Official statement
Other statements from this video 11 ▾
- □ Le crawl intensif garantit-il vraiment un site de qualité ?
- □ Peut-on vraiment augmenter le crawl budget de son site en contactant Google ?
- □ Pourquoi Google crawle-t-il certains sites plus souvent que d'autres ?
- □ Pourquoi Google insiste-t-il sur l'implémentation du header If-Modified-Since ?
- □ Les paramètres d'URL créent-ils vraiment un espace de crawl infini pour Google ?
- □ Pourquoi les hashtags et ancres d'URL compliquent-ils le crawl de Google ?
- □ Pourquoi Google insiste-t-il autant sur les statistiques d'exploration dans Search Console ?
- □ Pourquoi un temps de réponse serveur lent tue-t-il votre crawl budget ?
- □ Googlebot suit-il vraiment les liens comme un utilisateur navigue de page en page ?
- □ Faut-il vraiment optimiser le crawl budget si Google a des ressources illimitées ?
- □ Les sitemaps sont-ils vraiment indispensables pour optimiser le crawl de votre site ?
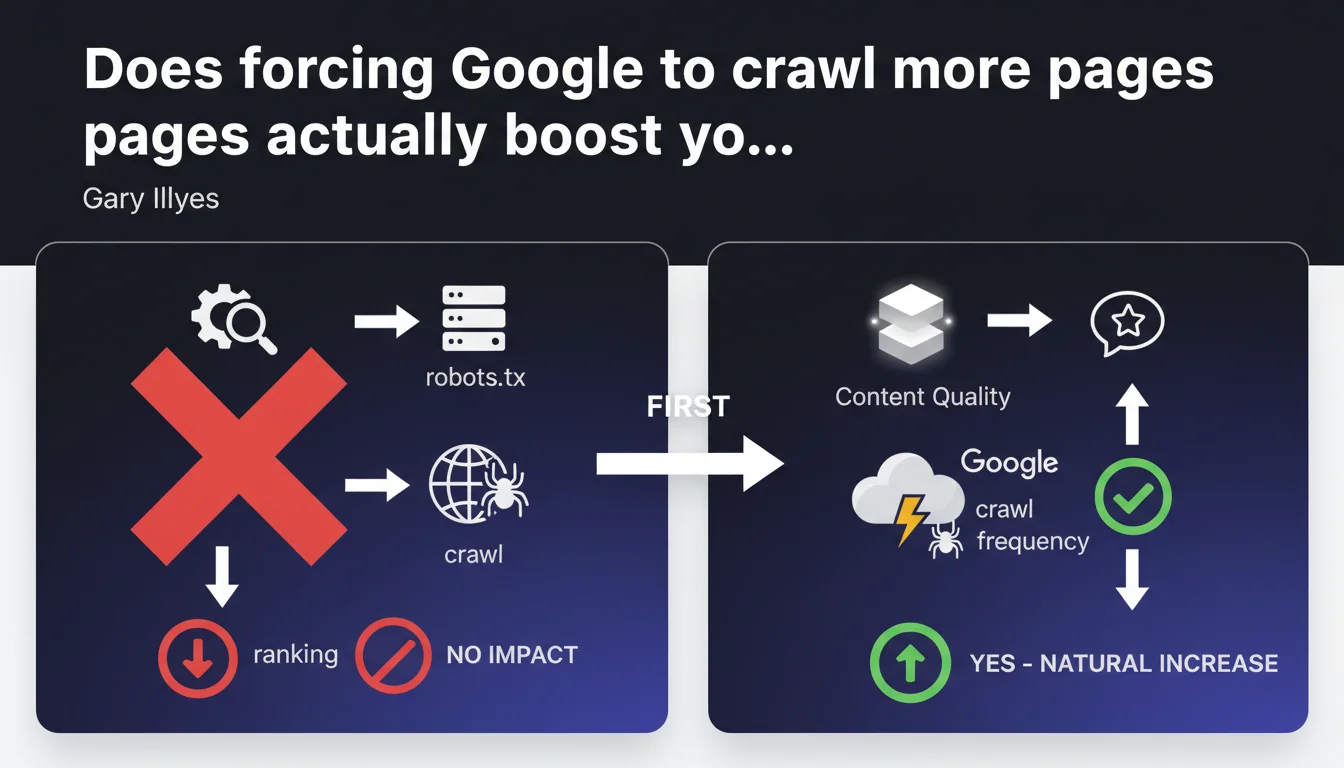
Artificially increasing a website's crawl through technical manipulation serves no purpose for SEO. Google automatically adjusts crawl frequency based on content quality and site popularity — it's a consequence, not a lever you can control.
What you need to understand
What exactly is crawl budget?
