Declaration officielle
Autres déclarations de cette vidéo 19 ▾
- □ Google indexe-t-il vraiment toutes les langues de la même manière ?
- □ Les liens nofollow et balises noindex nuisent-ils à votre référencement ?
- □ Les erreurs 404 pénalisent-elles vraiment le classement de votre site ?
- □ Faut-il vraiment rediriger toutes les pages 404 pour améliorer son SEO ?
- □ La vitesse de votre CDN d'images pénalise-t-elle vraiment votre référencement dans Google Images ?
- □ Peut-on réinitialiser les données Search Console d'un site repris ?
- □ Les sous-domaines régionaux suffisent-ils à cibler un marché géographique ?
- □ Pourquoi vos rich results affichent-ils la mauvaise devise et comment y remédier ?
- □ La transcription vidéo est-elle considérée comme du contenu dupliqué par Google ?
- □ Pourquoi Google refuse-t-il les avis agrégés dans les données structurées produit ?
- □ Pourquoi Googlebot persiste-t-il à crawler des pages 404 après leur suppression ?
- □ Le ratio texte/code est-il vraiment un facteur de classement Google ?
- □ Les paramètres UTM avec medium=referral tuent-ils vraiment la valeur SEO d'un backlink ?
- □ Faut-il absolument répondre aux commentaires de blog pour le SEO ?
- □ Faut-il s'inquiéter quand robots.txt apparaît comme soft 404 dans Search Console ?
- □ Faut-il vraiment s'inquiéter de l'absence de balises X-Robots-Tag et meta robots ?
- □ Pourquoi les redirections Geo IP automatiques sabotent-elles votre SEO international ?
- □ Modifier ses balises title et meta description peut-il vraiment faire bouger son classement Google ?
- □ Les liens ou le trafic de mauvaise qualité peuvent-ils nuire à la réputation de votre site ?
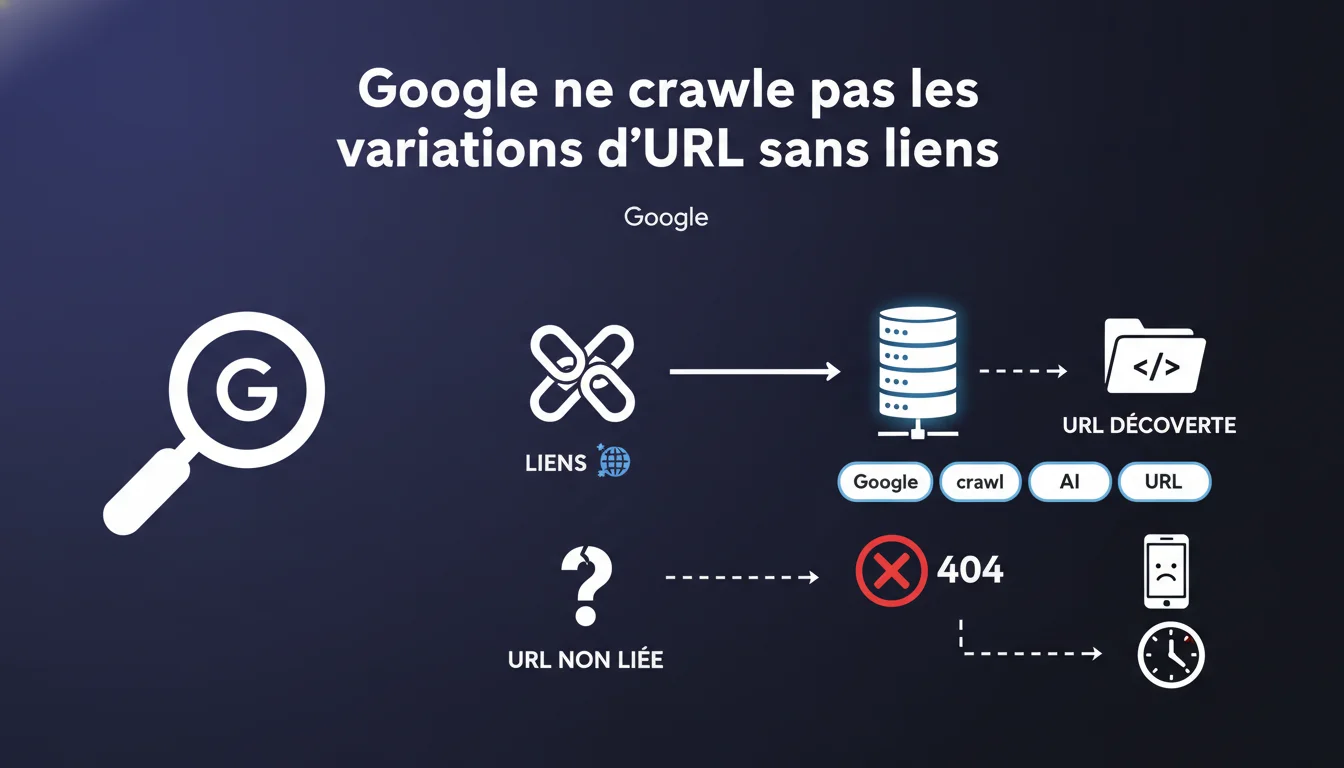
Google ne teste pas des variations d'URL au hasard : les systèmes de crawl s'appuient exclusivement sur les liens pour découvrir de nouvelles pages. Sans liens pointant vers vos sous-répertoires ou pages, Google ne les trouvera probablement jamais — et si le bot tombe dessus par hasard et obtient un 404, c'est parfaitement normal.
