Declaration officielle
Autres déclarations de cette vidéo 21 ▾
- □ Faut-il créer une nouvelle URL ou mettre à jour la même page pour du contenu quotidien ?
- □ Faut-il arrêter d'utiliser l'outil de soumission manuelle dans Search Console ?
- □ Les balises H2 dans le footer posent-elles un problème pour le référencement ?
- □ Les balises <header> et <footer> HTML5 améliorent-elles vraiment le SEO ?
- □ Faut-il vraiment se fier au validateur schema.org pour optimiser ses données structurées ?
- □ La vitesse de page améliore-t-elle vraiment le classement aussi vite qu'on le croit ?
- □ Google crawle-t-il tous les sitemaps au même rythme ?
- □ Google continue-t-il vraiment de crawler un sitemap supprimé de Search Console ?
- □ Pourquoi Google n'indexe-t-il pas une page crawlée régulièrement si elle ne présente aucun problème technique ?
- □ Peut-on utiliser des canonical bidirectionnels entre deux versions d'un site sans risque ?
- □ Les structured data peuvent-elles remplacer le maillage interne classique ?
- □ Pourquoi un seul x-default suffit-il pour toute votre configuration hreflang multi-domaines ?
- □ Faut-il vraiment éviter le structured data produit sur les pages catégories ?
- □ Faut-il vraiment choisir une langue principale pour chaque page si vous visez plusieurs marchés ?
- □ Pourquoi Google ignore-t-il complètement votre version desktop en mobile-first indexing ?
- □ Le contenu 'commodity' peut-il vraiment survivre dans les résultats Google ?
- □ Faut-il isoler ses FAQ dans des pages séparées pour mieux ranker ?
- □ Pourquoi Google réduit-il drastiquement l'affichage des FAQ dans les résultats de recherche ?
- □ Pourquoi Google n'indexe-t-il qu'une infime fraction de vos URLs ?
- □ Peut-on héberger son sitemap XML sur un domaine différent de son site principal ?
- □ Les Core Web Vitals : pourquoi le passage de « Bad » à « Medium » change tout pour votre ranking ?
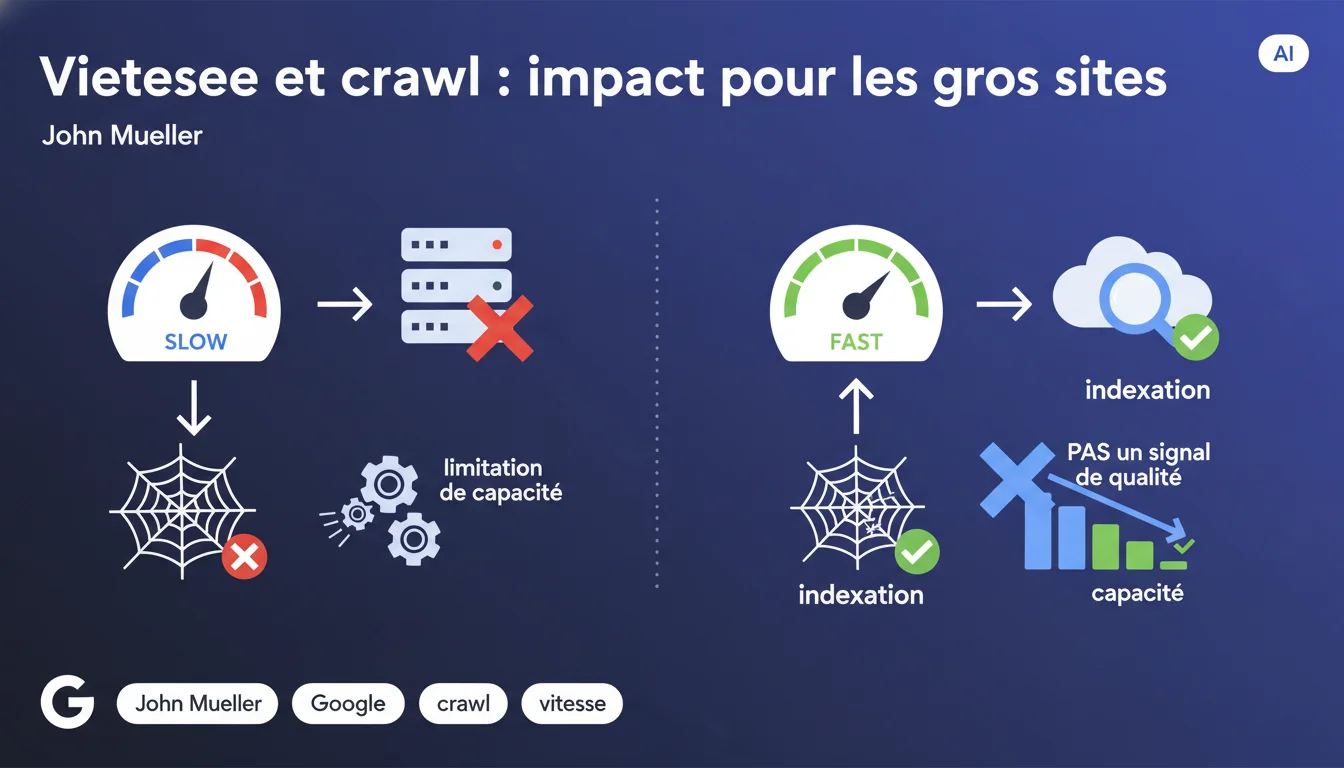
Pour les très grands sites, un serveur lent limite directement la quantité de pages que Google peut crawler, ce qui affecte l'indexation. Google précise que c'est une contrainte technique de capacité, pas un signal de classement négatif. Concrètement : moins de crawl = moins de pages indexées, même si celles indexées ne sont pas pénalisées dans le ranking.
Ce qu'il faut comprendre
Pourquoi Google établit-il cette distinction entre capacité de crawl et signal de qualité ?
La nuance est cruciale. Un serveur qui répond lentement force Googlebot à ralentir son rythme de crawl pour éviter de surcharger l'infrastructure. C'est une limitation mécanique : le bot dispose d'un temps limité par site, et si chaque requête met 2 secondes au lieu de 0,2, il parcourt 10 fois moins de pages.
