Declaration officielle
Autres déclarations de cette vidéo 12 ▾
- □ Google suit-il vraiment tous les codes HTTP ou s'arrête-t-il au premier rencontré ?
- □ Un CDN améliore-t-il vraiment votre classement Google ?
- □ Faut-il vraiment bannir le nofollow des liens internes ?
- □ Faut-il arrêter de se fier à la commande site: pour mesurer l'indexation ?
- □ Pourquoi Google préfère-t-il les redirections serveur aux redirections JavaScript ?
- □ Faut-il vraiment différencier les redirections 301 et 302 pour le SEO ?
- □ Faut-il vraiment isoler vos contenus archivés pour améliorer votre SEO ?
- □ Peut-on vraiment forcer l'affichage des sitelinks dans Google ?
- □ Faut-il vraiment abandonner les iframes et les PDF pour indexer du contenu textuel ?
- □ Faut-il vraiment bloquer ou masquer les liens externes pour protéger son PageRank ?
- □ Google favorise-t-il vraiment certaines plateformes CMS pour le référencement ?
- □ Les URLs dans les données structurées sont-elles crawlées par Google ?
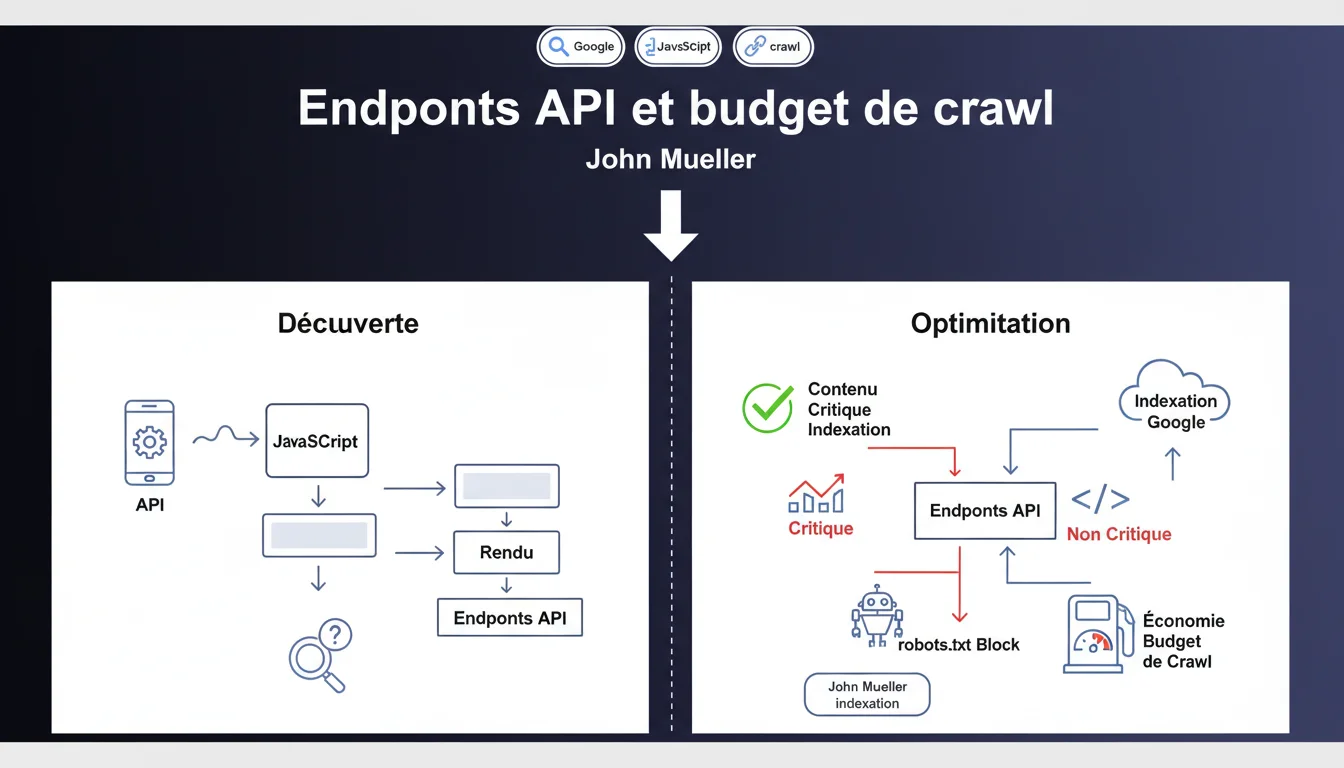
Google découvre les endpoints API en exécutant le JavaScript de vos pages. Si ces API ne fournissent pas de contenu essentiel à l'indexation, Mueller recommande de les bloquer via robots.txt pour préserver le budget de crawl. Une optimisation souvent négligée qui peut faire la différence sur les gros sites.
Ce qu'il faut comprendre
Comment Google découvre-t-il les endpoints API de votre site ?
Google ne limite pas sa découverte aux liens HTML classiques. Lors du rendu JavaScript, le bot identifie également les appels vers des endpoints API effectués par vos scripts. Chaque requête vers une API est potentiellement crawlée, ce qui consomme votre budget.
Le problème ? Ces endpoints renvoient souvent du JSON brut, des données structurées ou des fragments qui ne contiennent aucun contenu textuel indexable. Googlebot perd du temps et des ressources sur des URLs qui n'apportent rien à votre visibilité.
Tous les endpoints API doivent-ils être bloqués ?
Non. La nuance est capitale : Mueller parle d'endpoints qui ne contiennent pas de contenu critique pour l'indexation. Si une API retourne du texte unique, des descriptions produits ou tout élément qui enrichit vos pages, elle doit rester accessible.
