Official statement
Other statements from this video 19 ▾
- □ Google indexe-t-il vraiment toutes les langues de la même manière ?
- □ Les liens nofollow et balises noindex nuisent-ils à votre référencement ?
- □ Les erreurs 404 pénalisent-elles vraiment le classement de votre site ?
- □ Faut-il vraiment rediriger toutes les pages 404 pour améliorer son SEO ?
- □ La vitesse de votre CDN d'images pénalise-t-elle vraiment votre référencement dans Google Images ?
- □ Peut-on réinitialiser les données Search Console d'un site repris ?
- □ Les sous-domaines régionaux suffisent-ils à cibler un marché géographique ?
- □ Pourquoi vos rich results affichent-ils la mauvaise devise et comment y remédier ?
- □ La transcription vidéo est-elle considérée comme du contenu dupliqué par Google ?
- □ Pourquoi Google refuse-t-il les avis agrégés dans les données structurées produit ?
- □ Pourquoi Googlebot persiste-t-il à crawler des pages 404 après leur suppression ?
- □ Le ratio texte/code est-il vraiment un facteur de classement Google ?
- □ Les paramètres UTM avec medium=referral tuent-ils vraiment la valeur SEO d'un backlink ?
- □ Faut-il absolument répondre aux commentaires de blog pour le SEO ?
- □ Faut-il s'inquiéter quand robots.txt apparaît comme soft 404 dans Search Console ?
- □ Faut-il vraiment s'inquiéter de l'absence de balises X-Robots-Tag et meta robots ?
- □ Pourquoi les redirections Geo IP automatiques sabotent-elles votre SEO international ?
- □ Modifier ses balises title et meta description peut-il vraiment faire bouger son classement Google ?
- □ Les liens ou le trafic de mauvaise qualité peuvent-ils nuire à la réputation de votre site ?
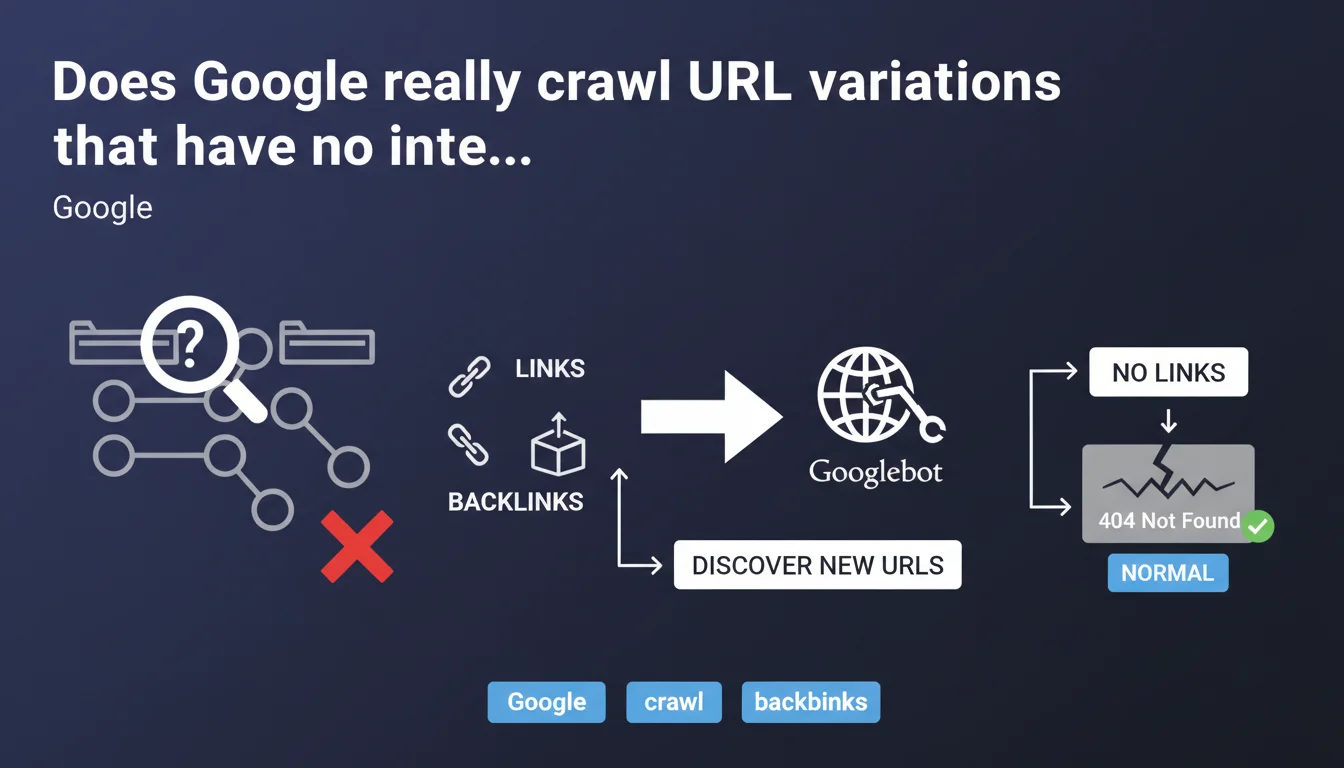
Google doesn't randomly test URL variations: crawl systems rely exclusively on links to discover new pages. Without links pointing to your subdirectories or pages, Google will probably never find them — and if the bot stumbles upon them by chance and gets a 404, that's perfectly normal.
What you need to understand
Does Google discover URLs through logical deduction?
