Official statement
Other statements from this video 12 ▾
- □ Un CDN améliore-t-il vraiment votre classement Google ?
- □ Faut-il bloquer le crawl des endpoints API pour optimiser son budget de crawl ?
- □ Faut-il vraiment bannir le nofollow des liens internes ?
- □ Faut-il arrêter de se fier à la commande site: pour mesurer l'indexation ?
- □ Pourquoi Google préfère-t-il les redirections serveur aux redirections JavaScript ?
- □ Faut-il vraiment différencier les redirections 301 et 302 pour le SEO ?
- □ Faut-il vraiment isoler vos contenus archivés pour améliorer votre SEO ?
- □ Peut-on vraiment forcer l'affichage des sitelinks dans Google ?
- □ Faut-il vraiment abandonner les iframes et les PDF pour indexer du contenu textuel ?
- □ Faut-il vraiment bloquer ou masquer les liens externes pour protéger son PageRank ?
- □ Google favorise-t-il vraiment certaines plateformes CMS pour le référencement ?
- □ Les URLs dans les données structurées sont-elles crawlées par Google ?
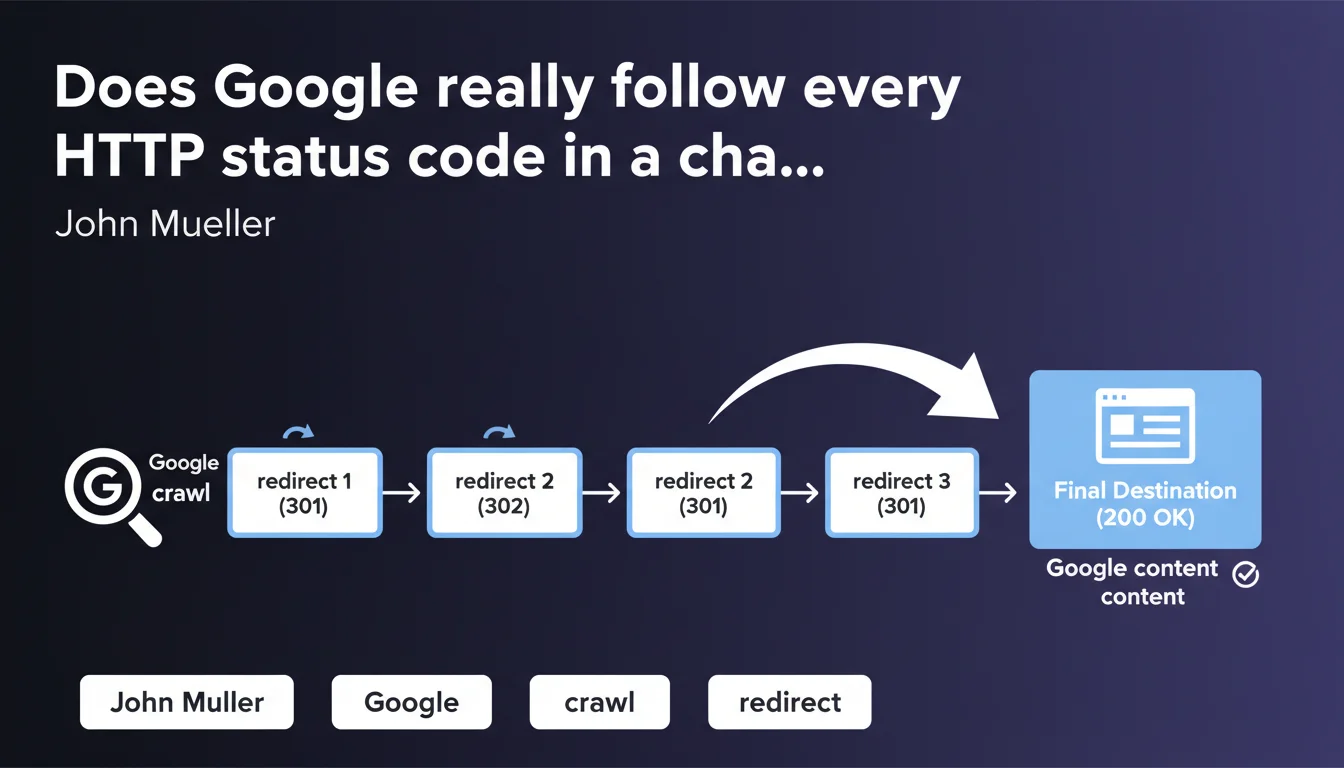
Google processes only the final HTTP status code it encounters after following a complete redirect chain. When crawling a series of redirects, the search engine follows the entire chain to the final destination page and focuses on the end result — whether it's a page with content or an error. This distinction is crucial for correctly diagnosing indexation issues.
What you need to understand
What does "first HTTP status code" really mean in this context?
When Google crawls a URL, it first encounters an HTTP status code — 200, 301, 404, etc. This initial code determines the bot's first response. If this code indicates a redirect (301, 302, 307, 308), Googlebot automatically follows the redirect chain.
