Declaration officielle
Autres déclarations de cette vidéo 21 ▾
- □ Faut-il créer une nouvelle URL ou mettre à jour la même page pour du contenu quotidien ?
- □ Faut-il arrêter d'utiliser l'outil de soumission manuelle dans Search Console ?
- □ Les balises H2 dans le footer posent-elles un problème pour le référencement ?
- □ Les balises <header> et <footer> HTML5 améliorent-elles vraiment le SEO ?
- □ Faut-il vraiment se fier au validateur schema.org pour optimiser ses données structurées ?
- □ La vitesse de page améliore-t-elle vraiment le classement aussi vite qu'on le croit ?
- □ Google crawle-t-il tous les sitemaps au même rythme ?
- □ Google continue-t-il vraiment de crawler un sitemap supprimé de Search Console ?
- □ Pourquoi Google n'indexe-t-il pas une page crawlée régulièrement si elle ne présente aucun problème technique ?
- □ Peut-on utiliser des canonical bidirectionnels entre deux versions d'un site sans risque ?
- □ Pourquoi un seul x-default suffit-il pour toute votre configuration hreflang multi-domaines ?
- □ Faut-il vraiment éviter le structured data produit sur les pages catégories ?
- □ Faut-il vraiment choisir une langue principale pour chaque page si vous visez plusieurs marchés ?
- □ Pourquoi Google ignore-t-il complètement votre version desktop en mobile-first indexing ?
- □ Le contenu 'commodity' peut-il vraiment survivre dans les résultats Google ?
- □ Faut-il isoler ses FAQ dans des pages séparées pour mieux ranker ?
- □ Pourquoi Google réduit-il drastiquement l'affichage des FAQ dans les résultats de recherche ?
- □ Pourquoi Google n'indexe-t-il qu'une infime fraction de vos URLs ?
- □ Peut-on héberger son sitemap XML sur un domaine différent de son site principal ?
- □ Les Core Web Vitals : pourquoi le passage de « Bad » à « Medium » change tout pour votre ranking ?
- □ La vitesse serveur impacte-t-elle vraiment le crawl budget des gros sites ?
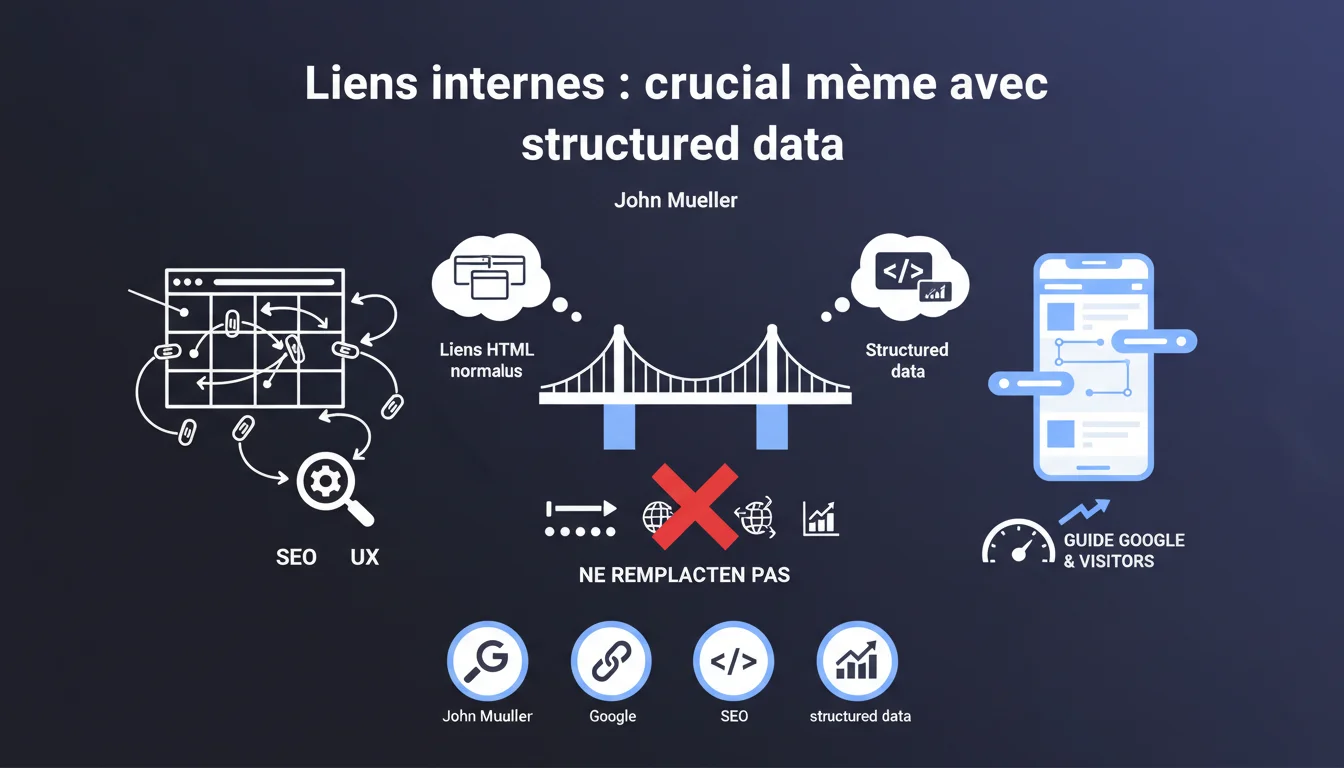
Google confirme que les URLs présentes dans les structured data (hreflang, breadcrumb, etc.) ne sont PAS traitées comme des liens internes classiques. Le maillage interne en HTML reste l'un des leviers SEO les plus puissants pour guider le crawl et signaler vos pages stratégiques. Les données structurées complètent cette approche, mais ne s'y substituent jamais.
