Official statement
Other statements from this video 21 ▾
- □ Faut-il créer une nouvelle URL ou mettre à jour la même page pour du contenu quotidien ?
- □ Faut-il arrêter d'utiliser l'outil de soumission manuelle dans Search Console ?
- □ Les balises H2 dans le footer posent-elles un problème pour le référencement ?
- □ Les balises <header> et <footer> HTML5 améliorent-elles vraiment le SEO ?
- □ Faut-il vraiment se fier au validateur schema.org pour optimiser ses données structurées ?
- □ La vitesse de page améliore-t-elle vraiment le classement aussi vite qu'on le croit ?
- □ Google crawle-t-il tous les sitemaps au même rythme ?
- □ Google continue-t-il vraiment de crawler un sitemap supprimé de Search Console ?
- □ Pourquoi Google n'indexe-t-il pas une page crawlée régulièrement si elle ne présente aucun problème technique ?
- □ Peut-on utiliser des canonical bidirectionnels entre deux versions d'un site sans risque ?
- □ Pourquoi un seul x-default suffit-il pour toute votre configuration hreflang multi-domaines ?
- □ Faut-il vraiment éviter le structured data produit sur les pages catégories ?
- □ Faut-il vraiment choisir une langue principale pour chaque page si vous visez plusieurs marchés ?
- □ Pourquoi Google ignore-t-il complètement votre version desktop en mobile-first indexing ?
- □ Le contenu 'commodity' peut-il vraiment survivre dans les résultats Google ?
- □ Faut-il isoler ses FAQ dans des pages séparées pour mieux ranker ?
- □ Pourquoi Google réduit-il drastiquement l'affichage des FAQ dans les résultats de recherche ?
- □ Pourquoi Google n'indexe-t-il qu'une infime fraction de vos URLs ?
- □ Peut-on héberger son sitemap XML sur un domaine différent de son site principal ?
- □ Les Core Web Vitals : pourquoi le passage de « Bad » à « Medium » change tout pour votre ranking ?
- □ La vitesse serveur impacte-t-elle vraiment le crawl budget des gros sites ?
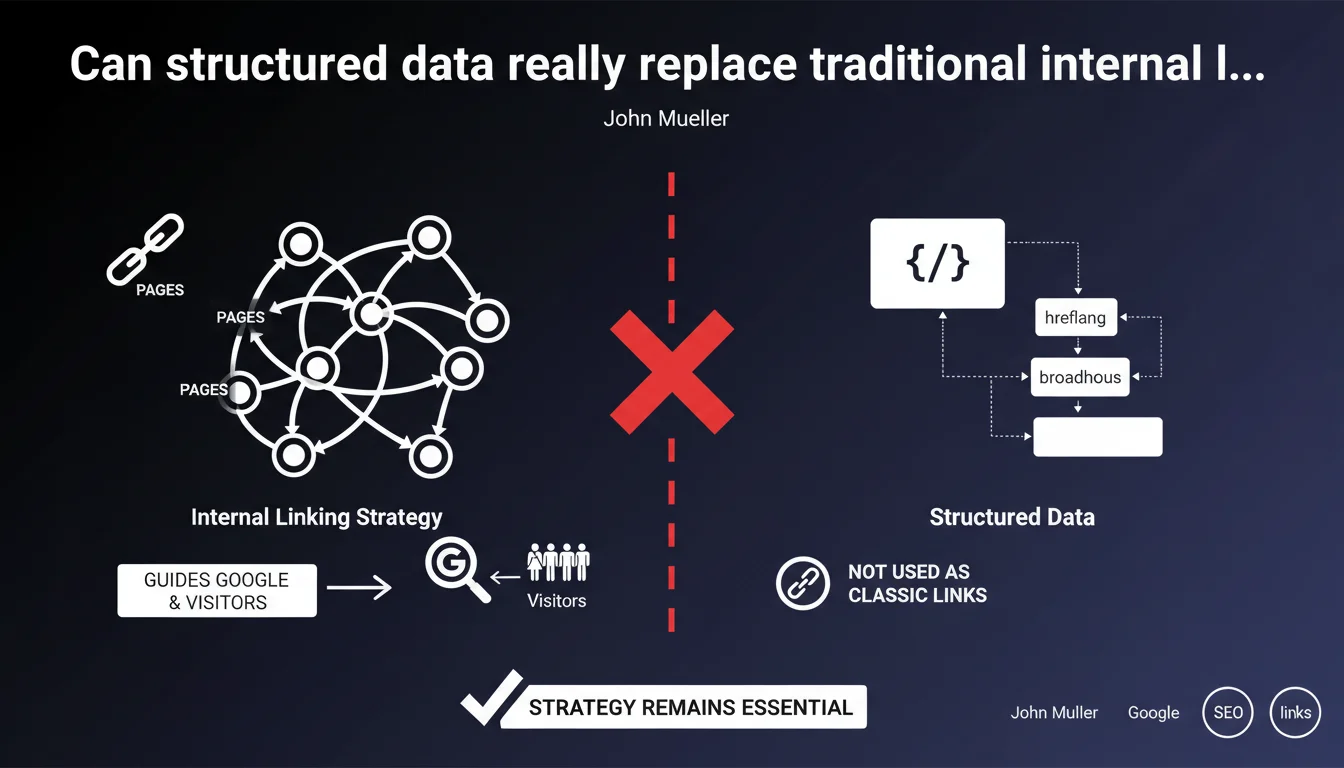
Google confirms that URLs present in structured data (hreflang, breadcrumb, etc.) are NOT treated as classic internal links. HTML internal linking remains one of the most powerful SEO levers for guiding crawl and signaling your strategic pages. Structured data complements this approach, but never substitutes for it.
