Declaration officielle
Autres déclarations de cette vidéo 12 ▾
- □ Google suit-il vraiment tous les codes HTTP ou s'arrête-t-il au premier rencontré ?
- □ Un CDN améliore-t-il vraiment votre classement Google ?
- □ Faut-il bloquer le crawl des endpoints API pour optimiser son budget de crawl ?
- □ Faut-il vraiment bannir le nofollow des liens internes ?
- □ Faut-il arrêter de se fier à la commande site: pour mesurer l'indexation ?
- □ Pourquoi Google préfère-t-il les redirections serveur aux redirections JavaScript ?
- □ Faut-il vraiment différencier les redirections 301 et 302 pour le SEO ?
- □ Faut-il vraiment isoler vos contenus archivés pour améliorer votre SEO ?
- □ Peut-on vraiment forcer l'affichage des sitelinks dans Google ?
- □ Faut-il vraiment abandonner les iframes et les PDF pour indexer du contenu textuel ?
- □ Faut-il vraiment bloquer ou masquer les liens externes pour protéger son PageRank ?
- □ Google favorise-t-il vraiment certaines plateformes CMS pour le référencement ?
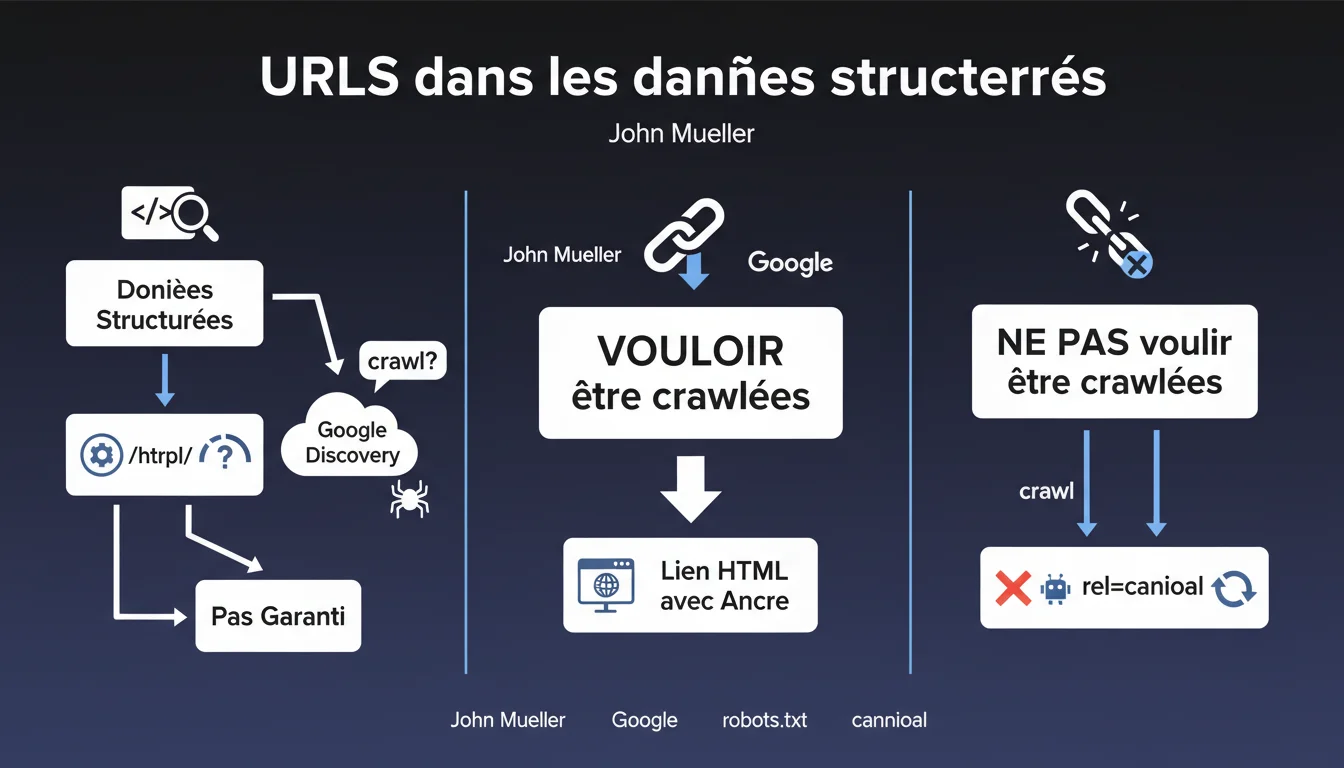
Google peut découvrir et crawler les URLs présentes dans vos données structurées, mais rien ne le garantit. Pour assurer le crawl d'une page, utilisez un vrai lien HTML avec ancre. Si vous voulez bloquer le crawl, passez par robots.txt ou rel=canonical.
