Official statement
Other statements from this video 12 ▾
- □ Google suit-il vraiment tous les codes HTTP ou s'arrête-t-il au premier rencontré ?
- □ Un CDN améliore-t-il vraiment votre classement Google ?
- □ Faut-il bloquer le crawl des endpoints API pour optimiser son budget de crawl ?
- □ Faut-il vraiment bannir le nofollow des liens internes ?
- □ Faut-il arrêter de se fier à la commande site: pour mesurer l'indexation ?
- □ Pourquoi Google préfère-t-il les redirections serveur aux redirections JavaScript ?
- □ Faut-il vraiment différencier les redirections 301 et 302 pour le SEO ?
- □ Faut-il vraiment isoler vos contenus archivés pour améliorer votre SEO ?
- □ Peut-on vraiment forcer l'affichage des sitelinks dans Google ?
- □ Faut-il vraiment abandonner les iframes et les PDF pour indexer du contenu textuel ?
- □ Faut-il vraiment bloquer ou masquer les liens externes pour protéger son PageRank ?
- □ Google favorise-t-il vraiment certaines plateformes CMS pour le référencement ?
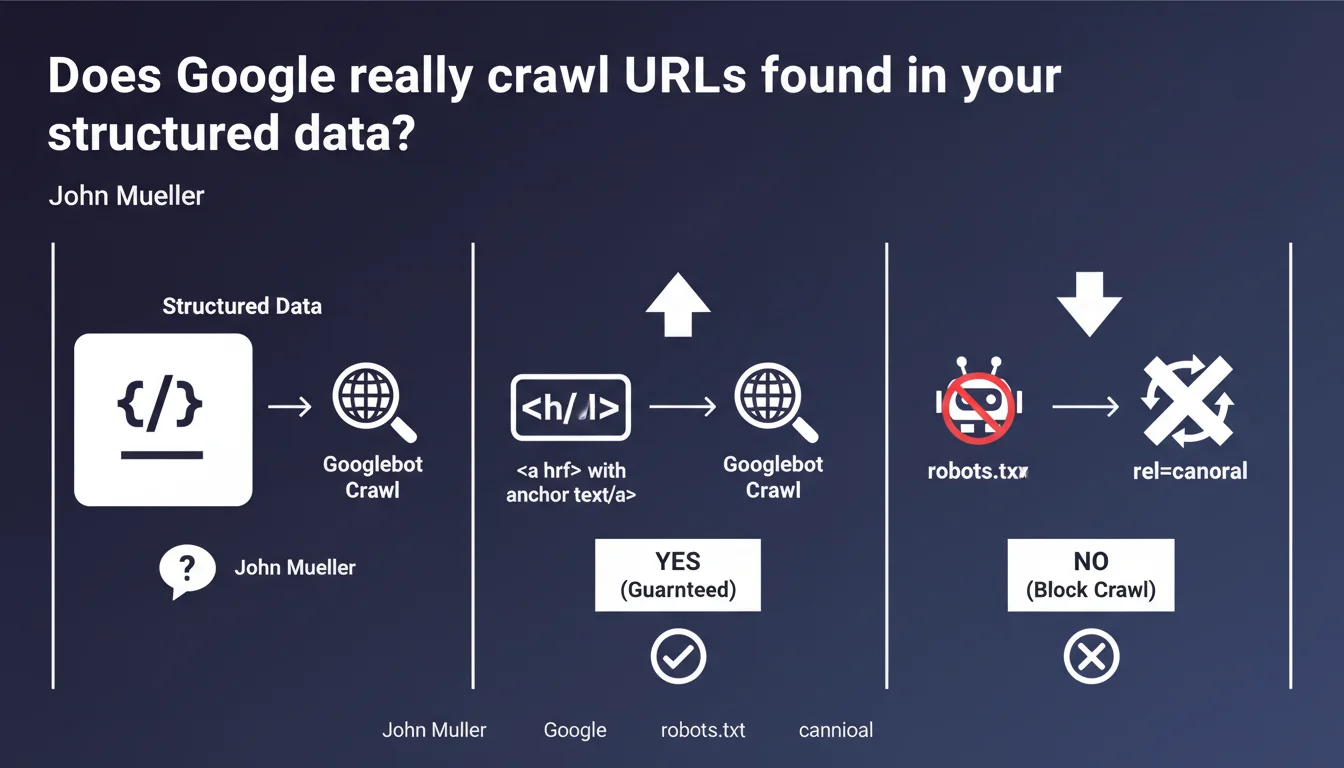
Google can discover and crawl URLs present in your structured data, but nothing guarantees it will. To ensure a page gets crawled, use a real HTML link with anchor text. If you want to block crawling, use robots.txt or rel=canonical.
What you need to understand
Does Google really crawl URLs found in your structured data?