Ce qu'il faut comprendre
Google découvre-t-il les URL par déduction logique ?
Non. Google ne crawle pas par intuition. L'idée qu'il suffirait de créer une structure /categorie/sous-categorie/ pour que Googlebot la scanne automatiquement est fausse. Les robots ne testent pas des chemins logiques « au cas où ».
Le moteur s'appuie sur un principe simple : les liens sont la colonne vertébrale du crawl. Pas de lien interne ou externe pointant vers une URL ? Alors cette URL n'existe pas aux yeux de Google, même si elle renvoie un 200 parfait.
Pourquoi cette déclaration compte pour le maillage interne ?
Parce qu'elle remet les pendules à l'heure sur un malentendu fréquent. Beaucoup de sites créent des pages orphelines — accessibles via l'URL directe, mais jamais liées depuis le reste du site. Ces pages restent invisibles pour Google.
La logique est binaire : si aucun chemin de liens ne mène à une page, elle ne sera jamais crawlée ni indexée. Et c'est encore plus vrai pour les sous-répertoires entiers. Créer /blog/archives/2018/ sans aucun lien interne ou externe revient à créer du contenu fantôme.
Les erreurs 404 sur des URL jamais liées sont-elles un problème ?
Non, et c'est explicite dans la déclaration : un 404 sur une URL non liée est totalement normal. Google ne pénalise pas les erreurs 404 en soi — il pénalise les mauvaises expériences utilisateur, notamment quand des liens internes pointent vers du vide.
Si Google tombe par hasard sur une variante d'URL (par exemple via un test automatique marginal ou une fuite dans des logs tiers), et qu'elle renvoie un 404, aucun impact négatif. Le vrai risque, c'est d'avoir des pages importantes non liées qui ne sont jamais découvertes.
- Google ne crawle que ce qu'il trouve via des liens — internes ou externes.
- Les pages orphelines (sans aucun lien pointant vers elles) restent invisibles au crawl.
- Les erreurs 404 sur des URL non liées ne sont pas un problème SEO en soi.
- Le maillage interne n'est pas un bonus facultatif : c'est le carburant du crawl.
Avis d'un expert SEO
Cette déclaration contredit-elle des observations terrain ?
Non, elle confirme ce qu'on observe depuis toujours. Les pages orphelines ne sont jamais indexées, sauf exception rarissime — par exemple si l'URL fuite dans un log public ou un sitemap tiers. Mais compter là-dessus relève de la loterie.
Ce qui est intéressant, c'est que Google le dit clairement : il n'y a pas de crawl exploratoire systématique. Certains SEO espèrent qu'un moteur aussi puissant « devine » les structures logiques d'un site. C'est faux. Google suit les fils, il ne les invente pas.
Quelles nuances faut-il apporter à cette règle ?
Il y a quelques cas limites. Les sitemaps XML peuvent forcer la découverte d'URL non liées — c'est leur rôle. Mais soumettre une URL via sitemap sans aucun lien interne reste une stratégie fragile : Google peut crawler l'URL, mais rien ne garantit qu'il l'indexe correctement si elle manque de signaux de pertinence (dont le maillage interne fait partie).
