Declaration officielle
Autres déclarations de cette vidéo 16 ▾
- □ Le balisage Local Business doit-il vraiment se limiter à une seule ville ?
- □ Faut-il vraiment migrer 1:1 sans rien changer lors d'un changement de domaine ?
- □ Schema.org : pourquoi Google ignore-t-il une partie de vos balises structurées ?
- □ Faut-il vraiment rédiger du texte descriptif autour de vos illustrations pour ranker dans Google Images ?
- □ Faut-il publier tous les jours pour améliorer son référencement Google ?
- □ Le nombre de mots est-il vraiment sans importance pour le référencement ?
- □ Les mots-clés dans les URLs ont-ils encore un impact en SEO ?
- □ Les images consomment-elles vraiment du budget de crawl au détriment de vos pages stratégiques ?
- □ Peut-on vraiment lancer deux sites quasi-identiques sans risquer de pénalité Google ?
- □ Pourquoi vos liens JavaScript doivent absolument utiliser des balises A avec href valide ?
- □ L'audio sur une page influence-t-il réellement le classement Google ?
- □ Faut-il vraiment éviter de modifier les balises meta avec JavaScript ?
- □ Les mises à jour algorithmiques de Google sont-elles vraiment différentes des pénalités ?
- □ Pourquoi Google ne communique-t-il que sur une fraction de ses mises à jour d'algorithme ?
- □ Les données structurées améliorent-elles vraiment votre classement dans Google ?
- □ Les données structurées vidéo servent-elles uniquement à l'indexation ?
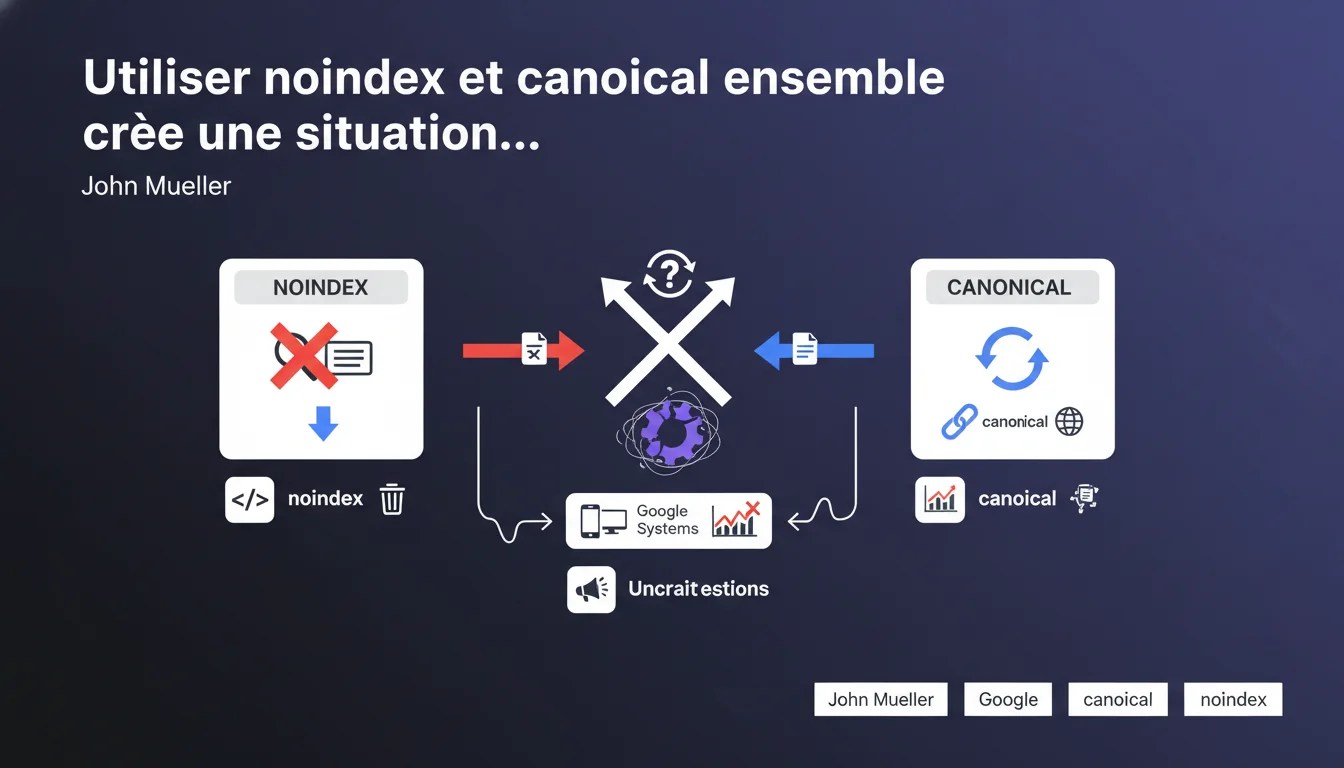
Combiner noindex et rel=canonical sur une même URL crée un conflit d'instructions pour Google : l'une demande la suppression de l'indexation, l'autre indique une version préférée à indexer. Le moteur fera « de son mieux » mais sans garantie de résultat. Pour un contrôle précis, il faut choisir une directive claire et cohérente.