Ce qu'il faut comprendre
Google crawle-t-il réellement les URLs trouvées dans les données structurées ?
La réponse courte : parfois. Google peut techniquement extraire et suivre les URLs référencées dans vos balises Schema.org, mais cette capacité ne constitue pas une promesse. Le moteur privilégie les signaux HTML classiques pour déterminer quelles pages méritent d'être crawlées.
Concrètement, une URL mentionnée uniquement dans du JSON-LD ou des microformats n'a aucune garantie d'être découverte. Le robot se base sur des critères de priorité — et les données structurées ne figurent pas en tête de liste.
Pourquoi Google ne s'engage-t-il pas davantage sur ce point ?
Parce que le rôle premier des données structurées n'est pas le crawl, mais l'enrichissement des résultats de recherche. Schema.org sert à qualifier le contenu d'une page déjà découverte, pas à indiquer de nouvelles URLs à explorer.
Si Google suit parfois ces URLs, c'est un effet de bord, pas une fonctionnalité officielle sur laquelle on peut bâtir une stratégie. Le moteur se réserve le droit de changer ce comportement à tout moment.
Que se passe-t-il si je veux bloquer une URL mentionnée dans mes données structurées ?
Deux solutions : robots.txt pour interdire le crawl en amont, ou rel=canonical pour indiquer qu'une autre version fait autorité. Mueller est clair là-dessus — les données structurées ne constituent pas un mécanisme de contrôle du crawl.
Si vous ne voulez pas qu'une page soit indexée, ne comptez pas sur l'absence de lien HTML pour la protéger. Bloquez-la explicitement.
- Les données structurées peuvent contenir des URLs, mais le crawl n'est pas garanti
- Pour assurer la découverte, utilisez des liens HTML avec ancre textuelle
- Pour bloquer, passez par robots.txt ou rel=canonical, pas par l'absence de lien
- Le rôle des données structurées reste l'enrichissement sémantique, pas la navigation
Avis d'un expert SEO
Cette déclaration est-elle cohérente avec les pratiques observées sur le terrain ?
Oui, mais avec des exceptions troublantes. On observe régulièrement que Google découvre des pages uniquement mentionnées dans des données structurées de type BreadcrumbList ou ItemList. Ces URLs apparaissent ensuite dans la Search Console sans qu'aucun lien HTML interne ne les référence.
Le problème : ce comportement n'est ni constant, ni documenté. Certains sites constatent un crawl systématique, d'autres jamais. Impossible de prédire quand Google activera ce mécanisme. [A vérifier] selon les types de Schema et la fréquence de crawl du site.
Quelles nuances faut-il apporter à cette règle ?
Mueller parle de découverte et crawl, mais ne mentionne pas l'indexation. Même si Google crawle une URL trouvée dans vos données structurées, rien ne garantit qu'elle sera indexée — surtout sans backlinks ni maillage interne pour la soutenir.
