Official statement
Other statements from this video 12 ▾
- □ Google suit-il vraiment tous les codes HTTP ou s'arrête-t-il au premier rencontré ?
- □ Un CDN améliore-t-il vraiment votre classement Google ?
- □ Faut-il bloquer le crawl des endpoints API pour optimiser son budget de crawl ?
- □ Faut-il arrêter de se fier à la commande site: pour mesurer l'indexation ?
- □ Pourquoi Google préfère-t-il les redirections serveur aux redirections JavaScript ?
- □ Faut-il vraiment différencier les redirections 301 et 302 pour le SEO ?
- □ Faut-il vraiment isoler vos contenus archivés pour améliorer votre SEO ?
- □ Peut-on vraiment forcer l'affichage des sitelinks dans Google ?
- □ Faut-il vraiment abandonner les iframes et les PDF pour indexer du contenu textuel ?
- □ Faut-il vraiment bloquer ou masquer les liens externes pour protéger son PageRank ?
- □ Google favorise-t-il vraiment certaines plateformes CMS pour le référencement ?
- □ Les URLs dans les données structurées sont-elles crawlées par Google ?
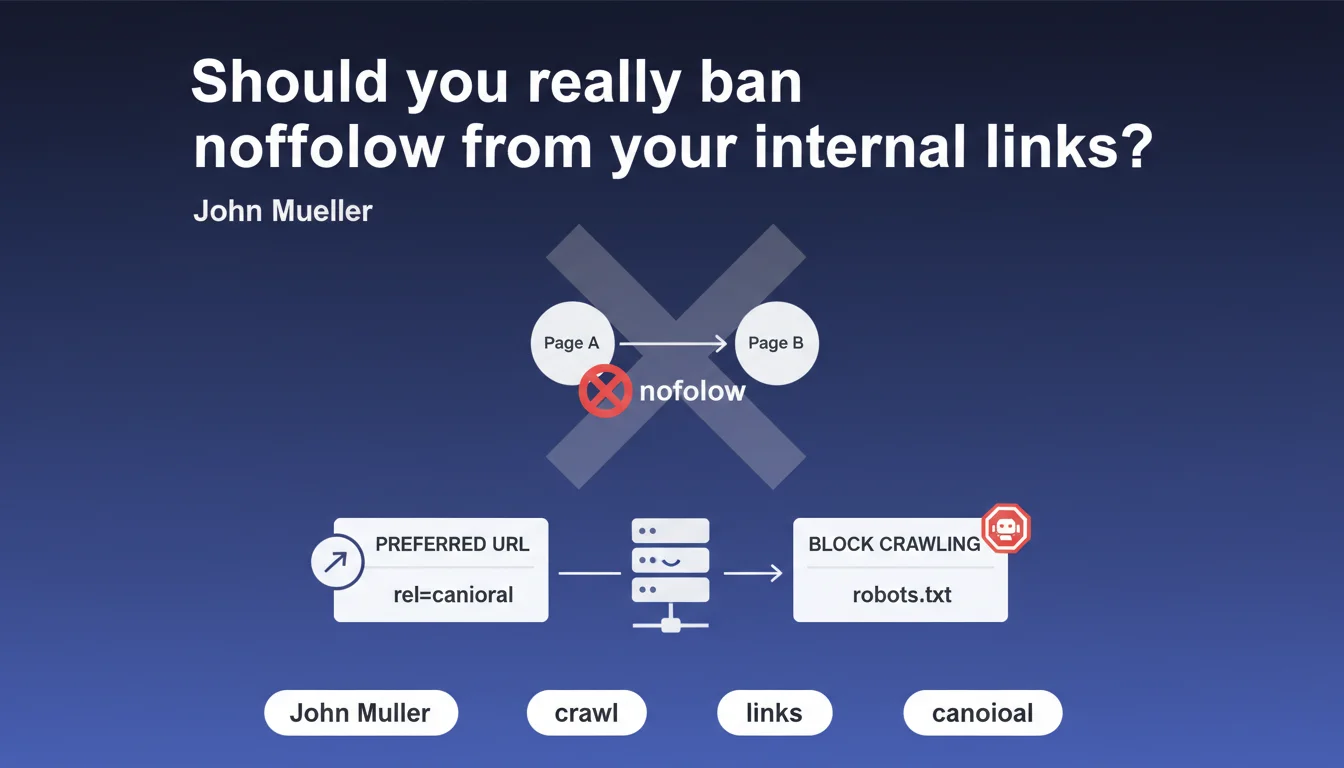
Google advises against using nofollow on internal links. The official position: use rel=canonical instead to manage preferred URLs or robots.txt to block problematic URLs. Internal nofollow is presented as an obsolete practice with no strategic value.
What you need to understand
Why does Google discourage nofollow on internal links?
Mueller's statement contradicts a still-common practice among some SEOs who use internal nofollow to control PageRank distribution. Google believes this approach has "generally no sense" — a formulation that leaves little room for ambiguity.
The underlying reasoning: internal nofollow solves no problem that other tools don't solve better. If you want to avoid indexing a URL, rel=canonical points to the preferred version. If you're trying to reduce server load, robots.txt blocks crawling. Nofollow, meanwhile, does neither effectively.
What is the real role of nofollow since 2019?
