Declaration officielle
Autres déclarations de cette vidéo 19 ▾
- □ Google indexe-t-il vraiment toutes les langues de la même manière ?
- □ Les liens nofollow et balises noindex nuisent-ils à votre référencement ?
- □ Les erreurs 404 pénalisent-elles vraiment le classement de votre site ?
- □ Faut-il vraiment rediriger toutes les pages 404 pour améliorer son SEO ?
- □ La vitesse de votre CDN d'images pénalise-t-elle vraiment votre référencement dans Google Images ?
- □ Peut-on réinitialiser les données Search Console d'un site repris ?
- □ Les sous-domaines régionaux suffisent-ils à cibler un marché géographique ?
- □ Pourquoi vos rich results affichent-ils la mauvaise devise et comment y remédier ?
- □ La transcription vidéo est-elle considérée comme du contenu dupliqué par Google ?
- □ Pourquoi Google refuse-t-il les avis agrégés dans les données structurées produit ?
- □ Google crawle-t-il les variations d'URL sans liens internes ou backlinks ?
- □ Pourquoi Googlebot persiste-t-il à crawler des pages 404 après leur suppression ?
- □ Le ratio texte/code est-il vraiment un facteur de classement Google ?
- □ Les paramètres UTM avec medium=referral tuent-ils vraiment la valeur SEO d'un backlink ?
- □ Faut-il absolument répondre aux commentaires de blog pour le SEO ?
- □ Faut-il s'inquiéter quand robots.txt apparaît comme soft 404 dans Search Console ?
- □ Faut-il vraiment s'inquiéter de l'absence de balises X-Robots-Tag et meta robots ?
- □ Modifier ses balises title et meta description peut-il vraiment faire bouger son classement Google ?
- □ Les liens ou le trafic de mauvaise qualité peuvent-ils nuire à la réputation de votre site ?
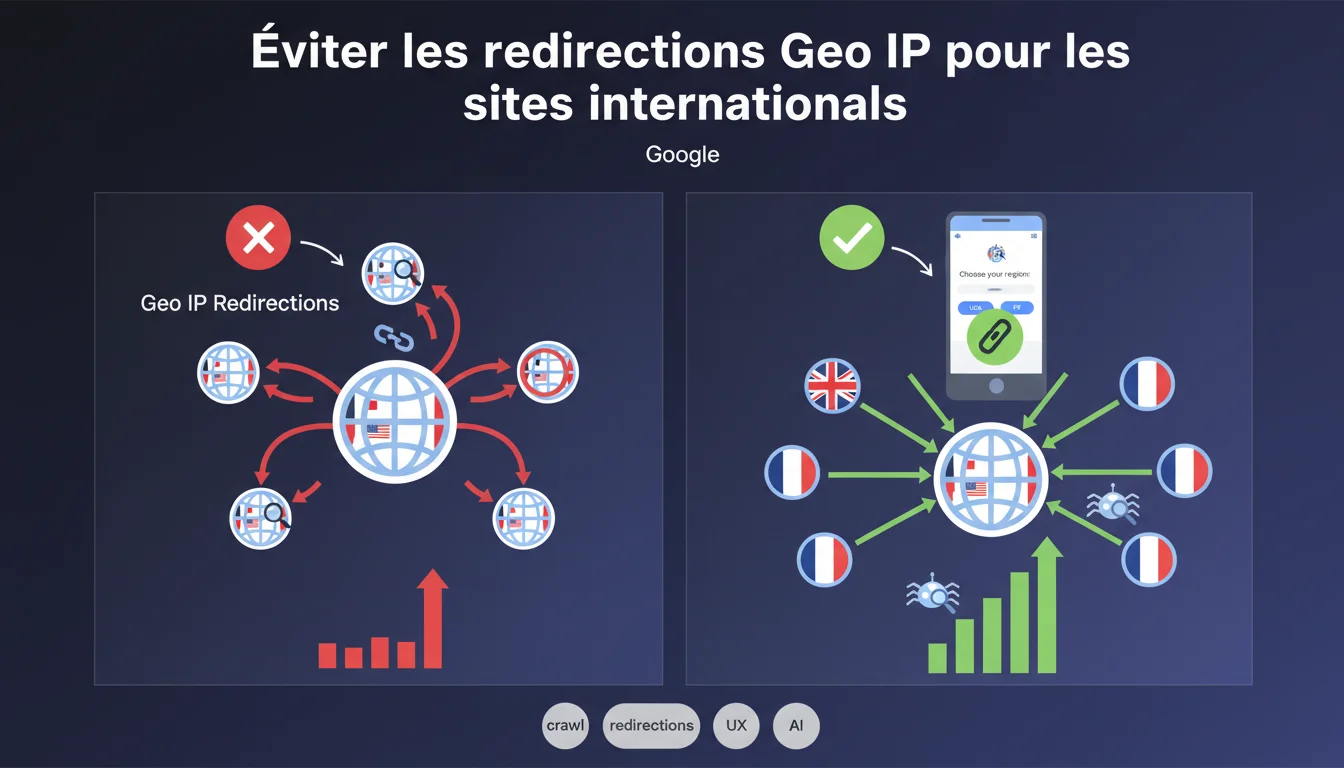
Google déconseille formellement les redirections Geo IP automatiques pour les sites multilingues ou multi-régionaux. Ces redirections bloquent les crawlers qui se retrouvent piégés sur une seule version du site, empêchant l'indexation correcte des autres. La solution recommandée : des bannières ou pop-ups permettant aux utilisateurs de choisir leur version.