Ce qu'il faut comprendre
Pourquoi ces deux directives sont-elles incompatibles ?
Le noindex indique explicitement aux moteurs de recherche de ne pas indexer la page concernée. C'est une instruction ferme qui demande la suppression complète de l'URL des résultats de recherche.
Le rel=canonical, lui, signale qu'une autre page constitue la version de référence. Il suggère que le contenu et les signaux doivent être transférés vers cette URL canonique — ce qui implique logiquement qu'il existe quelque chose à transférer, donc à indexer quelque part.
Utiliser les deux simultanément revient à dire « n'indexe pas cette page » et « transfère tout vers cette autre version » — une contradiction que les algorithmes doivent arbitrer sans directive claire.
Comment Google gère-t-il ce conflit en pratique ?
Mueller précise que les systèmes Google « feront de leur mieux », ce qui traduit une absence de comportement garanti. Concrètement, cela signifie que le moteur choisira une directive selon sa propre logique interne — et ce choix peut varier selon les crawls, les mises à jour ou les contextes.
Cette situation crée une imprévisibilité : impossible de savoir si Google privilégiera le noindex (et supprimera la page) ou le canonical (et tentera un transfert de signaux). Pour un professionnel qui cherche un contrôle précis de son indexation, c'est inacceptable.
Quels sont les cas où cette configuration apparaît malgré tout ?
Ce conflit surgit souvent dans les configurations CMS mal paramétrées : des templates qui appliquent systématiquement un canonical vers une version « propre » tout en ajoutant un noindex sur certaines pages (paginations, filtres, variantes).
On le trouve aussi dans les migrations techniques où des directives contradictoires subsistent par erreur, ou dans les cas où plusieurs équipes interviennent sans coordination sur les aspects technique et SEO.
- Noindex : instruction de suppression complète de l'indexation
- Canonical : suggestion de version préférée avec transfert de signaux
- Combinaison = conflit logique sans résultat garanti
- Google arbitre selon sa propre logique, de façon imprévisible
- Origine fréquente : erreurs CMS ou manque de coordination technique
Avis d'un expert SEO
Cette déclaration est-elle cohérente avec les observations terrain ?
Oui, et c'est même un constat que pas mal de SEO ont fait sans que Google le confirme aussi explicitement. Dans les audits techniques, on croise régulièrement des pages en noindex + canonical qui tantôt disparaissent de l'index, tantôt y restent pendant des semaines avant d'être finalement supprimées.
Ce que Mueller apporte ici, c'est la confirmation que ce flou n'est pas un bug mais une absence de spécification. Google ne garantit rien parce qu'on lui donne des instructions contradictoires. Ça paraît évident dit comme ça, mais combien de sites en production traînent ce genre de configuration bancale ?
Pourquoi Google ne force-t-il pas une hiérarchie claire entre ces directives ?
Bonne question. On pourrait imaginer qu'une directive aussi ferme que noindex écrase systématiquement toute autre instruction, canonical compris. Mais Google préfère visiblement laisser ses algorithmes « faire de leur mieux » — autrement dit, deviner l'intention réelle.
Le problème, c'est que cette approche crée de l'incertitude pour les praticiens. [À vérifier] : on ne dispose d'aucune donnée publique sur les critères exacts qui font pencher la balance d'un côté ou de l'autre. Est-ce l'ancienneté de la directive ? La cohérence du maillage interne ? Le nombre de signaux externes ? Mueller ne le dit pas, et c'est frustrant.
