Declaration officielle
Autres déclarations de cette vidéo 19 ▾
- □ Google indexe-t-il vraiment toutes les langues de la même manière ?
- □ Les liens nofollow et balises noindex nuisent-ils à votre référencement ?
- □ Les erreurs 404 pénalisent-elles vraiment le classement de votre site ?
- □ Faut-il vraiment rediriger toutes les pages 404 pour améliorer son SEO ?
- □ La vitesse de votre CDN d'images pénalise-t-elle vraiment votre référencement dans Google Images ?
- □ Peut-on réinitialiser les données Search Console d'un site repris ?
- □ Les sous-domaines régionaux suffisent-ils à cibler un marché géographique ?
- □ Pourquoi vos rich results affichent-ils la mauvaise devise et comment y remédier ?
- □ La transcription vidéo est-elle considérée comme du contenu dupliqué par Google ?
- □ Pourquoi Google refuse-t-il les avis agrégés dans les données structurées produit ?
- □ Google crawle-t-il les variations d'URL sans liens internes ou backlinks ?
- □ Pourquoi Googlebot persiste-t-il à crawler des pages 404 après leur suppression ?
- □ Le ratio texte/code est-il vraiment un facteur de classement Google ?
- □ Les paramètres UTM avec medium=referral tuent-ils vraiment la valeur SEO d'un backlink ?
- □ Faut-il absolument répondre aux commentaires de blog pour le SEO ?
- □ Faut-il s'inquiéter quand robots.txt apparaît comme soft 404 dans Search Console ?
- □ Pourquoi les redirections Geo IP automatiques sabotent-elles votre SEO international ?
- □ Modifier ses balises title et meta description peut-il vraiment faire bouger son classement Google ?
- □ Les liens ou le trafic de mauvaise qualité peuvent-ils nuire à la réputation de votre site ?
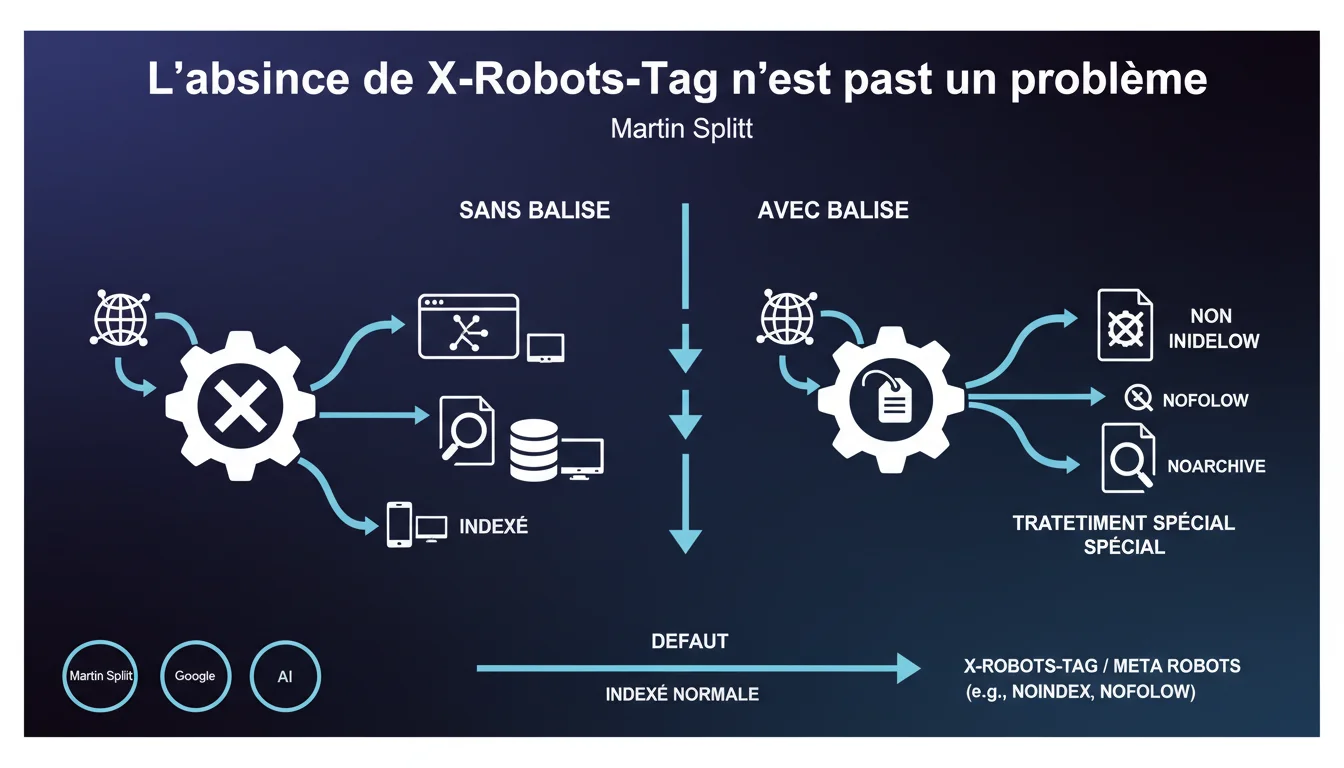
L'absence de X-Robots-Tag ou de balise meta robots n'est pas un problème en soi. Ces mécanismes ne servent qu'à donner des directives spécifiques aux moteurs de recherche. Sans elles, la page est simplement traitée normalement et peut être indexée par défaut.
Ce qu'il faut comprendre
Pourquoi cette clarification de Google sur les balises robots ?
Martin Splitt rappelle une évidence technique qui semble pourtant générer des interrogations récurrentes chez certains SEO. Les balises X-Robots-Tag (en-tête HTTP) et meta robots (balise HTML) sont des outils de contrôle, pas des prérequis.
