Declaration officielle
Autres déclarations de cette vidéo 16 ▾
- □ Le balisage Local Business doit-il vraiment se limiter à une seule ville ?
- □ Faut-il vraiment migrer 1:1 sans rien changer lors d'un changement de domaine ?
- □ Schema.org : pourquoi Google ignore-t-il une partie de vos balises structurées ?
- □ Faut-il vraiment rédiger du texte descriptif autour de vos illustrations pour ranker dans Google Images ?
- □ Faut-il publier tous les jours pour améliorer son référencement Google ?
- □ Le nombre de mots est-il vraiment sans importance pour le référencement ?
- □ Les mots-clés dans les URLs ont-ils encore un impact en SEO ?
- □ Peut-on vraiment lancer deux sites quasi-identiques sans risquer de pénalité Google ?
- □ Pourquoi vos liens JavaScript doivent absolument utiliser des balises A avec href valide ?
- □ L'audio sur une page influence-t-il réellement le classement Google ?
- □ Faut-il vraiment éviter de modifier les balises meta avec JavaScript ?
- □ Les mises à jour algorithmiques de Google sont-elles vraiment différentes des pénalités ?
- □ Pourquoi Google ne communique-t-il que sur une fraction de ses mises à jour d'algorithme ?
- □ Les données structurées améliorent-elles vraiment votre classement dans Google ?
- □ Faut-il vraiment éviter d'utiliser noindex et canonical sur la même page ?
- □ Les données structurées vidéo servent-elles uniquement à l'indexation ?
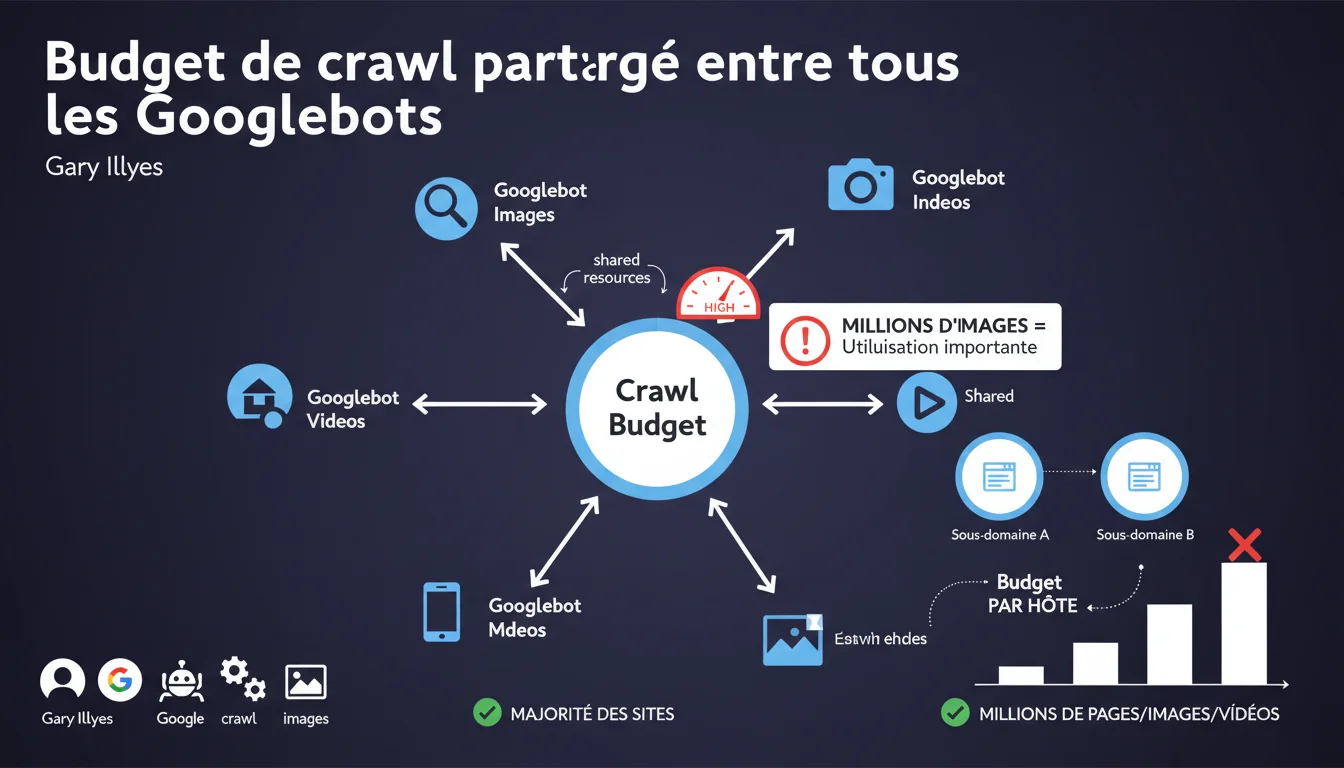
Googlebot et ses variantes (Images, News, etc.) partagent un seul et même budget de crawl par hôte. Si votre site héberge des millions d'images, Googlebot Images peut consommer une partie significative du budget qui aurait pu être alloué au crawl de vos pages HTML. Chaque sous-domaine dispose de son propre budget, ce qui ouvre des possibilités d'optimisation architecturale.