No. Google does not crawl through intuition. The idea that you just need to create a /category/subcategory/ structure for Googlebot to automatically scan it is false. Robots don't test logical paths "just in case".
The engine relies on a simple principle: links are the backbone of crawling. No internal or external link pointing to a URL? Then that URL doesn't exist in Google's eyes, even if it returns a perfect 200 response.
Why does this statement matter for internal linking?
Because it sets the record straight on a frequent misconception. Many sites create orphan pages — accessible via direct URL, but never linked from anywhere else on the site. These pages remain invisible to Google.
The logic is binary: if no link path leads to a page, it will never be crawled or indexed. And that's even more true for entire subdirectories. Creating /blog/archives/2018/ without any internal or external links is like creating phantom content.
Are 404 errors on unlinked URLs a problem?
No, and this is explicit in the statement: a 404 on an unlinked URL is completely normal. Google doesn't penalize 404 errors in themselves — it penalizes poor user experiences, particularly when internal links point to dead ends.
If Google happens to stumble upon a URL variant (for example through marginal automated testing or a leak in third-party logs), and it returns a 404, there's no negative impact. The real risk is having important pages that are unlinked and never discovered.
- Google only crawls what it finds through links — internal or external.
- Orphan pages (with no links pointing to them) remain invisible to crawling.
- 404 errors on unlinked URLs are not an SEO problem in themselves.
- Internal linking is not an optional bonus: it's the fuel of crawling.
SEO Expert opinion
Does this statement contradict real-world observations?
No, it confirms what we've observed all along. Orphan pages are never indexed, except in extremely rare cases — for example if the URL leaks in a public log or third-party sitemap. But relying on that is gambling.
What's interesting is that Google says it plainly: there's no systematic exploratory crawling. Some SEOs hope that such a powerful engine would somehow "guess" the logical structures of a site. That's wrong. Google follows the threads, it doesn't invent them.
What nuances should be added to this rule?
There are a few edge cases. XML sitemaps can force the discovery of unlinked URLs — that's their role. But submitting a URL via sitemap without any internal links remains a fragile strategy: Google may crawl the URL, but nothing guarantees it will index it correctly if it lacks relevance signals (of which internal linking is part).
Another nuance: server logs sometimes reveal "ghost" crawls on unlinked URLs. This happens, but it's marginal and often tied to external leaks (forum shares, third-party tool histories, etc.). Don't build a strategy around that.
In what cases does this logic create problems?
On large sites — e-commerce, media, directories — where certain pages are intentionally excluded from internal linking for UX or technical reasons. Classic example: filter or sort pages generated dynamically. If you don't want them indexed, not linking to them is enough… in theory.
In practice, these URLs often end up being crawled through poorly controlled JavaScript links, URL parameters exposed in menus, or links generated by third-party widgets. Result: thousands of unnecessary URLs in the index. [To verify]: Google's statement doesn't specify how JavaScript links (particularly client-side generated links) are handled in this discovery logic.
Practical impact and recommendations
How do you ensure Google crawls all important pages?
Audit your orphan pages — that is, indexable URLs that have no internal links pointing to them. Tools like Screaming Frog or Oncrawl allow you to cross-reference your site's crawl with the URLs indexed in Google Search Console. Any indexed URL without internal links is a red flag.
Then, strengthen your internal linking strategically. Every important page should be accessible from at least 2-3 different entry points on the site. The deeper a page is (number of clicks from the homepage), the less often it will be crawled. Ideally: no strategic page more than 3 clicks from the home page.
What errors should you avoid in URL management?
Don't rely on XML sitemap as your only crutch. Yes, it helps Google discover URLs, but a sitemap doesn't replace internal linking. A page in the sitemap but orphaned will remain poorly crawled and misunderstood by Google.
Another common trap: blocking important pages in robots.txt while hoping they'll be indexed via backlinks. Google may index the URL (based on the link), but without crawling the content — result: an empty and useless index entry. If a page deserves to be indexed, it must be crawlable and linked.
What if unwanted URLs are still being crawled?
If undesirable URL variants (filters, sort parameters, sessions, etc.) appear in your crawl logs or Google Search Console, identify the source of the links. Often, it's a JavaScript link, a poorly configured dynamic menu, or a parameter exposed in a form.
Solution: properly de-index these URLs via noindex or canonical, and remove the internal links generating them. If they're useful for UX but not for SEO, use client-side JavaScript to make them invisible to crawling (with caution — Google executes JS, but not always perfectly).
- Identify and fix all strategic orphan pages (without internal links).
- Verify that each important page is accessible in 3 clicks maximum from the homepage.
- Audit JavaScript links to ensure they're properly seen by Googlebot.
- Cross-reference internal crawl data (Screaming Frog) with indexed URLs (GSC).
- Clean up unnecessary URL variants via noindex, canonical, or removal of generating links.
- Don't rely solely on XML sitemap — internal linking remains the key.
❓ Frequently Asked Questions
Google peut-il découvrir une page uniquement via le sitemap XML, sans aucun lien ?
Si une page importante n'a aucun lien interne, sera-t-elle indexée via des backlinks externes ?
Les erreurs 404 sur des URL jamais liées nuisent-elles au SEO du site ?
Comment identifier les pages orphelines sur mon site ?
Googlebot suit-il les liens JavaScript pour découvrir de nouvelles URL ?
🎥 From the same video 19
Other SEO insights extracted from this same Google Search Central video · published on 21/08/2024
🎥 Watch the full video on YouTube →
💬 Comments (0)
Be the first to comment.