Official statement
Other statements from this video 19 ▾
- □ Google indexe-t-il vraiment toutes les langues de la même manière ?
- □ Les liens nofollow et balises noindex nuisent-ils à votre référencement ?
- □ Les erreurs 404 pénalisent-elles vraiment le classement de votre site ?
- □ Faut-il vraiment rediriger toutes les pages 404 pour améliorer son SEO ?
- □ La vitesse de votre CDN d'images pénalise-t-elle vraiment votre référencement dans Google Images ?
- □ Peut-on réinitialiser les données Search Console d'un site repris ?
- □ Les sous-domaines régionaux suffisent-ils à cibler un marché géographique ?
- □ Pourquoi vos rich results affichent-ils la mauvaise devise et comment y remédier ?
- □ La transcription vidéo est-elle considérée comme du contenu dupliqué par Google ?
- □ Pourquoi Google refuse-t-il les avis agrégés dans les données structurées produit ?
- □ Google crawle-t-il les variations d'URL sans liens internes ou backlinks ?
- □ Pourquoi Googlebot persiste-t-il à crawler des pages 404 après leur suppression ?
- □ Le ratio texte/code est-il vraiment un facteur de classement Google ?
- □ Les paramètres UTM avec medium=referral tuent-ils vraiment la valeur SEO d'un backlink ?
- □ Faut-il absolument répondre aux commentaires de blog pour le SEO ?
- □ Faut-il s'inquiéter quand robots.txt apparaît comme soft 404 dans Search Console ?
- □ Pourquoi les redirections Geo IP automatiques sabotent-elles votre SEO international ?
- □ Modifier ses balises title et meta description peut-il vraiment faire bouger son classement Google ?
- □ Les liens ou le trafic de mauvaise qualité peuvent-ils nuire à la réputation de votre site ?
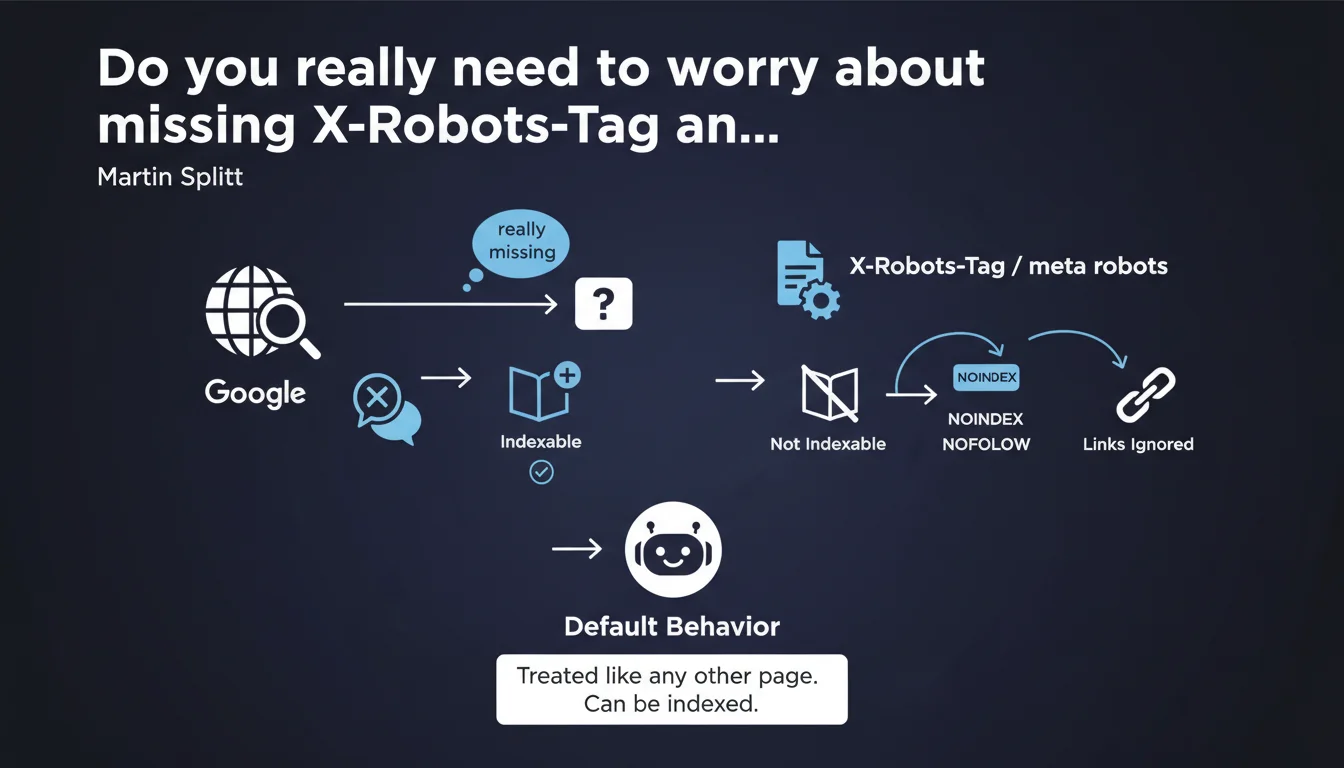
The absence of X-Robots-Tag or meta robots tags is not inherently a problem. These mechanisms only serve to give specific directives to search engines. Without them, the page is simply treated normally and can be indexed by default.
