Declaration officielle
Autres déclarations de cette vidéo 19 ▾
- □ Google indexe-t-il vraiment toutes les langues de la même manière ?
- □ Les liens nofollow et balises noindex nuisent-ils à votre référencement ?
- □ Les erreurs 404 pénalisent-elles vraiment le classement de votre site ?
- □ Faut-il vraiment rediriger toutes les pages 404 pour améliorer son SEO ?
- □ La vitesse de votre CDN d'images pénalise-t-elle vraiment votre référencement dans Google Images ?
- □ Peut-on réinitialiser les données Search Console d'un site repris ?
- □ Les sous-domaines régionaux suffisent-ils à cibler un marché géographique ?
- □ Pourquoi vos rich results affichent-ils la mauvaise devise et comment y remédier ?
- □ La transcription vidéo est-elle considérée comme du contenu dupliqué par Google ?
- □ Pourquoi Google refuse-t-il les avis agrégés dans les données structurées produit ?
- □ Google crawle-t-il les variations d'URL sans liens internes ou backlinks ?
- □ Le ratio texte/code est-il vraiment un facteur de classement Google ?
- □ Les paramètres UTM avec medium=referral tuent-ils vraiment la valeur SEO d'un backlink ?
- □ Faut-il absolument répondre aux commentaires de blog pour le SEO ?
- □ Faut-il s'inquiéter quand robots.txt apparaît comme soft 404 dans Search Console ?
- □ Faut-il vraiment s'inquiéter de l'absence de balises X-Robots-Tag et meta robots ?
- □ Pourquoi les redirections Geo IP automatiques sabotent-elles votre SEO international ?
- □ Modifier ses balises title et meta description peut-il vraiment faire bouger son classement Google ?
- □ Les liens ou le trafic de mauvaise qualité peuvent-ils nuire à la réputation de votre site ?
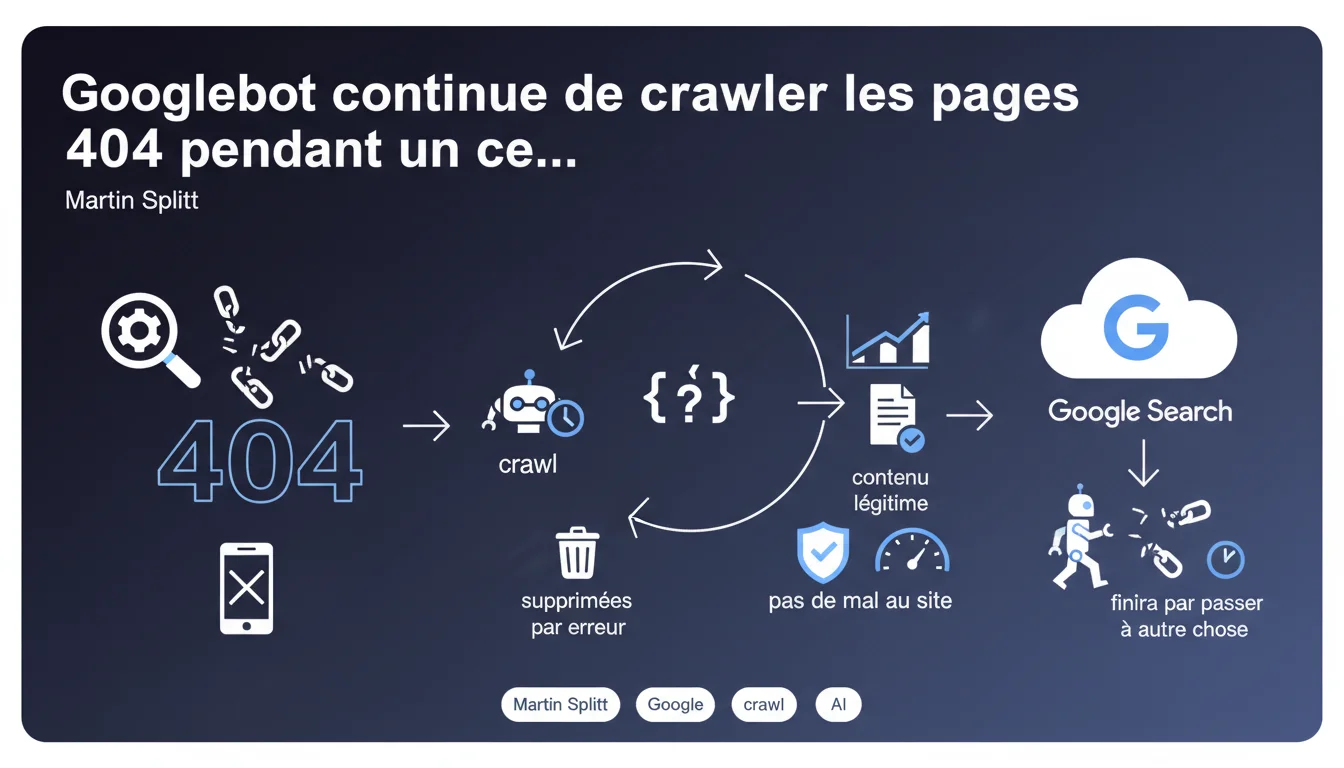
Googlebot continue de crawler des pages retournant 404 pendant un certain temps car elles peuvent avoir été supprimées par erreur ou revenir avec du contenu légitime. Ce comportement n'impacte pas négativement le site et le bot finit par abandonner ces URLs. Google considère cette persistance comme une fonctionnalité, pas un bug.
Ce qu'il faut comprendre
Pourquoi Googlebot ne lâche-t-il pas immédiatement une page 404 ?
Google adopte une approche prudente face aux erreurs 404. Au lieu de supprimer instantanément ces URLs de son index et d'arrêter le crawl, le bot continue de les visiter pendant une période indéterminée.