Leur absence ne signifie pas que Google ne peut pas crawler ou indexer une page — bien au contraire. Sans directive explicite, le moteur applique son comportement par défaut : crawler, analyser et potentiellement indexer le contenu s'il le juge pertinent.
Dans quels cas ces balises deviennent-elles utiles ?
Ces mécanismes n'ont de sens que lorsque vous voulez modifier le comportement standard de Google. Typiquement : bloquer l'indexation (noindex), empêcher le suivi des liens (nofollow), interdire le cache (noarchive), ou limiter l'affichage des snippets (nosnippet).
Sans instruction contraire, Google considère que vous acceptez le traitement classique. C'est un principe de consentement implicite : silence vaut acceptation.
- L'absence de balises robots signifie que la page peut être indexée normalement
- Ces balises sont des outils de restriction, pas des conditions d'indexation
- Le X-Robots-Tag (HTTP header) et la meta robots (HTML) ont la même fonction, seul le vecteur diffère
- Les directives explicites permettent de gérer finement l'indexation de certaines sections : pages de filtres, PDF, pages de résultats de recherche interne, etc.
Comment Google gère-t-il l'absence totale de directives ?
En mode automatique. Le crawler analyse le contenu, évalue sa qualité, détecte les signaux de duplication ou de low-quality, et décide seul de l'opportunité d'indexer.
Cette autonomie peut poser problème sur des sites complexes où certaines pages — pagination profonde, facettes multiples, versions imprimables — finissent indexées alors qu'elles ne devraient pas l'être. L'absence de balises robots n'est pas un bug, mais un choix par défaut qui nécessite parfois des ajustements.
Avis d'un expert SEO
Cette déclaration est-elle cohérente avec les pratiques observées sur le terrain ?
Oui, totalement. Sur des milliers d'audits, on observe exactement ce comportement : les pages sans directive explicite sont crawlées et indexées si elles répondent aux critères qualité de Google. Pas de mystère ici.
Le problème surgit quand des sites laissent indexer par négligence des pages inutiles (login, cart, thank-you pages) qui polluent l'index et diluent le crawl budget. L'absence de balises robots devient alors un problème indirect — non pas technique, mais stratégique.
Quelles nuances faut-il apporter à cette déclaration ?
