Official statement
Other statements from this video 12 ▾
- □ Does Google really follow every HTTP status code in a chain, or does it stop at the first one?
- □ Does a CDN really improve your Google rankings?
- □ Should you really ban nofollow from your internal links?
- □ Should you stop relying on the site: command to measure indexation?
- □ Why does Google really prefer server-side redirects over JavaScript redirects?
- □ Should you really care about the difference between 301 and 302 redirects for SEO?
- □ Should you really isolate your archived content to boost your SEO performance?
- □ Can you really force Google to display sitelinks in search results?
- □ Should you really abandon PDFs and iframes if you want your text content to rank properly?
- □ Is it really worth blocking or hiding external links to protect your PageRank?
- □ Does Google really favor certain CMS platforms for SEO rankings?
- □ Does Google really crawl URLs found in your structured data?
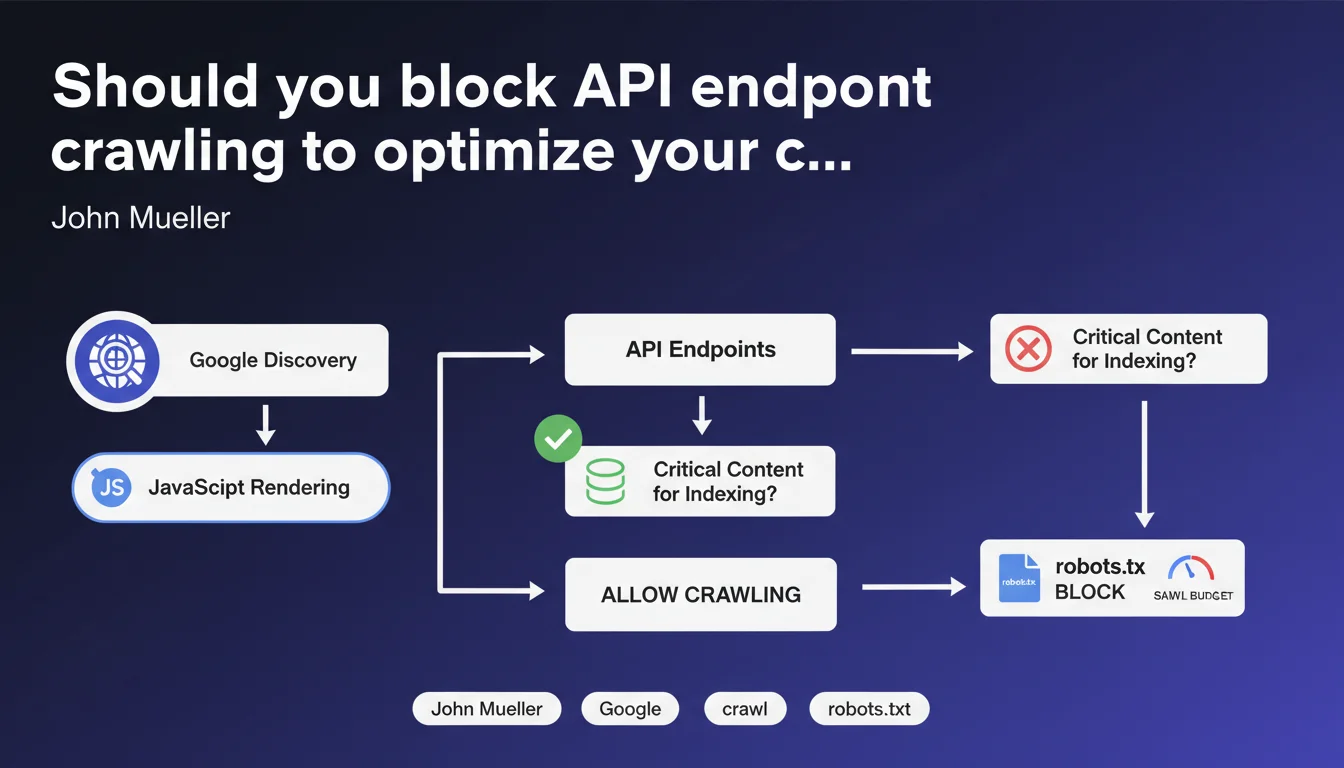
Google discovers API endpoints by executing the JavaScript on your pages. If these APIs don't provide content essential for indexing, Mueller recommends blocking them via robots.txt to preserve crawl budget. An often-overlooked optimization that can make a real difference on large sites.
What you need to understand
How does Google discover the API endpoints on your site?
Google doesn't limit its discovery to classic HTML links. During JavaScript rendering, the bot also identifies calls to API endpoints made by your scripts. Each request to an API is potentially crawled, consuming your budget.