La logique est simple : distinguer une suppression accidentelle d'une suppression volontaire prend du temps. Un webmaster peut supprimer une page par erreur, un serveur peut tomber temporairement, ou le contenu peut revenir après maintenance. Googlebot préfère vérifier plusieurs fois avant de considérer la page comme définitivement morte.
Combien de temps dure cette période de grâce ?
Martin Splitt ne donne aucune indication chiffrée. On parle d'un "certain temps" sans précision sur la durée exacte — quelques jours, semaines, mois ?
Cette absence de timeline concrète est typique des communications Google : le flou permet d'ajuster l'algorithme sans avoir à communiquer sur chaque changement. Concrètement ? Attendez-vous à voir ces 404 dans vos logs pendant plusieurs semaines minimum, possiblement plus longtemps pour des pages qui avaient de l'autorité.
Ce crawl de pages 404 consomme-t-il du crawl budget inutilement ?
Google affirme que ce comportement ne nuit pas au site. Traduction : ça ne consomme pas de crawl budget critique qui empêcherait l'indexation de pages importantes.
Cela dit, techniquement, chaque requête vers une 404 est une requête qui aurait pu aller ailleurs. Pour un site avec des milliers de pages supprimées et un crawl budget serré, la nuance mérite attention.
- Googlebot continue le crawl des 404 par précaution, au cas où le contenu reviendrait
- Cette persistance concerne aussi bien les suppressions volontaires que les pages hackées temporairement supprimées
- Google ne précise pas la durée exacte de cette période de surveillance
- Le crawl de ces 404 est présenté comme neutre pour le référencement du site
- Googlebot finit par abandonner ces URLs, mais sans calendrier garanti
Avis d'un expert SEO
Cette déclaration est-elle cohérente avec les observations terrain ?
Oui, complètement. Tous les professionnels SEO ont constaté que Googlebot continue de frapper à la porte de pages supprimées pendant des semaines, voire des mois. Les logs de serveur le confirment quotidiennement.
Ce qui est plus discutable, c'est l'affirmation que ce crawl ne nuit pas au site. Si vous avez 10 000 pages 404 dans vos logs et un crawl budget limité, dire que ça n'a aucun impact est optimiste. Certes, Google priorise les pages actives, mais chaque hit sur une 404 est une ressource serveur consommée et une requête bot qui aurait pu aller ailleurs.