Autre nuance : les logs serveur révèlent parfois des crawls « fantômes » sur des URL jamais liées. Cela arrive, mais c'est marginal et souvent lié à des fuites externes (partages sur des forums, historiques d'outils tiers, etc.). Ne pas construire une stratégie là-dessus.
Dans quels cas cette logique pose-t-elle problème ?
Sur les gros sites — e-commerce, médias, annuaires — où certaines pages sont volontairement exclues du maillage pour des raisons UX ou techniques. Exemple classique : les pages de filtres ou de tri dynamiques. Si vous ne voulez pas qu'elles soient indexées, ne pas les lier suffit… en théorie.
En pratique, ces URL se retrouvent souvent crawlées via des liens JavaScript mal contrôlés, des paramètres d'URL exposés dans des menus, ou des liens générés par des widgets tiers. Résultat : des milliers d'URL inutiles dans l'index. [A vérifier] : la déclaration de Google ne précise pas comment les liens JavaScript (notamment les liens générés côté client) sont traités dans cette logique de découverte.
Impact pratique et recommandations
Comment s'assurer que Google crawle toutes les pages importantes ?
Auditez vos pages orphelines — c'est-à-dire les URL indexables qui n'ont aucun lien interne pointant vers elles. Des outils comme Screaming Frog ou Oncrawl permettent de croiser le crawl du site avec les URL indexées dans Google Search Console. Toute URL indexée sans lien interne est un signal d'alerte.
Ensuite, renforcez votre maillage interne de manière stratégique. Chaque page importante doit être accessible depuis au moins 2-3 points d'entrée différents sur le site. Plus une page est profonde (nombre de clics depuis l'accueil), moins elle sera crawlée souvent. L'idéal : aucune page stratégique à plus de 3 clics de la home.
Quelles erreurs éviter dans la gestion des URL ?
Ne comptez pas sur le sitemap XML comme béquille unique. Oui, il aide Google à découvrir des URL, mais un sitemap ne remplace pas le maillage interne. Une page dans le sitemap mais orpheline restera faiblement crawlée et mal comprise par Google.
Autre piège classique : bloquer des pages importantes dans le robots.txt tout en espérant qu'elles soient indexées via des backlinks. Google peut indexer l'URL (sur la base du lien), mais sans crawler le contenu — résultat : une fiche index vide et inutile. Si une page mérite d'être indexée, elle doit être crawlable et liée.
Que faire si des URL inutiles sont crawlées malgré tout ?
Si des variantes d'URL indésirables (filtres, paramètres de tri, sessions, etc.) apparaissent dans vos logs de crawl ou dans Google Search Console, identifiez la source des liens. Souvent, c'est un lien JavaScript, un menu dynamique mal configuré, ou un paramètre exposé dans un formulaire.
Solution : désindexez proprement ces URL via noindex ou canonical, et supprimez les liens internes qui les génèrent. Si elles sont utiles pour l'UX mais pas pour le SEO, utilisez du JavaScript côté client pour les rendre invisibles au crawl (avec précaution — Google exécute JS, mais pas toujours parfaitement).
- Identifier et corriger toutes les pages orphelines stratégiques (sans lien interne).
- Vérifier que chaque page importante est accessible en 3 clics maximum depuis l'accueil.
- Auditer les liens JavaScript pour s'assurer qu'ils sont bien vus par Googlebot.
- Croiser les données de crawl interne (Screaming Frog) avec les URL indexées (GSC).
- Nettoyer les variantes d'URL inutiles via noindex, canonical ou suppression des liens générateurs.
- Ne pas compter uniquement sur le sitemap XML — le maillage interne reste la clé.
❓ Questions frequentes
Google peut-il découvrir une page uniquement via le sitemap XML, sans aucun lien ?
Si une page importante n'a aucun lien interne, sera-t-elle indexée via des backlinks externes ?
Les erreurs 404 sur des URL jamais liées nuisent-elles au SEO du site ?
Comment identifier les pages orphelines sur mon site ?
Googlebot suit-il les liens JavaScript pour découvrir de nouvelles URL ?
🎥 De la même vidéo 19
Autres enseignements SEO extraits de cette même vidéo Google Search Central · publiée le 21/08/2024
🎥 Voir la vidéo complète sur YouTube →
💬 Commentaires (0)
Soyez le premier à commenter.