Official statement
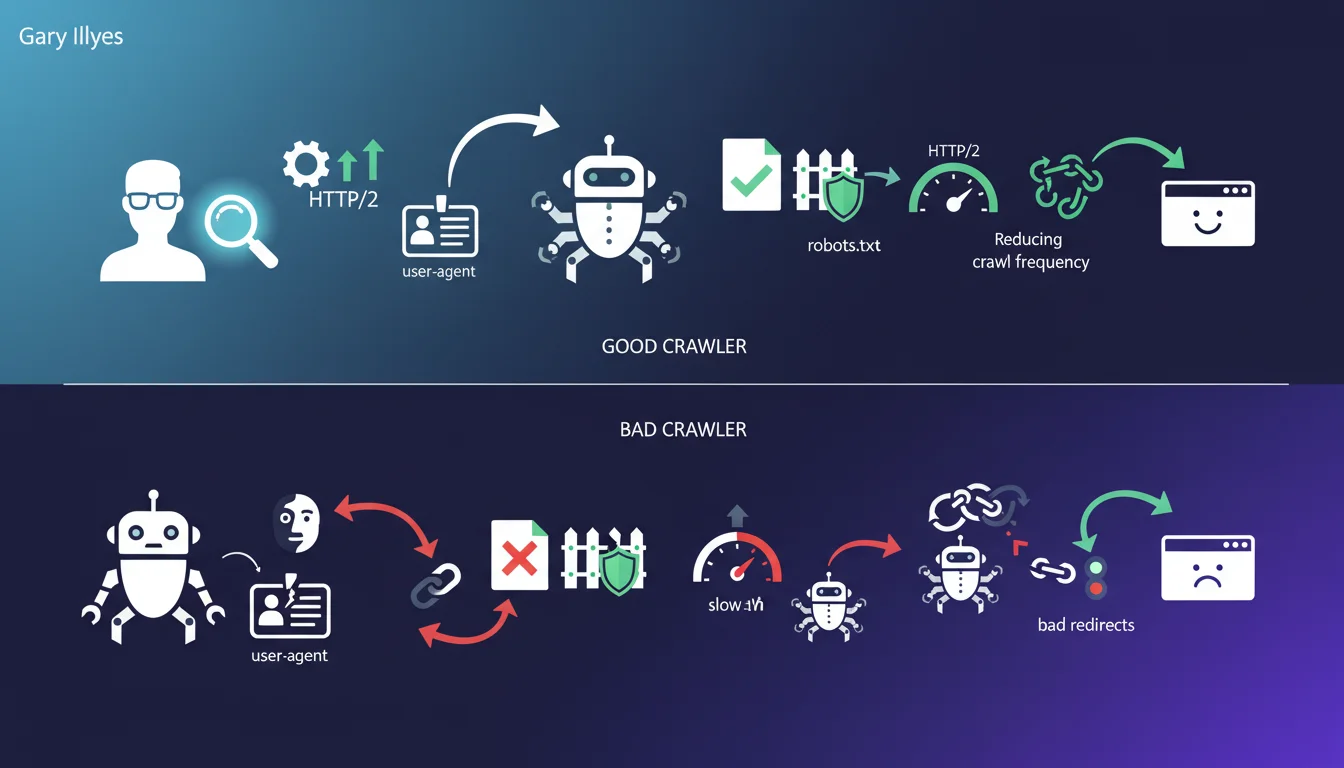
Attributes of a good crawler according to Martin Splitt Support HTTP/2 for better performance and efficiency.
Clearly declare its identity via the user-agent.
Respect robots.txt to avoid crawling forbidden areas.
Reduce crawling frequency if the server slows down.
Take cache directives into account.
Have reasonable retry mechanisms if a request fails.
Follow redirects correctly.
Handle errors gracefully. Best practices from the IETF document (shared by Gary Illyes) Crawlers must absolutely support and respect the Robots Exclusion Protocol (robots.txt).
They must be easily identifiable through the user-agent string.
Their activity must not disrupt the normal functioning of the site.
Respecting cache directives is mandatory.
Crawlers must expose their IP ranges in a standardized way.
A dedicated page must explain how collected data is used and how to block the crawler.
What you need to understand
Google has just clarified the technical criteria that distinguish a professional crawler from a poorly designed or malicious bot. This position is based on IETF standards and reveals what Google actually expects from crawlers visiting the web.
For SEO practitioners, this statement is crucial because it reveals the technical behaviors that Googlebot itself respects and considers as industry standards. Understanding these criteria allows you to identify problematic bots that can harm your server performance.
This communication comes at a time when crawl budget is becoming critical for many sites, particularly with the proliferation of AI crawlers and the general increase in bot traffic. Knowing how to distinguish good actors from bad ones is becoming a performance and server cost issue.
- HTTP/2 support mandatory for crawl efficiency
- Clearly identifiable user-agent without ambiguity
- Strict respect for robots.txt as a minimum standard
- Dynamic adaptation of frequency according to server load
- Intelligent cache management and error handling
- Complete transparency: documented IPs and data usage policy
SEO Expert opinion
This statement is perfectly consistent with what we observe in Googlebot's crawl logs over the past several years. Google does indeed apply these principles, particularly the automatic reduction of crawling when response times increase.
The important nuance concerns emerging AI crawlers (GPTBot, Claude-Web, etc.) that don't always respect these standards. Some ignore cache directives, others have overly aggressive retry mechanisms. This statement is probably an indirect message to these new players.
A particular point of attention: respecting robots.txt is not legally mandatory in all countries, it's a convention. Google insists on this point because it wants it to become a universal standard, but in practice, many commercial scrapers deliberately ignore it.
Practical impact and recommendations
This statement allows you to establish a clear policy for managing bot traffic on your site and optimizing your crawl budget by identifying legitimate actors.
- Audit your server logs to identify crawlers that don't meet these criteria (absence of clear user-agent, non-respect of robots.txt, no HTTP/2 support)
- Document legitimate user-agents that you accept by creating a whitelist based on these quality criteria
- Block or limit crawlers that don't clearly identify themselves or don't respect robots.txt through specific server rules
- Verify that your robots.txt is properly configured and tested with official tools (Google Search Console, Bing Webmaster Tools)
- Implement a monitoring system that detects abnormal crawl spikes and suspicious behaviors (excessive retries, cache non-respect)
- Demand transparency from AI crawlers: verify that they document their IPs and data usage policy before authorizing them
- Optimize your infrastructure for HTTP/2 if not already done, as good crawlers use it extensively
- Configure appropriate cache directives to reduce unnecessary load even from good crawlers
- Create a dedicated page explaining your policy regarding crawlers, with contact instructions if a bot causes problems
These technical optimizations span multiple levels: server configuration, log analysis, firewall rules, and continuous monitoring. Implementing a comprehensive crawler management strategy requires cross-functional expertise combining technical SEO, system administration, and data analysis.
For high-traffic sites or complex architectures, guidance from a specialized SEO agency can prove valuable for establishing a tailored crawl budget strategy, identifying real threats in your logs, and implementing the right configurations without risking accidentally blocking legitimate crawlers essential to your visibility.
💬 Comments (0)
Be the first to comment.