What you need to understand
Why does Google make this distinction between structured data and HTML links?
Structured data primarily serves to contextualize content for search engines — not to pass PageRank or organize site architecture. When you declare a URL in a breadcrumb Schema.org or hreflang annotation, you're giving Google semantic information, not a navigation signal.
Crawling, on the other hand, is based on traditional HTML links (anchor tags with href attributes). It's through these links that Googlebot discovers, hierarchizes, and evaluates page depth. If a page is only accessible through a URL mentioned in structured data, it risks being completely missed by the bot.
What does "guiding Google and visitors" concretely mean?
A well-planned internal linking strategy pilots two simultaneous flows: Google's crawl budget and the user journey. Each internal link acts as a vote of confidence: the more internal links a page receives from strategic pages, the more Google understands its relative importance within your ecosystem.
Structured data, on the other hand, provides complementary context — they enrich rich snippets, clarify a page's position in your information architecture (breadcrumb), or signal language versions (hreflang). But they trigger no crawl on their own.
What risks if you neglect internal linking in favor of structured data?
A site that bets everything on structured annotations without caring for HTML links shoots itself in the foot. Orphaned pages — accessible only through internal search or structured data — receive neither link juice nor regular crawl.
Result: unpredictable indexation, mediocre rankings, and complete misunderstanding of your editorial hierarchy by Google. Structured data won't fill this gap — they just dress up a poorly built skeleton.
- HTML links drive crawl, internal PageRank distribution, and page discovery
- Structured data enrich semantic understanding and SERP display, but don't create crawl paths
- A page without incoming HTML links risks remaining invisible or poorly indexed, even if referenced in a breadcrumb Schema.org
- Internal linking remains one of the few directly controllable on-site levers with high SEO impact
SEO Expert opinion
Is this statement consistent with real-world observations?
Absolutely. Crawl tests have shown for years that Googlebot follows anchor tags with href attributes as a priority. URLs mentioned in structured data (breadcrumb, hreflang, sameAs) don't trigger systematic crawling — they serve as metadata, not entry points.
Sites that rely solely on breadcrumb Schema.org to "link" their pages often encounter indexation issues or pages that never rank in the SERPs. Conversely, dense and logical HTML linking quickly improves the visibility of strategic pages.
Should you neglect structured data then?
No — that's a false dilemma. Structured data and internal linking play in two different but complementary leagues. Schema.org breadcrumbs improve SERP display (clickable breadcrumb trails), hreflang annotations prevent cannibalization between language versions, and Article or Product markup boost click-through rates.
The trap is believing that polishing your structured data compensates for sloppy internal linking. It doesn't work that way. Both are necessary, but HTML linking remains the load-bearing foundation. Structured data dress up that foundation, they don't replace it.
In what cases could this rule pose problems?
Some sites — particularly large e-commerce with dynamic page generation — use JavaScript links or SPAs (Single Page Applications) where links aren't always classic anchor tags. In these cases, Google's JavaScript rendering can capture links, but with lower reliability and delay.
If your internal links depend on heavy JS frameworks, you're already in a gray area. Adding structured data won't change the fundamental problem: Googlebot still prefers static HTML links that are crawlable without JavaScript execution.
Practical impact and recommendations
What should you concretely do to optimize your internal linking?
First step: map your strategic pages. Identify high-value content (pillar pages, main categories, bestselling product sheets) and verify they receive links from your homepage, main menu, and other high PageRank pages.
Next, audit click depth: an important page should never be more than 3 clicks away from your homepage. Use Screaming Frog or Oncrawl to spot orphaned or too-deep pages, then create linking bridges from better-connected pages.
For structured data, implement breadcrumb Schema.org to improve SERP display — but don't count on them for crawling. Ensure every page has at least one classic HTML incoming link, ideally several from relevant editorial contexts.
What mistakes to absolutely avoid?
Don't confuse semantic annotations and link architecture. A page mentioned in JSON-LD breadcrumbs but without any anchor tag link remains an orphaned page for Google. This is the most common mistake on sites migrating to JavaScript-dependent architectures.
Also avoid overloading your pages with unnecessary internal links. Good linking is about contextual quality, not blind quantity. One link from a relevant editorial paragraph beats 50 automated footer links to every site category.
- Audit click depth for all strategic pages (goal: ≤3 clicks from homepage)
- Spot and remove orphaned pages using Screaming Frog or Search Console crawl data
- Create contextual HTML links from pillar pages to important subpages
- Implement breadcrumb Schema.org to enhance SERP display (complement, not replacement)
- Verify that each page receives at least 2-3 internal links from well-crawled pages
- Avoid links generated only in JavaScript without HTML fallback
- Use descriptive and varied anchor text for internal links (avoid repetitive "click here")
How do you verify your site follows these principles?
Run a full crawl with a tool like Screaming Frog in Spider mode. Analyze the link graph to identify isolated clusters and pages with low "InRank" (internal PageRank equivalent). Cross-reference with Search Console data to see whether poorly linked pages are also those struggling to be indexed or ranked.
Also verify that your structured data (breadcrumb, hreflang) are properly implemented and validated through Google's testing tool — but remember they come after HTML linking in SEO priority order.
❓ Frequently Asked Questions
Les URLs dans les breadcrumbs Schema.org aident-elles au crawl ?
Les annotations hreflang sont-elles suivies comme des liens internes ?
Combien de liens internes minimum par page ?
Les liens JavaScript sont-ils équivalents aux liens HTML pour le SEO ?
Faut-il privilégier le maillage interne ou les structured data ?
🎥 From the same video 21
Other SEO insights extracted from this same Google Search Central video · published on 05/03/2022
🎥 Watch the full video on YouTube →
💬 Comments (0)
Be the first to comment.