Ce qu'il faut comprendre
Que signifie concrètement ce partage de budget de crawl ?
Quand Gary Illyes parle d'un budget de crawl partagé, il confirme que Google ne segmente pas les ressources de crawl par type de contenu. Que Googlebot classique explore vos pages HTML ou que Googlebot Images scanne vos JPG, tout puise dans le même réservoir.
Pour un site lambda avec quelques centaines ou milliers de pages, cette notion reste théorique. Le budget de crawl n'est pas le facteur limitant — votre capacité serveur, la qualité du contenu et la structure technique importent davantage. Mais quand vous gérez des millions de ressources (e-commerce massif, plateforme média, sites d'images), la donne change.
Pourquoi cette déclaration cible-t-elle spécifiquement les gros sites ?
Les petits et moyens sites bénéficient généralement d'un budget de crawl supérieur à leurs besoins réels. Google peut explorer 10 000 URLs par jour alors que vous en publiez 50 par mois — aucun risque de saturation.
En revanche, un site avec 5 millions d'images produit fait face à un arbitrage permanent. Si Googlebot Images mobilise 60% du budget quotidien pour scanner des visuels redondants ou de faible valeur ajoutée, vos nouvelles fiches produits ou articles stratégiques peuvent attendre des jours avant d'être crawlés.
Qu'apporte la précision sur les sous-domaines ?
L'information clé ici : chaque sous-domaine dispose de son propre budget de crawl. Ce n'est pas une révélation en soi, mais c'est la confirmation officielle qu'une architecture en sous-domaines peut servir de levier d'optimisation.
Si vous isolez vos millions d'images sur cdn.votresite.com ou img.votresite.com, vous scindez le problème. Le sous-domaine principal conserve son budget intact pour les contenus prioritaires, tandis que le CDN gère le crawl des ressources visuelles sans cannibaliser les pages à fort ROI.
- Budget de crawl unique par hôte, partagé entre tous les Googlebots (standard, Images, News, etc.)
- Problématique pertinente uniquement pour les sites à très forte volumétrie (millions de ressources)
- Chaque sous-domaine dispose d'un budget de crawl distinct et indépendant
- Les petits sites n'ont pas à s'inquiéter — leur budget excède largement leurs besoins
Avis d'un expert SEO
Cette déclaration est-elle alignée avec ce qu'on observe sur le terrain ?
Oui, globalement. Les audits de logs sur des plateformes à forte volumétrie montrent effectivement que Googlebot Images peut représenter 30 à 50% du crawl total sur certains sites e-commerce ou médias riches en visuels. Ce n'est pas anecdotique.
Là où ça coince, c'est que Google reste évasif sur les seuils exacts. « Des millions de pages » — OK, mais à partir de combien précisément le budget devient-il un facteur limitant ? 500 000 URLs ? 2 millions ? 10 millions ? [À vérifier] car Google ne fournit pas de données chiffrées exploitables.
Quelles nuances faut-il apporter à ce conseil ?