The crawl budget refers to the number of pages Googlebot explores on a site during a given period. This volume is not fixed — it varies based on server health, content freshness, and especially the perceived popularity of the site.
Google allocates its crawl resources where it matters most — high-value sites naturally receive more attention. Trying to manipulate this system with technical tricks (forcing recrawls via robots.txt, excessively pinging the Indexing API, etc.) is essentially confusing cause and effect.
Why does increasing crawl frequency make no difference to rankings?
Because crawling is just a logistical step. Crawling more often doesn't make your content better. If your pages offer nothing new or valuable, Google can visit them 10 times a day — they still won't rank higher as a result.
The real mechanism is that Google intensifies crawl when it detects positive signals: new relevant content, increased referral traffic, quality inbound links. Crawl follows performance; it doesn't create it.
Concretely, what naturally increases crawl frequency?
Several factors encourage Google to return more often: publishing original, search-demand-driven content on a regular basis, acquiring backlinks from authority sites, improving server response speed, and eliminating technical errors that waste crawl budget.
In short, it's the overall quality of your ecosystem that triggers a virtuous cycle — not manipulation in a text file.
- Crawl budget is a consequence, not a direct ranking lever
- Forcing crawl without improving content serves absolutely no purpose
- Google allocates resources to sites that prove their value through external and internal signals
- Optimizing crawl mainly means removing obstacles (404 errors, unnecessary redirects, duplicate content) so Google can efficiently explore your best pages
SEO Expert opinion
Is this statement consistent with what we observe in real-world practice?
Yes, and it's actually one of the few Google claims you can easily validate by checking server logs. Sites that attempt to artificially inflate their crawl through repeated pings or unnecessary robots.txt modifications see zero improvement in rankings.
Conversely, sites that publish high-demand content and earn natural links see their crawl explode — without asking for it. It's a lagging indicator, not a trigger.
What nuances should we apply to this rule?
There are cases where optimizing crawl has a real, albeit indirect impact. On very large sites (massive e-commerce, media outlets with thousands of pages), poorly distributed crawl can prevent indexation of strategic pages in favor of zombie pages.
In that context, reducing crawl waste (blocking useless facets, prioritizing internal linking to high-value pages) frees up budget for the right pages. But again, this isn't « increasing crawl » — it's making crawl smarter.
Where does Google remain vague?
Gary Illyes talks about « content quality » without ever precisely defining what triggers a crawl increase. [To verify]: what are the exact thresholds for user engagement, click-through rates, or freshness that push a site into « priority » status for Googlebot?
We know it exists (news sites are crawled in near-real-time), but the criteria remain opaque. This vagueness allows Google to say « create good content » without ever providing actionable metrics.
Practical impact and recommendations
What should you concretely do to optimize crawl?
First, stop trying to force the machine. Focus on removing obstacles: error pages, redirect chains, massive duplicate content, crawlable filter facets that multiply infinitely.
Next, direct crawl toward your strategic pages through coherent internal linking. The more internal links a page receives that are contextually relevant, the better chance it has of being crawled frequently.
- Audit your server logs to identify over-crawled pages with no SEO value
- Block via robots.txt or noindex any non-essential sections (internal search pages, filters without traffic, outdated archives)
- Prioritize internal linking toward high-potential commercial or informational pages
- Regularly publish original content that addresses actual search demand
- Improve server response time — slow sites get crawled less
- Earn quality backlinks that signal to Google your site deserves attention
What mistakes should you absolutely avoid?
Don't ping Google's Indexing API for standard pages — it's reserved for structured video content or job postings. Using this API on standard content can be perceived as spam and harm your crawl.
Also avoid constantly modifying your robots.txt or sitemap.xml thinking it will speed anything up. Google detects these manipulations and doesn't respond the way you'd hope.
How do you verify that your strategy is working?
Analyze your server logs over several weeks. Check whether Googlebot explores your new strategic pages within a reasonable timeframe (48-72 hours for an average site, near-instant for a media outlet). If that's not happening, it's a signal that your internal linking or overall perceived relevance is problematic.
Also monitor the evolution of indexed pages through Google Search Console. Stagnation while you're publishing content suggests either a technical issue or a perceived quality deficit.
❓ Frequently Asked Questions
Modifier mon sitemap.xml plus souvent va-t-il accélérer l'indexation ?
L'API Indexing peut-elle forcer Google à indexer n'importe quel contenu ?
Pourquoi Google crawle-t-il des pages inutiles au lieu de mes nouvelles pages ?
Un site lent est-il moins crawlé ?
Le crawl budget est-il réellement un problème pour les petits sites ?
🎥 From the same video 11
Other SEO insights extracted from this same Google Search Central video · published on 08/08/2024
🎥 Watch the full video on YouTube →
💬 Comments (0)
Be the first to comment.