Ce qu'il faut comprendre
Pourquoi Google s'oppose-t-il aux redirections Geo IP automatiques ?
Les redirections basées sur la géolocalisation IP posent un problème structurel d'indexation. Quand Googlebot crawle un site, il utilise généralement des IP américaines — et parfois d'autres datacenters répartis dans le monde. Si votre site redirige automatiquement vers /fr/ pour une IP française, Googlebot sera systématiquement renvoyé vers cette version et ne verra jamais les autres.
Résultat : vos versions /en/, /de/, /es/ ne seront pas crawlées, donc pas indexées. Vous perdez l'essentiel de votre visibilité internationale. Le moteur ne peut pas comprendre que ces versions existent si elles sont techniquement inaccessibles depuis son point de crawl.
Que se passe-t-il concrètement avec les crawlers ?
Les robots des moteurs de recherche n'envoient pas d'en-têtes Accept-Language utilisables pour déterminer une préférence linguistique fiable. Ils ne peuvent pas "choisir" leur version comme le ferait un humain cliquant sur un sélecteur de langue.
Si vous implémentez une redirection 301 ou 302 basée uniquement sur l'IP, vous créez une boucle de crawl fermée. Googlebot tape example.com, se fait rediriger vers example.com/us/, et ne peut plus accéder aux autres URLs. Même avec des hreflang parfaitement configurés, le moteur ne pourra jamais découvrir les pages alternatives puisqu'il ne les atteint jamais.
Quelle est la différence entre redirection forcée et suggestion utilisateur ?
Une redirection forcée (HTTP 301/302) ne laisse aucun choix : le serveur décide unilatéralement de la destination finale. Un crawler — et un utilisateur — n'a aucun moyen de contourner cette décision technique.
Une bannière ou pop-up de suggestion affiche la page demandée normalement, puis propose via JavaScript ou un élément HTML visible un lien vers la version locale détectée. L'utilisateur (ou le crawler) peut ignorer cette suggestion et continuer sur la version initiale. Googlebot voit le contenu réel de la page, indexe correctement, et comprend les signaux hreflang.
- Redirection automatique = blocage technique des crawlers sur une seule version
- Bannière de suggestion = page accessible + proposition optionnelle de changement
- Les hreflang ne compensent pas une redirection Geo IP — ils nécessitent que toutes les versions soient crawlables
- Cette règle s'applique à tous les moteurs, pas seulement Google
Avis d'un expert SEO
Cette recommandation est-elle vraiment appliquée sur le terrain ?
Soyons honnêtes : beaucoup de sites continuent d'utiliser des redirections Geo IP, notamment les grands e-commerce et plateformes SaaS. Certains s'en sortent mieux que d'autres — souvent parce qu'ils ont mis en place des exceptions pour les user-agents de crawlers. Mais cette approche introduit un risque de cloaking si mal exécutée.
Dans la pratique, les sites qui respectent strictement cette directive voient une amélioration mesurable de l'indexation internationale. Ceux qui persistent avec des redirections automatiques rencontrent régulièrement des problèmes d'indexation partielle, de cannibalisation entre versions régionales, ou de désindexation progressive de certaines langues. [A vérifier] : certains affirment que Googlebot adapte son comportement selon les datacenters — aucune donnée publique ne confirme cette nuance.
Quelles sont les zones grises de cette déclaration ?