Première nuance : tous les Googlebots ne se valent pas en termes de consommation de ressources. Googlebot Images peut techniquement crawler plus vite que Googlebot classique car les images ne nécessitent pas de rendu JavaScript complexe ni d'analyse sémantique lourde.
Deuxième nuance : le budget de crawl n'est pas fixe. Google l'ajuste dynamiquement en fonction de la santé serveur, de la popularité du site, de la fraîcheur des contenus. Si votre serveur encaisse bien la charge et que vos pages génèrent du trafic, Google augmente naturellement votre budget — dans certaines limites.
Dans quels cas cette règle devient-elle critique ?
Soyons honnêtes : pour 95% des sites, c'est un non-sujet. Même un site e-commerce avec 50 000 produits et 200 000 images associées ne rencontrera probablement jamais de friction réelle.
Ça devient critique quand vous cumulez : volumétrie massive (millions de ressources), fréquence de publication élevée (milliers de nouveaux contenus par jour), et architecture technique sous-optimale (temps de réponse serveur lents, pagination infinie mal gérée, duplication). Là, le budget de crawl devient un goulot d'étranglement mesurable.
Impact pratique et recommandations
Que faut-il faire concrètement si vous gérez un gros site ?
Première étape : auditez vos logs serveur. Identifiez la répartition du crawl entre Googlebot classique, Googlebot Images, et autres variantes. Si Googlebot Images consomme plus de 40% de votre budget alors que vos images n'apportent pas de trafic SEO significatif, vous avez un levier d'optimisation.
Deuxième action : priorisez les contenus stratégiques. Utilisez robots.txt pour bloquer le crawl des images redondantes ou de faible valeur (miniatures, versions multiples du même visuel). Exploitez les directives noindex pour éviter que Google perde du temps sur des ressources non indexables.
L'architecture en sous-domaines est-elle la solution miracle ?
Pas systématiquement. Migrer vos images sur un sous-domaine dédié peut effectivement isoler leur budget de crawl, mais ça introduit des complexités techniques : gestion des CORS, duplication potentielle de certificats SSL, impact sur le temps de chargement si le CDN n'est pas bien configuré.
C'est une stratégie pertinente pour les plateformes qui hébergent des dizaines de millions de ressources et constatent des délais de crawl anormaux sur leurs pages prioritaires. Pour les autres, optimiser la structure interne et le temps de réponse serveur aura un impact bien supérieur.
Comment mesurer l'impact réel sur votre site ?
Installez un système de monitoring des logs serveur (Oncrawl, Botify, ou solutions maison via ELK/Splunk). Tracez le volume de crawl quotidien par type de Googlebot, croisez avec les données de Google Search Console (pages explorées vs pages indexées).
Si vous détectez un décalage anormal entre la publication de contenus prioritaires et leur apparition dans l'index, et que vos logs montrent une saturation du budget par Googlebot Images, alors vous avez confirmé le problème — et il est temps d'agir.
- Analysez la répartition du crawl entre les différents Googlebots via vos logs serveur
- Bloquez ou dé-priorisez les ressources visuelles de faible valeur SEO avec
robots.txt - Envisagez une architecture en sous-domaines uniquement si vous gérez plusieurs millions de ressources
- Optimisez le temps de réponse serveur et la structure de liens internes avant de blâmer le budget de crawl
- Surveillez les délais entre publication et indexation pour détecter des goulots d'étranglement
❓ Questions frequentes
À partir de combien de pages le budget de crawl devient-il un vrai problème ?
Si je bloque mes images dans robots.txt, est-ce que Google Image Search les indexera quand même ?
Dois-je créer un sous-domaine dédié pour mes images même si j'ai « seulement » 100 000 visuels ?
Est-ce que le budget de crawl d'un sous-domaine peut être transféré au domaine principal ?
Comment savoir si Googlebot Images consomme trop de mon budget de crawl ?
🎥 De la même vidéo 16
Autres enseignements SEO extraits de cette même vidéo Google Search Central · publiée le 07/09/2022
🎥 Voir la vidéo complète sur YouTube →
💬 Commentaires (0)
Soyez le premier à commenter.