Que faire des contradictions entre cette déclaration et la pratique ?
Google présente ce comportement comme une fonctionnalité protectrice. Dans la réalité, pour un site qui nettoie massivement son arborescence ou qui sort d'un hack, voir Googlebot s'acharner sur des centaines de 404 n'a rien de rassurant.
Le conseil officiel est d'attendre que Google "passe à autre chose". Soyons honnêtes : ça peut prendre du temps. Beaucoup de temps. Et pendant ce temps, vos logs sont pollués et votre monitoring devient moins lisible. [A vérifier] : l'impact réel sur le crawl budget de sites moyens avec quelques centaines de 404 persistantes mériterait des données chiffrées de Google.
Dans quels cas cette tolérance pose-t-elle problème ?
De plus, pour des sites e-commerce avec rotation rapide de produits, les anciennes fiches produits en 404 continuent d'apparaître dans les logs alors que vous avez besoin de concentrer le crawl sur les nouvelles références. L'argument "ça ne nuit pas" devient alors plus théorique que pratique.
Impact pratique et recommandations
Faut-il faire quelque chose pour accélérer l'abandon de ces 404 par Google ?
La position officielle est d'attendre passivement. Mais plusieurs leviers permettent d'accélérer le processus si vous voulez vraiment que Google arrête de crawler ces pages mortes.
Premier réflexe : utilisez la Search Console pour supprimer manuellement les URLs que vous savez définitivement mortes. Oui, c'est manuel. Oui, c'est fastidieux. Mais pour les URLs à forte visibilité, ça marche.
Deuxième option : mettez en place des redirections 301 vers du contenu pertinent au lieu de laisser les 404 nues. Google suivra la redirection, comprendra que la page a migré, et cessera de crawler l'ancienne URL beaucoup plus vite. Si aucune page de remplacement n'existe, une redirection vers une page catégorie ou vers la home reste préférable à une 404 orpheline.
Quelles erreurs éviter quand on nettoie des 404 ?
Ne basculez jamais en masse des 404 vers des 200 avec du contenu générique type "page introuvable". Google détecte ces soft 404 et les traite encore plus mal qu'une vraie 404. Vous perdez sur tous les tableaux : crawl budget gaspillé et signal de qualité dégradé.
Évitez aussi de bloquer ces URLs dans le robots.txt en pensant économiser du crawl budget. Bloquer une page déjà en 404 empêche Google de vérifier son statut et peut paradoxalement ralentir le processus de désindexation. Le bot doit pouvoir constater la 404 pour l'enregistrer.
Comment surveiller l'évolution de ces 404 dans le temps ?
- Configurez un monitoring régulier de vos logs serveur pour identifier les 404 les plus crawlées par Googlebot
- Utilisez la Search Console pour suivre les erreurs 404 remontées et leur fréquence de crawl
- Identifiez les pages 404 qui reçoivent encore des backlinks externes — ce sont celles que Google crawlera le plus longtemps
- Mettez en place des redirections 301 pour toute 404 qui reçoit encore du trafic ou des liens
- Documentez les suppressions volontaires pour éviter de les confondre avec de vraies erreurs dans vos rapports
- Nettoyez votre maillage interne pour éliminer les liens pointant vers des 404 — Google suivra moins ces URLs si elles ne sont plus liées
❓ Questions frequentes
Combien de temps Googlebot continue-t-il à crawler une page 404 ?
Ce crawl de 404 consomme-t-il du crawl budget inutilement ?
Faut-il bloquer les 404 dans le robots.txt pour économiser du crawl budget ?
Les redirections 301 accélèrent-elles l'abandon des anciennes URLs par Google ?
Peut-on forcer Google à arrêter de crawler une 404 spécifique ?
🎥 De la même vidéo 19
Autres enseignements SEO extraits de cette même vidéo Google Search Central · publiée le 21/08/2024
🎥 Voir la vidéo complète sur YouTube →
💬 Commentaires (0)
Soyez le premier à commenter.