Since March 2019, Google treats nofollow as a hint rather than a directive. Concretely? The search engine can choose to follow these links or not. On an external site, that makes sense — on your own site, it makes no sense to signal to Google: "This link is here, but maybe ignore it."
Internal nofollow was once used for PageRank sculpting — a technique officially ended in 2009. Continuing to apply it in 2020+ amounts to clinging to a disabled lever. You waste time and complicate your architecture for no gain whatsoever.
What concrete alternatives does Google propose?
Mueller lists two:
- rel=canonical: you indicate which URL should be indexed when multiple versions exist (filters, parameters, variants). It's clean, explicit, and understood by all search engines.
- robots.txt: you block crawling of problematic sections — infinite pagination, useless facets, sorting pages. This reduces server load and prevents crawl budget waste.
- Bonus not mentioned but obvious: noindex to prevent indexing without blocking crawling (useful if the page should pass juice but shouldn't appear in SERPs).
These tools target a specific need. Internal nofollow, meanwhile, remains vague in intent and ineffective in result.
SEO Expert opinion
Is this position consistent with real-world observations?
Yes, largely. Tests conducted since 2019 show that internal nofollow neither prevents crawling, nor indexation, nor even systematically blocks juice flow. Google's behavior has become unpredictable — exactly what you don't want when optimizing an architecture.
Where it gets sticky: some SEOs still observe crawl variations after massive addition of internal nofollow. Correlation is not causation — often, it's the structure change itself (link removal, mesh reorganization) that explains the effect, not the nofollow attribute.
Are there cases where this rule might admit exceptions?
Mueller says "generally" — that word matters. There are marginal situations where internal nofollow retains perceived utility:
- Unmoderated user links (comments, internal forums): nofollow limits internal spam risk, even if it's no longer an absolute guarantee.
- Conversion zones (CTA buttons, cart links): some prefer to isolate these flows from standard mesh, but honestly, a simple unoptimized anchor link does the job.
- AJAX/React interfaces where links aren't meant to be crawled: but in that case, proper server-side rendering solves the problem better.
In 95% of cases, internal nofollow is a historical relic. The remaining 5% often stem from a misunderstanding of the actual problem. [To verify]: Google has never published data showing a measurable negative impact of internal nofollow, just the absence of positive impact.
What if your site already uses internal nofollow extensively?
Let's be honest: if you have 10,000 pages with strategic internal nofollow, don't touch anything before auditing. Brutally removing all nofollow can disrupt crawling — not because the attribute has magic effect, but because you're modifying site topology all at once.
Recommended approach: test on an isolated section, measure crawl impact (Search Console, server logs), then deploy progressively. And in the meantime, ask yourself the real question: why were these links in nofollow to begin with? If it's to prevent indexing, switch to canonical or noindex. If it's to manage crawl budget, robots.txt is more reliable.
Practical impact and recommendations
What should you do concretely on your site?
First step: audit current internal nofollow usage. Crawl your site with Screaming Frog or Oncrawl, filter internal links bearing the nofollow attribute, and document the intent behind each usage.
Second step: for each group of nofollow links, ask yourself: what problem is this supposed to solve? If it's indexation, switch to rel=canonical or noindex. If it's crawl budget, add a robots.txt rule. If it's "just in case," remove it outright.
What mistakes should you avoid during transition?
Don't remove all nofollow at once on a large site — you risk an uncontrolled crawl spike that can overload your server or dilute crawl budget across valueless zones. Proceed in waves, monitoring logs.
Another trap: systematically replacing nofollow with noindex without thinking. Noindex blocks indexation but allows crawling and juice flow — that's not always what you want. Canonical is often better suited for URL variants (filters, sorts, paginations).
And above all: don't keep nofollow "as a precaution." This approach reflects a misunderstanding of how Google currently works. You waste time maintaining a useless configuration.
How do you verify your site complies with recommendations?
- Crawl your site and list all internal nofollow links
- Identify the intent behind each usage (indexation, crawling, PageRank sculpting)
- Replace with the appropriate tool: canonical for duplicates, robots.txt for crawling, noindex if needed
- Test on a limited section before global rollout
- Monitor server logs and Search Console for 2-4 weeks post-change
- Document rules to prevent internal nofollow from reappearing at next redesign
Abandoning internal nofollow isn't just a technical update — it's a paradigm shift. You move from artificial PageRank control logic (obsolete) to proper architecture management: canonical for variants, robots.txt for crawling, intelligent mesh for juice distribution.
These adjustments may seem straightforward in theory, but implementation on a medium or large site requires pointed expertise in SEO architecture. Between auditing current usage, prioritizing fixes, progressive rollout, and post-change monitoring, it's easy to create more problems than you solve. If your site has thousands of pages or your technical team lacks bandwidth, partnering with a specialized SEO agency can prevent costly mistakes and accelerate return on investment.
❓ Frequently Asked Questions
Le nofollow interne a-t-il encore un impact sur le crawl budget ?
Peut-on encore utiliser le nofollow pour le PageRank sculpting ?
Faut-il retirer immédiatement tous les nofollow internes existants ?
Le nofollow interne garde-t-il une utilité sur les liens utilisateurs (commentaires, forums) ?
Quelle est la différence entre nofollow et noindex pour gérer les URLs non prioritaires ?
🎥 From the same video 12
Other SEO insights extracted from this same Google Search Central video · published on 08/06/2022
🎥 Watch the full video on YouTube →
💬 Comments (0)
Be the first to comment.