Concrètement, ciblez les endpoints purement techniques : authentification, tracking, logs, analytics internes, préférences utilisateur. Tout ce qui sert uniquement au fonctionnement applicatif sans valeur SEO.
Le budget de crawl est-il vraiment un enjeu pour tous les sites ?
Soyons honnêtes — la majorité des petits sites n'ont pas de problème de budget de crawl. Google explore sans difficulté quelques centaines ou milliers de pages. Cette optimisation concerne surtout les gros inventaires, les plateformes avec génération dynamique massive, ou les sites avec architecture JS lourde.
Si votre Search Console montre que certaines pages ne sont pas crawlées faute de budget, alors oui, chaque optimisation compte. Sinon, ce n'est probablement pas votre priorité numéro un.
- Google découvre les API via le rendu JavaScript, pas seulement via sitemap
- Seuls les endpoints sans contenu indexable critique doivent être bloqués
- Cette optimisation concerne principalement les sites de grande taille ou avec architecture JS complexe
- Vérifiez votre Search Console avant d'agir — le budget de crawl n'est pas un problème universel
Avis d'un expert SEO
Cette recommandation est-elle cohérente avec les pratiques terrain observées ?
Totalement. On observe régulièrement dans les logs Googlebot des crawls massifs d'endpoints API qui ne servent à rien pour l'indexation. Analytics internes, APIs de session, webhooks — autant de ressources gaspillées qui auraient pu être allouées à du vrai contenu.
Cependant — et c'est là que ça coince — beaucoup de développeurs ne distinguent pas clairement les API « techniques » des API « contenu ». Résultat : soit tout est ouvert (gaspillage), soit tout est bloqué (perte de contenu indexable). La granularité est essentielle.
Quelles nuances faut-il apporter à cette déclaration ?
Mueller reste volontairement vague sur ce qu'il entend par « contenu critique ». [À vérifier] dans chaque contexte spécifique. Une API qui retourne des avis clients en JSON peut être critique si ces avis sont ensuite injectés dans le DOM visible — mais inutile si le contenu est déjà présent dans le HTML initial.
Autre point : bloquer un endpoint via robots.txt ne l'empêche pas d'être découvert. Google voit toujours l'URL dans le code source, il ne la crawle simplement pas. Si l'objectif est aussi de réduire la surface d'attaque ou de cacher des URLs, robots.txt ne suffit pas.
Dans quels cas cette règle ne s'applique-t-elle pas ?
Si votre site génère le HTML complet côté serveur (SSR classique), vous n'avez probablement pas d'endpoints API exposés dans le rendu client. Cette recommandation cible spécifiquement les architectures client-side rendering, les PWA, les SPA React/Vue/Angular.
De même, si vos API sont déjà protégées par authentification ou tokens, Googlebot ne peut pas y accéder de toute façon. Pas besoin de robots.txt dans ce cas — bien que bloquer explicitement reste une bonne pratique pour clarifier l'intention.
Impact pratique et recommandations
Que faut-il faire concrètement pour identifier les endpoints à bloquer ?
Première étape : analysez vos logs serveur pour repérer les URLs crawlées par Googlebot qui correspondent à des endpoints API. Cherchez les patterns récurrents (/api/, /v1/, /graphql, /rest/, etc.). Croisez avec votre documentation technique pour identifier la nature du contenu retourné.
Ensuite, utilisez un outil de rendu JavaScript (Screaming Frog, OnCrawl, Botify) pour capturer tous les appels réseau effectués lors du chargement de vos pages clés. Listez chaque endpoint et classez-les : contenu indexable vs. technique pur.
Comment configurer robots.txt pour bloquer ces endpoints efficacement ?
Ajoutez des directives Disallow ciblées pour chaque pattern d'endpoint. Exemple :
User-agent: *
Disallow: /api/auth/
Disallow: /api/analytics/
Disallow: /api/session/
Évitez les wildcards trop larges qui pourraient bloquer des APIs légitimes. Testez chaque règle avec l'outil de test robots.txt de la Search Console. Surveillez ensuite vos rapports de couverture pour détecter toute page légitime accidentellement bloquée.
Quelles erreurs éviter lors de cette optimisation ?
Ne bloquez jamais un endpoint sans avoir vérifié qu'il ne contribue pas au contenu indexé. Testez en mode incognito avec JavaScript désactivé — si le contenu disparaît et qu'il n'est pas rendu côté serveur, c'est probablement servi par une API qu'il ne faut pas bloquer.
Autre piège : bloquer des endpoints qui servent des données structurées (schema.org) injectées dynamiquement. Google peut en avoir besoin pour comprendre vos entités et générer des rich snippets.
- Auditez vos logs pour identifier les endpoints API crawlés par Googlebot
- Classez chaque endpoint selon sa criticité pour l'indexation (contenu vs. technique)
- Bloquez via robots.txt uniquement les API sans contenu indexable
- Testez chaque règle dans la Search Console avant déploiement production
- Surveillez les rapports de couverture post-déploiement pour détecter les effets indésirables
- Documentez vos choix pour faciliter les futures évolutions techniques
❓ Questions frequentes
Bloquer un endpoint API via robots.txt améliore-t-il directement mon positionnement ?
Comment savoir si mon site a un problème de budget de crawl ?
Peut-on bloquer des endpoints API tout en les gardant accessibles pour les utilisateurs ?
Faut-il bloquer les endpoints GraphQL utilisés pour charger du contenu dynamique ?
Les CDN d'API tierces (Stripe, analytics, etc.) doivent-ils aussi être bloqués ?
🎥 De la même vidéo 12
Autres enseignements SEO extraits de cette même vidéo Google Search Central · publiée le 08/06/2022
🎥 Voir la vidéo complète sur YouTube →
💬 Commentaires (0)
Soyez le premier à commenter.