Par ailleurs, certains types de Schema incluent des URLs qui ne sont pas censées être crawlées — pensez aux propriétés url de Organization pointant vers des réseaux sociaux ou des plateformes tierces. Google doit distinguer ces cas, mais la logique exacte reste floue.
Dans quels cas cette règle ne s'applique-t-elle pas totalement ?
Les pages AMP et les contenus structurés pour Google Actualités ou Google Shopping semblent bénéficier d'un traitement différent. Les URLs référencées dans des flux XML ou des balises spécifiques (comme amphtml) sont systématiquement suivies.
De même, certains crawls provoqués par des événements spéciaux — mise à jour d'un produit, nouveau contenu signalé via IndexNow ou Search Console — peuvent déclencher le suivi d'URLs trouvées dans les données structurées. Mais là encore, aucune garantie contractuelle.
Impact pratique et recommandations
Que faut-il faire concrètement pour garantir le crawl de ses pages ?
La réponse est simple : créez des liens HTML classiques avec ancres textuelles. C'est le signal le plus fiable pour indiquer à Google qu'une page mérite d'être crawlée et indexée.
Intégrez ces liens dans votre maillage interne — navigation principale, menu, contenu éditorial, footer si pertinent. Plus une page reçoit de liens internes de qualité, plus elle sera crawlée rapidement et régulièrement.
Quelles erreurs éviter avec les URLs dans les données structurées ?
Première erreur : croire que mentionner une URL dans vos données structurées suffit à la faire indexer. Si Google ne la crawle pas, vous perdez du temps.
Deuxième erreur : utiliser les données structurées comme mécanisme de contrôle du crawl. Si vous ne voulez pas qu'une page soit explorée, bloquez-la explicitement — ne vous contentez pas de retirer les liens HTML en espérant que les données structurées ne la révèlent pas.
Troisième erreur : négliger la cohérence entre vos liens HTML et vos données structurées. Si une BreadcrumbList référence une URL absente du DOM, cela crée de la confusion — et potentiellement des signaux contradictoires pour le moteur.
Comment vérifier que votre site est conforme aux recommandations de Google ?
- Auditez vos pages stratégiques : chaque URL importante doit avoir au moins un lien HTML interne
- Vérifiez que vos données structurées ne contiennent pas d'URLs orphelines (sans lien HTML correspondant)
- Contrôlez votre fichier robots.txt : toute page que vous ne voulez pas voir crawlée doit y figurer
- Utilisez rel=canonical pour signaler les versions prioritaires et éviter le crawl de variantes
- Testez vos données structurées avec le Rich Results Test pour détecter les erreurs
- Surveillez la Search Console : repérez les pages découvertes sans lien HTML apparent — cela révèle un crawl via données structurées
Les données structurées enrichissent vos pages, mais ne remplacent jamais un maillage interne solide. Pour maîtriser le crawl, combinez liens HTML classiques, robots.txt et canonical — et considérez les URLs dans vos schemas comme un bonus incertain, jamais une garantie.
Ces optimisations croisées entre structure technique, maillage et sémantique demandent une expertise pointue et une vision d'ensemble. Si vous souhaitez éviter les écueils et maximiser vos chances de crawl optimal, un accompagnement par une agence SEO spécialisée peut s'avérer judicieux pour poser les bonnes bases dès le départ.
❓ Questions frequentes
Les URLs dans mes données structurées de type BreadcrumbList sont-elles toujours crawlées ?
Dois-je retirer les URLs de mes données structurées si je ne veux pas qu'elles soient crawlées ?
Est-ce que Google indexe toutes les URLs qu'il crawle via les données structurées ?
Les données structurées peuvent-elles remplacer le maillage interne pour la découverte de pages ?
Faut-il éviter de mentionner des URLs externes dans mes données structurées ?
🎥 De la même vidéo 12
Autres enseignements SEO extraits de cette même vidéo Google Search Central · publiée le 08/06/2022
🎥 Voir la vidéo complète sur YouTube →
💬 Commentaires (0)
Soyez le premier à commenter.