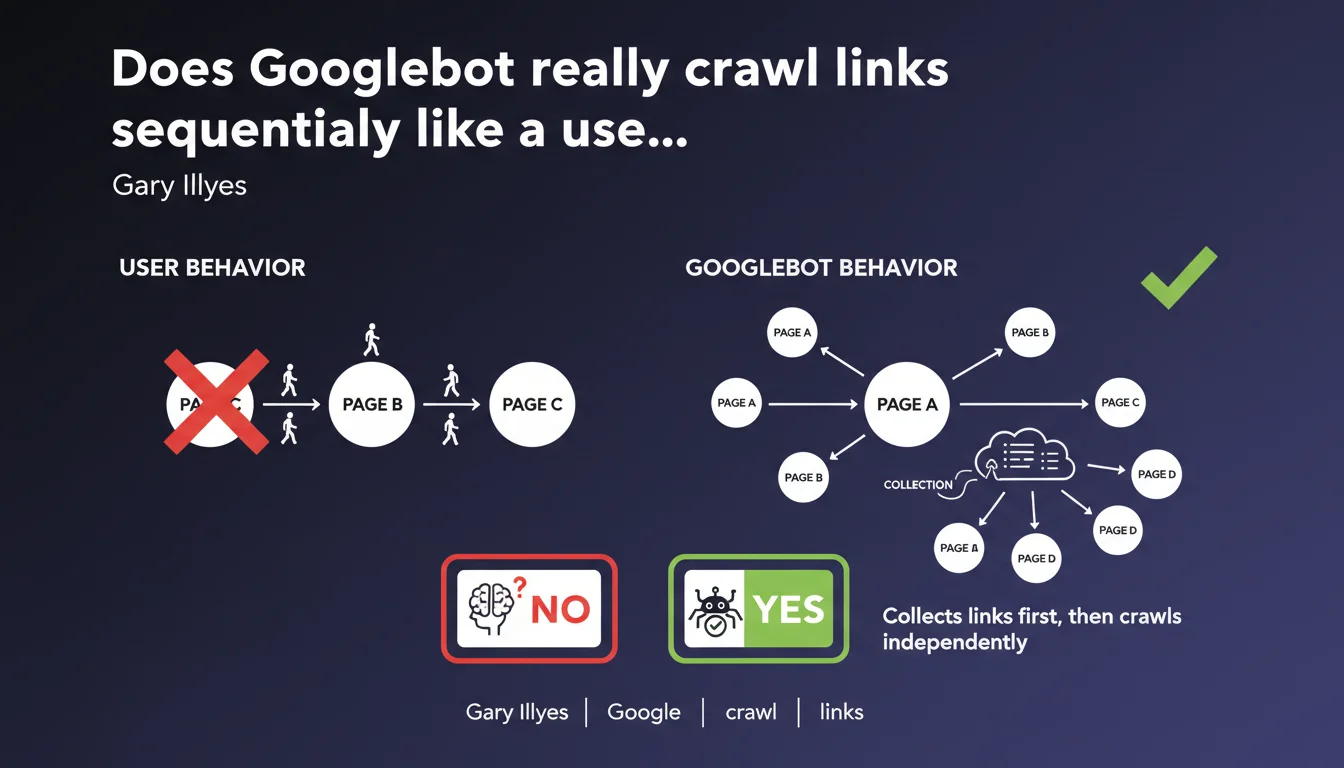
Googlebot does not follow links sequentially like a regular internet user would. It first collects all discovered links, then accesses them independently and non-linearly. This technical distinction changes how we should think about crawling and internal linking strategy.
What you need to understand
What is the difference between sequential crawling and collection-based crawling?
The popular misconception is straightforward: Googlebot lands on a page, reads the content, clicks a link, arrives on the next page, and repeats the process. Like a user navigating from link to link. Except that's not what happens.
In reality, the process is decoupled. The bot first analyzes the page and extracts all links present, then stores them in a queue. These URLs are subsequently crawled independently, without necessarily respecting the order of discovery or the hierarchical structure of the website. The behavior is asynchronous and parallelized.
Why does Google use this method instead of linear crawling?
Because it's infinitely more efficient at scale. Crawling the web sequentially would be catastrophically slow. Google has to manage billions of pages — it needs to distribute the work, prioritize certain URLs, and optimize bandwidth usage.