Splitt parle de "traiter une page différemment", mais cette formule masque une réalité plus complexe. Google peut très bien traiter différemment deux pages sans directive selon leur contenu, leur structure, leur duplication ou leur profondeur dans l'arborescence.
Le vrai enjeu n'est pas l'absence de balise, mais l'intentionnalité. Si vous laissez Google décider seul, vous perdez le contrôle granulaire. Sur un site e-commerce avec 50 000 références et des milliers de combinaisons de filtres, cette perte de contrôle peut être catastrophique.
Dans quels cas cette règle ne s'applique-t-elle pas vraiment ?
Quand le robots.txt bloque déjà l'accès. Si une URL est disallow dans le robots.txt, Google ne peut pas la crawler et ne verra jamais d'éventuelle balise meta robots dans le HTML. Le X-Robots-Tag en HTTP header peut encore être lu, mais c'est un cas limite.
Autre exception : les sites nécessitant une authentification. Sans accès au contenu, Google ne peut rien indexer, balises ou pas. L'absence de directive devient alors sans objet.
Impact pratique et recommandations
Que faut-il faire concrètement avec ces balises robots ?
Première étape : auditer les pages indexées via Search Console et identifier celles qui n'ont aucune valeur SEO (pages admin, filtres redondants, résultats de recherche interne, pages de tracking). Ensuite, décider pour chacune : noindex ou blocage robots.txt.
Deuxième mouvement : définir une stratégie d'indexation claire. Pas besoin de balises robots partout — seulement là où vous voulez dévier du comportement standard. Un site vitrine de 20 pages peut très bien s'en passer totalement. Un site e-commerce de 100 000 URLs doit impérativement gérer ses directives.
- Lister toutes les pages actuellement indexées via
site:votredomaine.comet Search Console - Identifier les pages sans valeur SEO : login, cart, checkout, thank-you, filtres redondants, paginations profondes
- Appliquer noindex sur les pages qui doivent être crawlées mais pas indexées (pour le maillage interne)
- Bloquer via robots.txt uniquement les pages qui ne doivent ni être crawlées ni indexées (économie de crawl budget)
- Vérifier dans les logs que Googlebot ne gaspille pas de ressources sur des sections non stratégiques
- Surveiller l'évolution de l'indexation dans Search Console après chaque modification
Quelles erreurs éviter dans la gestion des balises robots ?
Ne jamais combiner noindex + blocage robots.txt sur la même URL. Si Google ne peut pas crawler, il ne verra jamais le noindex et risque de garder l'URL en index avec un snippet tronqué. C'est une erreur classique qui génère des alertes dans Search Console.
Éviter aussi le noindex global par accident — un header X-Robots-Tag mal configuré au niveau serveur peut détruire l'indexation d'un site entier en quelques jours. Toujours tester en environnement de développement avant de pousser en production.
Comment vérifier que votre gestion des directives robots est optimale ?
Trois vérifications essentielles : inspecter les en-têtes HTTP avec un outil comme Screaming Frog ou les DevTools Chrome, analyser les logs serveur pour voir quelles sections Googlebot visite le plus, et monitorer l'évolution du nombre de pages indexées dans Search Console.
L'objectif est de maximiser le ratio pages indexées stratégiques / total pages crawlées. Si Google passe 40% de son temps sur des pages inutiles, vous avez un problème d'architecture, pas de balises.
❓ Questions frequentes
Est-ce qu'ajouter des balises meta robots sur toutes mes pages améliore mon SEO ?
Quelle est la différence entre X-Robots-Tag et meta robots ?
Si je retire toutes mes balises noindex, Google va-t-il tout indexer d'un coup ?
Peut-on combiner plusieurs directives dans une même balise robots ?
Pourquoi Google indexe-t-il encore des pages bloquées par robots.txt ?
🎥 De la même vidéo 19
Autres enseignements SEO extraits de cette même vidéo Google Search Central · publiée le 21/08/2024
🎥 Voir la vidéo complète sur YouTube →
💬 Commentaires (0)
Soyez le premier à commenter.