Ce qu'il faut comprendre
Pourquoi Google fait-il cette distinction entre structured data et liens HTML ?
Les structured data servent avant tout à contextualiser le contenu pour les moteurs de recherche — pas à transmettre du PageRank ou à organiser l'architecture du site. Quand vous déclarez une URL dans un breadcrumb Schema.org ou une annotation hreflang, vous donnez à Google une information sémantique, pas un signal de navigation.
Le crawl, lui, se base sur les liens HTML traditionnels (balises <a href>). C'est par ces liens que Googlebot découvre, hiérarchise et évalue la profondeur des pages. Si une page n'est accessible que via une URL mentionnée dans des structured data, elle risque de passer complètement sous le radar du bot.
Que signifie concrètement "guider Google et les visiteurs" ?
Un maillage interne bien pensé pilote deux flux simultanés : le crawl budget de Google et le parcours utilisateur. Chaque lien interne agit comme un vote de confiance : plus une page reçoit de liens internes depuis des pages stratégiques, plus Google comprend son importance relative dans votre écosystème.
Les structured data, elles, fournissent du contexte complémentaire — elles enrichissent les rich snippets, précisent la localisation d'une page dans l'arborescence (breadcrumb), ou signalent des versions linguistiques (hreflang). Mais elles ne déclenchent aucun crawl à elles seules.
Quels risques si on néglige le maillage interne au profit des structured data ?
Un site qui mise tout sur les annotations structurées sans soigner ses liens HTML se tire une balle dans le pied. Les pages orphelines — accessibles uniquement via recherche interne ou structured data — ne reçoivent ni jus de lien ni crawl régulier.
Résultat : indexation capricieuse, positionnement médiocre, et incompréhension totale de votre hiérarchie éditoriale par Google. Les structured data ne comblent pas ce déficit — elles ne font qu'habiller un squelette mal fichu.
- Les liens HTML pilotent le crawl, la distribution du PageRank interne et la découverte des pages
- Les structured data enrichissent la compréhension sémantique et l'affichage dans les SERP, mais ne créent pas de chemins de crawl
- Une page sans lien HTML entrant risque de rester invisible ou mal indexée, même si elle est référencée dans un breadcrumb Schema.org
- Le maillage interne reste l'un des rares leviers on-site directement contrôlables et à fort impact sur le SEO
Avis d'un expert SEO
Cette déclaration est-elle cohérente avec les observations terrain ?
Absolument. Les tests de crawl montrent depuis des années que Googlebot suit les liens <a href> en priorité. Les URLs mentionnées dans les structured data (breadcrumb, hreflang, sameAs) ne déclenchent pas de crawl systématique — elles servent de métadonnées, pas de portes d'entrée.
Les sites qui se reposent uniquement sur des breadcrumbs Schema.org pour « lier » leurs pages constatent souvent des problèmes d'indexation ou des pages qui ne remontent jamais dans les SERP. À l'inverse, un maillage HTML dense et logique améliore rapidement la visibilité des pages stratégiques.
Faut-il pour autant négliger les structured data ?
Non — c'est un faux débat. Les structured data et le maillage interne jouent dans deux ligues différentes mais complémentaires. Les breadcrumbs Schema.org améliorent l'affichage dans les SERP (fil d'Ariane cliquable), les annotations hreflang évitent la cannibalisation entre versions linguistiques, et les données de type Article ou Product boostent les taux de clic.