The "first code" doesn't mean Google ignores the rest. It means that the server's initial response triggers the crawl behavior. The final result of the chain — the destination page or an error — is what Google retains for indexing.
Why is this distinction critical for SEO?
Because it explains how Google handles multiple redirect chains. If you have A → B → C → D, Google will follow the entire chain and index (or not) page D based on its final status code. However, each hop consumes crawl budget and dilutes link equity passed along.
This clarification also confirms that Google doesn't "blend" signals from multiple successive HTTP codes. It's binary: either the final page is accessible (200), or it isn't (404, 410, etc.).
How does Google handle error pages at the end of a chain?
If a redirect chain ends with an error page (404, 500), Google considers the resource inaccessible — regardless of intermediate codes. The original URL won't be indexed, even if the initial hops were clean 301s.
This is a classic scenario when migrating a site and a redirect rule points to a URL that's itself redirected or broken. The first code might be a "correct" 301, but if the final destination returns an error, all effort is wasted.
- Google follows complete redirect chains, not just the first hop
- The final status code (200, 404, etc.) determines whether the resource gets indexed
- Each intermediate hop consumes crawl budget and weakens link equity transmission
- A chain ending in an error negates any SEO benefit from intermediate redirects
- Multiple HTTP status codes don't "offset" or "compensate" for each other
SEO Expert opinion
Does this statement resolve the ambiguity around redirect chains?
Partially. John Mueller clarifies that Google doesn't blindly stop at the first HTTP code — it follows the logic through to completion. However, this phrasing remains slightly ambiguous on one critical point: what happens when a chain mixes 301s and 302s?
The official answer is that the final code takes precedence. But in practice, we observe that Google can retain the intermediate URL in its index if it's received strong signals (backlinks, age) — especially with temporary 302 redirects. [To be verified]: this statement doesn't specify exact behavior with mixed redirects or partial loops.
What real-world observations contradict or nuance this point?
In complex migrations, we regularly see Google indexing intermediate URLs within a chain A → B → C, especially if B has historically received traffic or links. This contradicts the idea of purely binary processing: "first code → final result".
Another concrete case: chains with JavaScript or meta refresh redirects. Google follows them, yes, but with lower reliability and delays. Mueller's statement covers only "classic" HTTP codes — it says nothing about client-side redirects.
In which cases does this rule not fully apply?
Soft 404s are a blind spot. A page can return a 200 (technically "successful") but be detected as an error by Google if content is empty or resembles a 404. The "first code" is correct, the "final result" too — but Google deindexes it anyway.
Another limitation: timeouts and network errors. If Google abandons crawling mid-chain (after 5 hops, for example), it never sees the "final result". The statement implicitly assumes the chain is technically crawlable from end to end.
Practical impact and recommendations
What concrete action should you take to optimize redirect chains?
Eliminating any redirect chain altogether is the absolute priority. Every intermediate hop dilutes link equity and wastes crawl budget unnecessarily. Aim for direct redirects: A → C, never A → B → C.
Use tools like Screaming Frog, OnCrawl, or Botify to detect chains. Configure a crawl with redirect following enabled and export all URLs with more than one hop. Fix by updating your redirect rules server-side.
How can you verify that your redirects end with a valid 200 code?
Test critical URLs manually with tools like httpstatus.io or browser DevTools (Network tab). Confirm the entire chain is visible and the final code is 200.
For large-scale audits, export your redirects from your .htaccess, nginx.conf, or CDN. Cross-reference with Search Console data: if redirected URLs still appear with 404 errors, a chain is broken.
What mistakes must you absolutely avoid during migration or redesign?
Never mass-redirect to your homepage or a generic category. Each old URL should point to its thematic equivalent — even if it's not a perfect 1:1 match.
Avoid temporary redirects (302) during permanent migrations. Google may interpret them as provisional and keep the old URL indexed, diluting your signals. Use exclusively permanent 301 redirects.
- Audit all existing redirect chains and reduce them to a single hop
- Manually test strategic URLs to confirm a final 200 status code
- Check Search Console to ensure redirected URLs don't generate 404 errors
- Prioritize permanent 301 redirects during permanent migrations
- Avoid "catch-all" redirects to homepage or generic landing pages
- Document all redirect rules in a centralized tracking spreadsheet
- Monitor crawl budget post-migration to detect any anomalies
❓ Frequently Asked Questions
Google suit-il les redirections 302 de la même manière que les 301 ?
Combien de redirections successives Google accepte-t-il de suivre ?
Une redirection vers une page en erreur 404 transmet-elle de l'équité de lien ?
Les redirections JavaScript ou meta refresh sont-elles traitées comme des codes HTTP ?
Comment détecter rapidement les chaînes de redirections sur un gros site ?
🎥 From the same video 12
Other SEO insights extracted from this same Google Search Central video · published on 08/06/2022
🎥 Watch the full video on YouTube →
💬 Comments (0)
Be the first to comment.