This architecture also allows revisiting certain pages more frequently than others, without being constrained by a linear path. A page can be crawled multiple times before the bot moves on to another discovery during the same session.
What are the direct implications for SEO?
- Click depth doesn't have the same impact as one might think — a page 5 clicks away from the homepage can be crawled before a page 2 clicks away if it's deemed higher priority.
- Internal linking doesn't work like a "single path" — each link is an independent discovery opportunity, not a step in a journey.
- Crawl patterns don't necessarily reflect the logical structure of the site — Googlebot can jump from one section to another without following your information architecture.
- The crawl frequency of a URL depends on its individual priority, not its position in a global path.
SEO Expert opinion
Is this statement consistent with what we observe in the field?
Yes, and it's even a point that many experienced SEO professionals already know — but few articulate clearly. Server logs show erratic crawl patterns, with non-linear jumps between sections, backtracking, orphaned pages discovered via external links before even being crawled through internal linking.
What's interesting is that Google confirms this explicitly. Too many beginners still think that positioning a link "higher" on the page or "earlier" in the user journey guarantees priority crawling. It doesn't. Priority is determined elsewhere: URL popularity, perceived freshness, overall crawl budget for the domain.
What nuances should we add to this statement?
Caution: saying that Googlebot doesn't follow links sequentially doesn't mean that the order of links or their position in the DOM has no importance. Google has confirmed multiple times that the first links in the HTML code carry more weight. [To verify] whether this impacts crawl prioritization or only internal PageRank — both hypotheses coexist.
Furthermore, this statement says nothing about the frequency of link collection. If Googlebot only recrawls page A every 30 days, a link added on that page to page B won't be discovered until the next visit. The non-linearity of crawling doesn't compensate for a deficit in crawl frequency.
In what cases does this technical distinction really make a difference?
Especially on large sites with limited crawl budget. If you have a site with 100,000 pages and Googlebot only crawls 5,000 URLs per day, understanding that crawling isn't sequential helps you optimize discoverability without focusing solely on hierarchical structure.
Concretely? Multiply entry points to your strategic pages — not just from the homepage, but from several hubs that are crawled frequently. Use internal linking as a decentralized distribution network, not as a single tree with a single root.
Practical impact and recommendations
What should you do concretely to leverage this technical reality?
Rethink your internal linking strategy in terms of networks, not linear hierarchy. Identify pages that are crawled frequently (check your server logs) and use them as discovery relays for strategic pages that are less frequently crawled.
Next, don't settle for creating a single link to an important page. Multiply internal link occurrences from different sections of your site, ensuring they remain contextually relevant. The more often a URL appears in the crawl queue, the more likely it will be visited quickly.
Finally, monitor the crawl frequency of your content hubs (blog, main categories, listing pages). If a section is crawled daily, it's an ideal entry point for discovering new pages — even if they're distant in the logical information architecture.
What errors should you avoid with this non-sequential crawl logic?
Don't fall into the trap of chaotic over-linking. Adding links everywhere without thematic logic degrades user experience quality and dilutes internal PageRank. Google increasingly understands contextual relevance — a forced link is worthless.
Another common mistake: neglecting the crawl velocity of your relay pages. If you're counting on a page to help discover other URLs, but it's only crawled once a month, you're wasting time. Check your logs before building your strategy.
How can you verify that your site is optimized for this crawl reality?
- Analyze your server logs to identify the most frequently crawled pages and Googlebot's visit patterns.
- Map your internal linking with a tool like Screaming Frog or Oncrawl to identify isolated or poorly distributed pages.
- Verify that your strategic pages receive links from multiple hubs that are crawled regularly, not just from the homepage.
- Test the discovery speed of new URLs by publishing a test page and observing how long Google takes to crawl it (via Search Console).
- Check that your XML sitemap is up to date and submitted — it's a complementary discovery channel that bypasses link-based crawling.
❓ Frequently Asked Questions
Est-ce que la profondeur de clic n'a donc plus aucune importance pour le crawl ?
Si Googlebot ne suit pas les liens de manière séquentielle, comment priorise-t-il les URLs à crawler ?
Faut-il abandonner l'idée d'une structure en silo thématique avec cette logique de crawl ?
Le sitemap XML devient-il plus important dans cette logique de crawl asynchrone ?
🎥 From the same video 11
Other SEO insights extracted from this same Google Search Central video · published on 08/08/2024
🎥 Watch the full video on YouTube →
💬 Comments (0)
Be the first to comment.