The problem? These endpoints often return raw JSON, structured data, or fragments that contain no indexable text content. Googlebot wastes time and resources on URLs that provide nothing to your visibility.
Should all API endpoints be blocked?
No. This distinction is critical: Mueller refers to endpoints that don't contain content critical for indexing. If an API returns unique text, product descriptions, or any element that enriches your pages, it should remain accessible.
Concretely, target purely technical endpoints: authentication, tracking, logs, internal analytics, user preferences. Everything that serves only application functionality without SEO value.
Is crawl budget really an issue for all sites?
Let's be honest — the majority of small sites don't have a crawl budget problem. Google explores without difficulty several hundred or thousands of pages. This optimization mainly concerns large inventories, platforms with massive dynamic generation, or sites with heavy JavaScript architecture.
If your Search Console shows that certain pages aren't being crawled due to budget constraints, then yes, every optimization counts. Otherwise, it's probably not your number one priority.
- Google discovers APIs through JavaScript rendering, not just via sitemap
- Only endpoints without critical indexable content should be blocked
- This optimization mainly concerns large sites or those with complex JavaScript architecture
- Check your Search Console before taking action — crawl budget isn't a universal problem
SEO Expert opinion
Is this recommendation consistent with field practices?
Absolutely. We regularly observe massive Googlebot crawls of API endpoints that serve no indexing purpose in server logs. Internal analytics, session APIs, webhooks — as many wasted resources that could have been allocated to actual content.
However — and here's where it gets tricky — many developers don't clearly distinguish between "technical" and "content" APIs. Result: either everything is open (waste), or everything is blocked (loss of indexable content). Granularity is essential.
What nuances should be added to this statement?
Mueller remains deliberately vague about what he means by "critical content". [To verify] in each specific context. An API that returns customer reviews in JSON might be critical if those reviews are then injected into the visible DOM — but unnecessary if the content is already in the initial HTML.
Another point: blocking an endpoint via robots.txt doesn't prevent it from being discovered. Google still sees the URL in the source code, it simply doesn't crawl it. If the goal is also to reduce attack surface or hide URLs, robots.txt alone isn't enough.
In what cases doesn't this rule apply?
If your site generates complete HTML server-side (classic SSR), you probably don't have exposed API endpoints in client rendering. This recommendation specifically targets client-side rendering architectures, PWAs, React/Vue/Angular SPAs.
Similarly, if your APIs are already protected by authentication or tokens, Googlebot can't access them anyway. No need for robots.txt in this case — though blocking explicitly remains a good practice to clarify intent.
Practical impact and recommendations
What should you concretely do to identify endpoints to block?
First step: analyze your server logs to identify URLs crawled by Googlebot that correspond to API endpoints. Look for recurring patterns (/api/, /v1/, /graphql, /rest/, etc.). Cross-reference with your technical documentation to identify the nature of returned content.
Next, use a JavaScript rendering tool (Screaming Frog, OnCrawl, Botify) to capture all network calls made when loading your key pages. List each endpoint and classify them: indexable content vs. purely technical.
How do you configure robots.txt to effectively block these endpoints?
Add targeted Disallow directives for each endpoint pattern. Example:
User-agent: *
Disallow: /api/auth/
Disallow: /api/analytics/
Disallow: /api/session/
Avoid overly broad wildcards that could block legitimate APIs. Test each rule with the Search Console robots.txt testing tool. Then monitor your coverage reports to detect any legitimate pages accidentally blocked.
What mistakes should you avoid with this optimization?
Never block an endpoint without verifying it doesn't contribute to indexed content. Test in incognito mode with JavaScript disabled — if content disappears and isn't rendered server-side, it's probably served by an API you shouldn't block.
Another trap: blocking endpoints that serve dynamically injected structured data (schema.org). Google may need it to understand your entities and generate rich snippets.
- Audit your logs to identify API endpoints crawled by Googlebot
- Classify each endpoint by its criticality for indexing (content vs. technical)
- Block via robots.txt only APIs without indexable content
- Test each rule in Search Console before production deployment
- Monitor coverage reports post-deployment to detect unintended effects
- Document your choices to facilitate future technical evolutions
❓ Frequently Asked Questions
Bloquer un endpoint API via robots.txt améliore-t-il directement mon positionnement ?
Comment savoir si mon site a un problème de budget de crawl ?
Peut-on bloquer des endpoints API tout en les gardant accessibles pour les utilisateurs ?
Faut-il bloquer les endpoints GraphQL utilisés pour charger du contenu dynamique ?
Les CDN d'API tierces (Stripe, analytics, etc.) doivent-ils aussi être bloqués ?
🎥 From the same video 12
Other SEO insights extracted from this same Google Search Central video · published on 08/06/2022
🎥 Watch the full video on YouTube →
💬 Comments (0)
Be the first to comment.