Le piège, c'est de croire qu'en soignant les structured data, on compense un maillage interne bancal. Ça ne marche pas comme ça. Les deux sont nécessaires, mais le maillage HTML reste le socle porteur. Les structured data habillent ce socle, elles ne le remplacent pas.
Dans quels cas cette règle pourrait-elle poser problème ?
Certains sites — notamment les gros e-commerce avec génération dynamique de pages — utilisent des liens JavaScript ou des SPA (Single Page Applications) où les liens ne sont pas toujours des <a href> classiques. Dans ces cas, le rendering JavaScript de Google peut capturer les liens, mais avec un délai et une fiabilité moindres.
Si vos liens internes dépendent de frameworks JS lourds, vous êtes déjà dans une zone grise. Ajouter des structured data ne changera rien au problème de fond : Googlebot préfère toujours les liens HTML statiques, crawlables sans exécution JavaScript.
Impact pratique et recommandations
Que faut-il faire concrètement pour optimiser son maillage interne ?
Première étape : cartographier vos pages stratégiques. Identifiez les contenus à forte valeur (pages piliers, catégories principales, fiches produits best-sellers) et vérifiez qu'ils reçoivent des liens depuis la homepage, le menu principal, et d'autres pages à fort PageRank interne.
Ensuite, auditez la profondeur de clic : une page importante ne devrait jamais être à plus de 3 clics de la homepage. Utilisez Screaming Frog ou Oncrawl pour repérer les pages orphelines ou trop profondes, puis créez des ponts de liens HTML depuis des pages mieux connectées.
Côté structured data, implémentez les breadcrumbs Schema.org pour améliorer l'affichage SERP — mais ne comptez pas sur eux pour le crawl. Assurez-vous que chaque page possède au moins un lien HTML entrant classique, idéalement plusieurs depuis des contextes éditoriaux pertinents.
Quelles erreurs éviter absolument ?
Ne confondez pas annotations sémantiques et architecture de liens. Une page mentionnée dans un breadcrumb JSON-LD mais sans aucun lien <a href> reste une page orpheline pour Google. C'est l'erreur la plus fréquente sur les sites qui migrent vers des architectures trop dépendantes du JavaScript.
Évitez aussi de surcharger vos pages de liens internes inutiles. Un bon maillage, c'est de la qualité contextuelle, pas de la quantité aveugle. Un lien depuis un paragraphe éditorial pertinent vaut mieux que 50 liens footer automatiques vers toutes les catégories du site.
- Auditer la profondeur de clic de toutes les pages stratégiques (objectif : ≤3 clics depuis la homepage)
- Repérer et supprimer les pages orphelines via crawl Screaming Frog ou Search Console
- Créer des liens HTML contextuels depuis les pages piliers vers les sous-pages importantes
- Implémenter les breadcrumbs Schema.org pour améliorer l'affichage SERP (complément, pas remplacement)
- Vérifier que chaque page reçoit au moins 2-3 liens internes depuis des pages bien crawlées
- Éviter les liens générés uniquement en JavaScript sans fallback HTML
- Utiliser des ancres descriptives et variées pour les liens internes (pas du « cliquez ici » en boucle)
Comment vérifier que votre site respecte ces principes ?
Lancez un crawl complet avec un outil type Screaming Frog en mode « Spider ». Analysez le graphe de liens pour identifier les clusters isolés et les pages à faible « InRank » (équivalent interne du PageRank). Croisez avec les données Search Console pour voir si les pages mal liées sont aussi celles qui peinent à être indexées ou positionnées.
Vérifiez aussi que vos structured data (breadcrumb, hreflang) sont bien implémentées et validées via l'outil de test de Google — mais gardez en tête qu'elles viennent après le maillage HTML dans l'ordre des priorités SEO.
❓ Questions frequentes
Les URLs dans les breadcrumbs Schema.org aident-elles au crawl ?
Les annotations hreflang sont-elles suivies comme des liens internes ?
Combien de liens internes minimum par page ?
Les liens JavaScript sont-ils équivalents aux liens HTML pour le SEO ?
Faut-il privilégier le maillage interne ou les structured data ?
🎥 De la même vidéo 21
Autres enseignements SEO extraits de cette même vidéo Google Search Central · publiée le 05/03/2022
🎥 Voir la vidéo complète sur YouTube →
💬 Commentaires (0)
Soyez le premier à commenter.