The short answer: sometimes. Google can technically extract and follow URLs referenced in your Schema.org tags, but this capability is not a guarantee. The engine prioritizes classic HTML signals to determine which pages deserve to be crawled.
In practice, a URL mentioned only in JSON-LD or microformats has no guarantee of being discovered. The bot relies on priority criteria — and structured data doesn't rank at the top of that list.
Why doesn't Google commit more strongly to this?
Because the primary role of structured data is not crawling, but enriching search results. Schema.org serves to qualify the content of a page already discovered, not to point out new URLs to explore.
If Google sometimes follows these URLs, it's a side effect, not an official feature you can build a strategy around. The engine reserves the right to change this behavior at any time.
What happens if I want to block a URL mentioned in my structured data?
Two solutions: robots.txt to prohibit crawling upfront, or rel=canonical to indicate that another version has authority. Mueller is clear on this — structured data is not a crawl control mechanism.
If you don't want a page to be indexed, don't count on the absence of an HTML link to protect it. Block it explicitly.
- Structured data can contain URLs, but crawling is not guaranteed
- To ensure discovery, use HTML links with anchor text
- To block, use robots.txt or rel=canonical, not the absence of a link
- The role of structured data remains semantic enrichment, not navigation
SEO Expert opinion
Is this statement consistent with observed practices in the field?
Yes, but with troubling exceptions. We regularly observe that Google discovers pages mentioned only in structured data like BreadcrumbList or ItemList. These URLs then appear in Search Console without any internal HTML link referencing them.
The problem: this behavior is neither consistent nor documented. Some sites experience systematic crawling, others never do. It's impossible to predict when Google will activate this mechanism. [To verify] depending on Schema types and the site's crawl frequency.
What nuances should be added to this rule?
Mueller speaks of discovery and crawling, but doesn't mention indexing. Even if Google crawls a URL found in your structured data, nothing guarantees it will be indexed — especially without backlinks or internal linking to support it.
Furthermore, certain Schema types include URLs that are not meant to be crawled — think of the url property of Organization pointing to social networks or third-party platforms. Google must distinguish these cases, but the exact logic remains unclear.
In which cases does this rule not fully apply?
AMP pages and content structured for Google News or Google Shopping seem to receive different treatment. URLs referenced in XML feeds or specific tags (like amphtml) are systematically followed.
Similarly, certain crawls triggered by special events — product update, new content signaled via IndexNow or Search Console — can trigger the following of URLs found in structured data. But again, no contractual guarantee.
Practical impact and recommendations
What should you concretely do to guarantee your pages get crawled?
The answer is simple: create classic HTML links with anchor text. This is the most reliable signal to indicate to Google that a page deserves to be crawled and indexed.
Integrate these links into your internal linking structure — main navigation, menu, editorial content, footer if relevant. The more quality internal links a page receives, the faster and more regularly it will be crawled.
What mistakes should you avoid with URLs in structured data?
First mistake: believing that mentioning a URL in your structured data is enough to get it indexed. If Google doesn't crawl it, you're wasting time.
Second mistake: using structured data as a crawl control mechanism. If you don't want a page to be explored, block it explicitly — don't just remove HTML links hoping structured data won't reveal it.
Third mistake: neglecting consistency between your HTML links and structured data. If a BreadcrumbList references a URL absent from the DOM, this creates confusion — and potentially contradictory signals for the engine.
How can you verify that your site complies with Google's recommendations?
- Audit your strategic pages: each important URL must have at least one internal HTML link
- Check that your structured data doesn't contain orphaned URLs (without corresponding HTML link)
- Control your robots.txt file: any page you don't want crawled should be listed there
- Use rel=canonical to signal priority versions and avoid crawling variants
- Test your structured data with the Rich Results Test to detect errors
- Monitor Search Console: identify pages discovered without apparent HTML link — this reveals crawling via structured data
Structured data enriches your pages, but never replaces a solid internal linking structure. To master crawling, combine classic HTML links, robots.txt, and canonical — and consider URLs in your schemas as an uncertain bonus, never a guarantee.
These cross-optimization between technical structure, linking, and semantics requires pointed expertise and an overall vision. If you want to avoid pitfalls and maximize your chances of optimal crawling, support from a specialized SEO agency can prove valuable to lay the right foundations from the start.
❓ Frequently Asked Questions
Les URLs dans mes données structurées de type BreadcrumbList sont-elles toujours crawlées ?
Dois-je retirer les URLs de mes données structurées si je ne veux pas qu'elles soient crawlées ?
Est-ce que Google indexe toutes les URLs qu'il crawle via les données structurées ?
Les données structurées peuvent-elles remplacer le maillage interne pour la découverte de pages ?
Faut-il éviter de mentionner des URLs externes dans mes données structurées ?
🎥 From the same video 12
Other SEO insights extracted from this same Google Search Central video · published on 08/06/2022
🎥 Watch the full video on YouTube →
💬 Comments (0)
Be the first to comment.