Cette contrainte n'implique aucun jugement sur la qualité du contenu. Les pages qui parviennent à être crawlées et indexées ne sont pas désavantagées dans les résultats de recherche à cause de la lenteur serveur — leur positionnement dépend d'autres facteurs.
À partir de quelle taille de site cette problématique devient-elle critique ?
Mueller parle de « très grands sites ». Concrètement, cela concerne les plateformes avec plusieurs dizaines de milliers de pages actives : e-commerce de taille significative, agrégateurs de contenu, sites d'annonces, médias volumineux.
Pour un site de quelques centaines ou milliers de pages, même avec un serveur médiocre, Google parvient généralement à tout crawler dans son budget alloué. Le problème se manifeste quand le volume de pages dépasse largement ce que le bot peut parcourir en un cycle normal.
Quelle est la différence concrète entre crawl et indexation dans ce contexte ?
Le crawl est la visite de la page par Googlebot. L'indexation est la décision d'inclure cette page dans l'index après l'avoir analysée. Un serveur lent réduit le nombre de pages visitées, ce qui réduit mécaniquement le nombre de pages candidates à l'indexation.
Si Google ne peut crawler qu'une partie de vos pages critiques, certaines ne seront jamais indexées — non pas parce qu'elles sont de mauvaise qualité, mais simplement parce que le bot ne les a jamais découvertes ou actualisées.
- Vitesse serveur lente = moins de pages crawlées par unité de temps
- Moins de crawl = moins de pages indexables, surtout sur les gros sites
- Cela n'affecte pas le classement des pages effectivement indexées
- C'est une contrainte de capacité technique, pas un signal de qualité
- Le problème se concentre sur les sites de plusieurs dizaines de milliers de pages
Avis d'un expert SEO
Cette déclaration est-elle cohérente avec les observations terrain ?
Oui, et c'est même l'une des rares déclarations de Google qui correspond exactement à ce qu'on observe. Sur les gros catalogues e-commerce ou les sites de petites annonces, un serveur sous-dimensionné crée un goulot d'étranglement visible dans les logs : Googlebot réduit sa fréquence, espacé ses visites, laisse des pans entiers du site non crawlés pendant des semaines.
Les tests sont reproductibles : améliorez le TTFB (Time To First Byte) de 1500ms à 300ms sur un gros site, et vous verrez le nombre de hits Googlebot augmenter significativement sous 2-3 semaines. Pas besoin de croire Google sur parole — les données serveur parlent d'elles-mêmes.
Faut-il vraiment dissocier crawl budget et ranking comme le fait Mueller ?