Un SEO qui cherche la maîtrise technique ne peut pas se satisfaire d'un « on verra bien ce qui se passe ». Soyons honnêtes : c'est typiquement le genre de réponse qui pousse à tout tester en conditions réelles avant de déployer.
Dans quels cas cette configuration peut-elle sembler tentante ?
Certains SEO pensent combiner noindex + canonical pour « garder le jus tout en évitant l'indexation ». L'idée : empêcher une page de polluer l'index tout en consolidant ses signaux vers la version canonique. Ça paraît malin sur le papier.
Sauf que cette logique repose sur un malentendu. Si Google honore le noindex, il ne transfèrera probablement pas les signaux — parce qu'une page non indexée ne mérite pas qu'on consolide ses signaux ailleurs. Si au contraire il privilégie le canonical, alors le noindex sera ignoré et la page restera indexée. Dans les deux cas, l'objectif initial échoue.
Impact pratique et recommandations
Que faut-il faire concrètement quand on détecte cette configuration ?
D'abord, identifier toutes les pages concernées. Un crawl avec Screaming Frog ou un outil équivalent permet de repérer rapidement les URLs portant à la fois un meta robots noindex et un rel=canonical vers une autre page.
Ensuite, trancher : qu'est-ce qu'on veut vraiment pour chaque URL ? Si l'objectif est la désindexation complète, on garde le noindex et on retire le canonical. Si l'objectif est la consolidation vers une version de référence, on retire le noindex et on s'assure que le canonical pointe correctement.
Et si le cas de figure est plus complexe — par exemple, une pagination qu'on souhaite désindexer mais dont on veut transférer les signaux vers la page principale — alors la solution passe par une redirection 301, pas par des directives contradictoires.
Quelles erreurs éviter absolument dans ce contexte ?
Première erreur classique : laisser trainer cette configuration en se disant « Google se débrouillera ». Non. Google le dit explicitement : le résultat n'est pas garanti. Impossible de construire une stratégie SEO solide sur de l'aléatoire.
Deuxième erreur : appliquer un canonical « par défaut » sur toutes les pages sans réfléchir à leur statut d'indexation. Beaucoup de CMS font ça. Résultat, des pages en noindex se retrouvent avec un canonical actif, créant exactement le conflit pointé par Mueller.
Troisième erreur : croire qu'une page en noindex transmet quand même du PageRank via son canonical. Rien ne le prouve, et la logique algorithmique suggère plutôt l'inverse.
Comment auditer et corriger son site à grande échelle ?
Pour un site de taille moyenne à importante, l'audit manuel n'est pas envisageable. Il faut automatiser la détection via un crawl complet, puis croiser les données : pages avec balise noindex ET canonical différent de self-canonical.
Ensuite, analyser chaque segment : les paginations, les filtres, les pages produit en fin de vie, les variantes régionales. Chaque typologie demande une décision cohérente appliquée de façon systématique.
- Crawler le site pour détecter les pages avec noindex + canonical actif
- Segmenter les URLs concernées par typologie (pagination, filtres, etc.)
- Décider pour chaque segment : désindexation complète (noindex seul) ou consolidation (canonical seul)
- Si transfert de signaux nécessaire, privilégier la redirection 301 plutôt qu'un canonical conflictuel
- Retirer systématiquement le canonical des pages qu'on souhaite réellement désindexer
- Vérifier après déploiement que Google Search Console reflète bien le comportement attendu
- Documenter les règles appliquées pour éviter toute régression lors des futures évolutions CMS
❓ Questions frequentes
Peut-on utiliser noindex et canonical pour conserver le PageRank tout en désindexant une page ?
Que se passe-t-il concrètement quand Google détecte noindex + canonical sur la même page ?
Comment savoir si mon CMS génère automatiquement ce conflit ?
Le X-Robots-Tag noindex est-il concerné par ce conflit avec canonical ?
Si je retire le canonical d'une page en noindex, vais-je perdre du PageRank ?
🎥 De la même vidéo 16
Autres enseignements SEO extraits de cette même vidéo Google Search Central · publiée le 07/09/2022
🎥 Voir la vidéo complète sur YouTube →
💬 Commentaires (0)
Soyez le premier à commenter.