Google reste flou sur les redirections conditionnelles basées sur User-Agent. Techniquement, vous pourriez rediriger les visiteurs humains selon leur IP tout en laissant passer les crawlers. Mais cette pratique frôle le cloaking — servir un contenu différent aux robots et aux utilisateurs.
Le risque ? Une pénalité manuelle ou algorithmique si Google considère que vous manipulez l'indexation. La frontière entre "optimisation UX" et "manipulation SEO" n'est jamais clairement définie dans ces cas-là. En 15 ans de pratique, j'ai vu des sites pénalisés pour moins que ça — et d'autres qui passent sous le radar pendant des années.
Dans quels cas cette règle pose-t-elle vraiment problème ?
Pour les sites avec des contraintes légales strictes (contenus géo-bloqués, licences territoriales, RGPD appliqué différemment selon les régions), éviter toute redirection automatique peut être compliqué. Certains secteurs — gambling, streaming, finance — n'ont pas vraiment le choix.
Dans ces situations, la solution la moins risquée reste de bloquer l'accès au niveau du contenu (message d'erreur ou page alternative) plutôt que de rediriger. Googlebot voit la page, comprend qu'elle existe, mais l'utilisateur final est informé de l'indisponibilité régionale. Ce n'est pas idéal UX, mais c'est crawlable.
Impact pratique et recommandations
Que faut-il faire concrètement pour un site international ?
Première étape : auditer toutes vos redirections serveur. Vérifiez dans vos fichiers .htaccess, nginx.conf, ou votre CDN (Cloudflare, Akamai) si des règles Geo IP renvoient automatiquement vers des versions régionales. Si oui, désactivez-les pour les crawlers — ou mieux, pour tout le monde.
Ensuite, implémentez une bannière de suggestion linguistique en haut de page, détectable via JavaScript côté client. Elle s'affiche après le chargement initial de la page, n'interfère pas avec le crawl, et donne le contrôle à l'utilisateur. Des frameworks comme Next.js ou Nuxt permettent de gérer ça proprement avec détection locale et cookies de préférence.
Comment vérifier que mes crawlers ne sont pas bloqués ?
Utilisez Google Search Console et vérifiez l'indexation de toutes vos versions régionales. Si certaines langues ou régions ont un taux d'indexation anormalement bas, c'est souvent un signe de redirection problématique.
Testez manuellement avec un VPN ou un proxy situé dans différentes régions, en vous faisant passer pour Googlebot (User-Agent : "Googlebot/2.1"). Si vous êtes redirigé alors que vous ne devriez pas l'être, vous avez identifié le problème. Des outils comme Screaming Frog en mode crawl par région peuvent aussi révéler ces redirections cachées.
Quelles erreurs éviter absolument ?
Ne créez jamais de redirections 301 permanentes basées sur l'IP pour des raisons de ciblage linguistique. Une 301 dit à Google "cette page a déménagé définitivement" — ce qui n'a aucun sens pour une version simplement différente de la même ressource.
Évitez aussi les redirections 302 en chaîne : IP détectée → redirect vers /fr/ → redirect vers /fr/accueil/ → etc. Chaque saut ralentit le crawl, dilue le PageRank, et augmente les chances d'erreur d'indexation. Gardez une architecture simple : une URL demandée = une réponse HTTP 200 avec le bon contenu.
- Supprimer toutes redirections Geo IP automatiques (301, 302, 307) basées uniquement sur l'origine de l'IP
- Implémenter une bannière JavaScript ou HTML visible permettant à l'utilisateur de choisir sa version
- Configurer correctement les balises hreflang sur toutes les versions linguistiques/régionales
- Tester l'accessibilité de toutes les versions avec Googlebot User-Agent depuis différentes IPs
- Vérifier dans Search Console que toutes les versions sont bien indexées
- Documenter clairement la logique de suggestion linguistique pour les équipes techniques
- Éviter toute différence de contenu servie selon User-Agent (risque de cloaking)
❓ Questions frequentes
Puis-je rediriger automatiquement les utilisateurs tout en laissant passer Googlebot ?
Les redirections JavaScript côté client posent-elles le même problème ?
Est-ce que les balises hreflang suffisent sans redirection ?
Comment gérer les utilisateurs qui préfèrent rester sur la version par défaut ?
Les CDN comme Cloudflare peuvent-ils gérer ça correctement ?
🎥 De la même vidéo 19
Autres enseignements SEO extraits de cette même vidéo Google Search Central · publiée le 21/08/2024
🎥 Voir la vidéo complète sur YouTube →
💬 Commentaires (0)
Soyez le premier à commenter.