What you need to understand
Why does Google clarify robot tags in this way?
Martin Splitt reminds us of an obvious technical fact that seems to generate recurring questions among some SEO professionals. The X-Robots-Tag (HTTP header) and meta robots (HTML tag) are control tools, not prerequisites.
Their absence does not mean Google cannot crawl or index a page — quite the opposite. Without an explicit directive, the search engine applies its default behavior: crawl, analyze, and potentially index the content if it deems it relevant.
When do these tags become truly useful?
These mechanisms only make sense when you want to modify Google's standard behavior. Typically: block indexation (noindex), prevent link following (nofollow), forbid caching (noarchive), or limit snippet display (nosnippet).
Without any instructions to the contrary, Google assumes you accept standard treatment. This is a principle of implicit consent: silence equals acceptance.
- The absence of robot tags means the page can be indexed normally
- These tags are restriction tools, not indexation conditions
- The X-Robots-Tag (HTTP header) and meta robots (HTML) serve the same function; only the vector differs
- Explicit directives allow fine-grained control over indexation of certain sections: filter pages, PDFs, internal search results pages, etc.
How does Google handle the complete absence of directives?
In automatic mode. The crawler analyzes the content, evaluates its quality, detects duplication or low-quality signals, and independently decides whether indexation is worthwhile.
This autonomy can be problematic on complex websites where certain pages — deep pagination, multiple facets, printable versions — end up indexed when they shouldn't be. The absence of robot tags is not a bug, but a default choice that sometimes requires adjustments.
SEO Expert opinion
Is this statement consistent with real-world practices?
Yes, absolutely. Based on thousands of audits, we observe exactly this behavior: pages without explicit directives are crawled and indexed if they meet Google's quality criteria. No mystery here.
The problem emerges when sites leave useless pages indexed through negligence (login, cart, thank-you pages) that pollute the index and dilute crawl budget. The absence of robot tags then becomes an indirect problem — not technical, but strategic.
What nuances should be added to this statement?
Splitt talks about "treating a page differently," but this phrasing masks a more complex reality. Google can very well treat two pages without directives differently based on their content, structure, duplication, or depth in the site architecture.
The real issue is not the absence of a tag, but intentionality. If you let Google decide alone, you lose granular control. On an e-commerce site with 50,000 products and thousands of filter combinations, this loss of control can be catastrophic.
In which cases does this rule not really apply?
When robots.txt already blocks access. If a URL is disallowed in robots.txt, Google cannot crawl it and will never see any potential meta robots tag in the HTML. The X-Robots-Tag in HTTP header can still be read, but this is an edge case.
Another exception: sites requiring authentication. Without content access, Google cannot index anything, tags or not. The absence of a directive becomes irrelevant.
Practical impact and recommendations
What should you concretely do with robot tags?
First step: audit indexed pages via Search Console and identify those with no SEO value (admin pages, redundant filters, internal search results, tracking pages). Then, decide for each one: noindex or robots.txt blocking.
Second phase: define a clear indexation strategy. You don't need robot tags everywhere — only where you want to deviate from standard behavior. A 20-page brochure website can work fine without them altogether. A 100,000-URL e-commerce site must manage its directives rigorously.
- List all currently indexed pages via
site:yourdomain.comand Search Console - Identify pages with no SEO value: login, cart, checkout, thank-you, redundant filters, deep paginations
- Apply noindex to pages that should be crawled but not indexed (for internal linking)
- Block via robots.txt only pages that should neither be crawled nor indexed (crawl budget savings)
- Check logs to ensure Googlebot is not wasting resources on non-strategic sections
- Monitor indexation changes in Search Console after each modification
What mistakes should you avoid in managing robot tags?
Never combine noindex + robots.txt blocking on the same URL. If Google cannot crawl, it will never see the noindex and might keep the URL in the index with a truncated snippet. This is a classic mistake that generates Search Console alerts.
Also avoid global noindex by accident — a misconfigured X-Robots-Tag HTTP header at server level can destroy an entire site's indexation within days. Always test in development before pushing to production.
How can you verify that your robot directives management is optimal?
Three essential checks: inspect HTTP headers with tools like Screaming Frog or Chrome DevTools, analyze server logs to see which sections Googlebot visits most, and monitor the evolution of indexed pages in Search Console.
The goal is to maximize the ratio of strategic indexed pages / total pages crawled. If Google spends 40% of its time on useless pages, you have an architecture problem, not a tag problem.
❓ Frequently Asked Questions
Est-ce qu'ajouter des balises meta robots sur toutes mes pages améliore mon SEO ?
Quelle est la différence entre X-Robots-Tag et meta robots ?
Si je retire toutes mes balises noindex, Google va-t-il tout indexer d'un coup ?
Peut-on combiner plusieurs directives dans une même balise robots ?
Pourquoi Google indexe-t-il encore des pages bloquées par robots.txt ?
🎥 From the same video 19
Other SEO insights extracted from this same Google Search Central video · published on 21/08/2024
🎥 Watch the full video on YouTube →
💬 Comments (0)
Be the first to comment.