C'est là que ça devient intéressant. Techniquement, Mueller a raison : la vitesse serveur en elle-même n'est pas un facteur de classement direct. Une page lente à charger côté serveur mais bien optimisée côté contenu peut très bien ranker.
Sauf que. Si votre serveur est si lent que Google ne crawle pas vos nouvelles pages produits, vos articles frais ou vos mises à jour de prix, vous avez un index obsolète. Et un index obsolète, ça impacte indirectement le ranking : fraîcheur du contenu, pertinence des infos, taux de clic sur des pages qui n'existent plus. La frontière entre « capacité » et « qualité » devient floue sur le terrain.
Quelles sont les limites de cette déclaration ?
Mueller ne donne aucun seuil chiffré. À partir de quel TTFB Google ralentit-il ? 500ms ? 1000ms ? 2000ms ? Aucune donnée. [À vérifier] : chaque site semble avoir un traitement différent selon son historique, sa popularité, son type de contenu.
Autre angle mort : il parle de « très grands sites », mais qu'en est-il des sites moyens (10 000-50 000 pages) avec un serveur médiocre ? Sont-ils concernés ou pas ? La communication reste floue sur les seuils d'activation de cette limitation.
Impact pratique et recommandations
Que faut-il faire concrètement pour éviter ce goulot d'étranglement ?
Première étape : mesurez votre TTFB réel tel que Googlebot le perçoit. Pas depuis votre bureau parisien avec fibre, mais depuis les IP de Google, sous charge. Les outils comme Google Search Console (rapport « Statistiques d'exploration ») donnent une indication du temps de réponse moyen perçu par le bot.
Si vous êtes au-dessus de 500ms en moyenne, vous avez probablement une marge d'amélioration. Au-dessus de 1000ms sur un gros site, c'est critique. Identifiez les pages les plus lentes : souvent, ce sont celles avec des requêtes BDD complexes, des calculs dynamiques lourds ou des appels API externes bloquants.
Quelles erreurs éviter dans l'optimisation du crawl sur les gros sites ?
Ne confondez pas vitesse serveur et vitesse de rendu côté client. Vous pouvez avoir un TTFB excellent mais un site qui met 5 secondes à être interactif à cause de JavaScript — ça, c'est un autre problème (Core Web Vitals, UX), pas le sujet du crawl budget.
Autre erreur classique : sur-optimiser le cache sans penser à la fraîcheur. Si vous servez du cache statique parfait mais que vos pages produits en rupture restent crawlées en version « en stock », vous créez un décalage entre index et réalité. Équilibrez performance et actualité.
Comment vérifier que mon site ne subit pas cette limitation ?
Analysez vos logs serveur sur 30 jours. Calculez le ratio pages crawlées / pages indexables. Si Google visite moins de 60-70% de vos pages actives dans le mois, et que votre TTFB est mauvais, vous avez probablement un problème de capacité.
Comparez aussi la fréquence de crawl entre vos sections stratégiques. Si vos nouvelles pages produits mettent 3 semaines à être crawlées alors que des pages zombies sont visitées quotidiennement, votre architecture de liens interne ou votre sitemap XML envoient de mauvais signaux de priorité.
- Mesurez votre TTFB moyen via Google Search Console (rapport Statistiques d'exploration)
- Identifiez les pages lentes avec des outils comme WebPageTest en mode Googlebot
- Optimisez les requêtes base de données : index manquants, jointures complexes, N+1 queries
- Activez un cache serveur intelligent (Varnish, Redis) avec stratégie de purge adaptée
- Dimensionnez votre infrastructure selon le volume réel : serveur dédié, répartition de charge si nécessaire
- Utilisez un CDN pour soulager le serveur origine (Cloudflare, Fastly, AWS CloudFront)
- Surveillez les logs : si le crawl rate stagne ou baisse, diagnostiquez le TTFB immédiatement
- Priorisez les URLs stratégiques via maillage interne et sitemap XML bien structuré
❓ Questions frequentes
Un serveur lent peut-il faire baisser mon classement dans Google ?
À partir de combien de pages un site est-il concerné par cette limitation ?
Quel est le TTFB acceptable pour ne pas freiner le crawl de Google ?
La vitesse de chargement côté client (Core Web Vitals) est-elle concernée ?
Comment savoir si mon site subit cette limitation de crawl ?
🎥 De la même vidéo 21
Autres enseignements SEO extraits de cette même vidéo Google Search Central · publiée le 05/03/2022
🎥 Voir la vidéo complète sur YouTube →
💬 Commentaires (0)
Soyez le premier à commenter.