Official statement
Other statements from this video 21 ▾
- □ Faut-il créer une nouvelle URL ou mettre à jour la même page pour du contenu quotidien ?
- □ Faut-il arrêter d'utiliser l'outil de soumission manuelle dans Search Console ?
- □ Les balises H2 dans le footer posent-elles un problème pour le référencement ?
- □ Les balises <header> et <footer> HTML5 améliorent-elles vraiment le SEO ?
- □ Faut-il vraiment se fier au validateur schema.org pour optimiser ses données structurées ?
- □ La vitesse de page améliore-t-elle vraiment le classement aussi vite qu'on le croit ?
- □ Google crawle-t-il tous les sitemaps au même rythme ?
- □ Google continue-t-il vraiment de crawler un sitemap supprimé de Search Console ?
- □ Pourquoi Google n'indexe-t-il pas une page crawlée régulièrement si elle ne présente aucun problème technique ?
- □ Peut-on utiliser des canonical bidirectionnels entre deux versions d'un site sans risque ?
- □ Les structured data peuvent-elles remplacer le maillage interne classique ?
- □ Pourquoi un seul x-default suffit-il pour toute votre configuration hreflang multi-domaines ?
- □ Faut-il vraiment éviter le structured data produit sur les pages catégories ?
- □ Faut-il vraiment choisir une langue principale pour chaque page si vous visez plusieurs marchés ?
- □ Pourquoi Google ignore-t-il complètement votre version desktop en mobile-first indexing ?
- □ Le contenu 'commodity' peut-il vraiment survivre dans les résultats Google ?
- □ Faut-il isoler ses FAQ dans des pages séparées pour mieux ranker ?
- □ Pourquoi Google réduit-il drastiquement l'affichage des FAQ dans les résultats de recherche ?
- □ Peut-on héberger son sitemap XML sur un domaine différent de son site principal ?
- □ Les Core Web Vitals : pourquoi le passage de « Bad » à « Medium » change tout pour votre ranking ?
- □ La vitesse serveur impacte-t-elle vraiment le crawl budget des gros sites ?
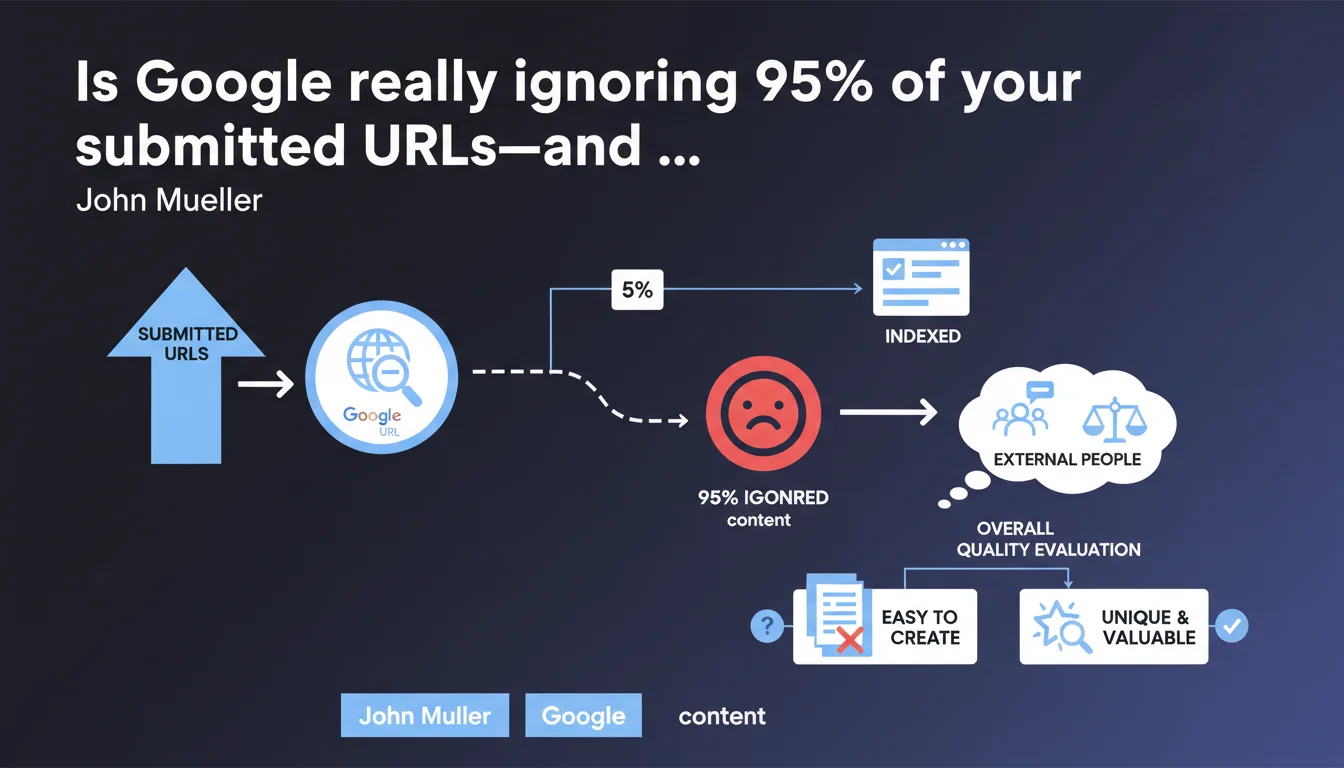
Google is indexing only 86 pages out of 4,500 submitted? The issue probably isn't technical. John Mueller is clear: generating thousands of pages effortlessly doesn't guarantee any unique value for the index. Before chasing technical fixes, assess your site's overall content quality with external, objective reviewers.
What you need to understand
What's really causing catastrophic indexation failure?
An indexation rate of 1.9% (86 URLs out of 4,500) signals massive rejection by Google. The instinctive reaction is to hunt for technical blockers: misconfigured robots.txt, stray noindex tags, tangled canonicals.
But Mueller points elsewhere—toward overall site quality. If Google believes your content adds nothing unique or valuable to its index, it won't waste resources indexing it all. Production volume never compensates for mediocrity.
What does "assess with external, uninvolved people" actually mean?
The team producing the content has an obvious confirmation bias. They'll always justify their choices, process, editorial strategy. That's human nature.
Mueller recommends an objective external audit—someone with no emotional stake in the project. This person must honestly evaluate whether the pages offer something you can't find elsewhere, and whether a real user would find genuine value there.
Why is ease of production a red flag?
"Creating thousands of pages easily"—this phrase directly targets strategies built on automated templates, programmatically generated content, parametric variations with no real differentiation.
If your CMS churns out 10,000 pages in one click because you have a product catalog or geolocated database, Google has zero obligation to index all of it. The question isn't "how many pages" but "what unique value per page."
- Catastrophic indexation rates (<2%) signal a quality issue first, not a technical one
- Audits must be conducted by objective third parties with no connection to content production
- Ease of massive production is a red flag for Google—scalability ≠ value
- Google guarantees no indexation: it's a privilege based on relevance, not a right
SEO Expert opinion
Is this statement aligned with what we actually observe in the field?
Absolutely. We've been seeing for years that Google heavily demotes sites with templated content—product pages without unique descriptions, cloned city pages, landing pages mass-generated with minimal variations.
The catch? Mueller stays vague about exact criteria for uniqueness and value. "Something unique" is operationally meaningless. A specific product attribute? Editorial analysis? A differentiated format? [To verify]—Google never gives quantitative thresholds.
When does this rule not apply as strongly?
High-authority sites get different treatment—it's observable. Amazon indexes millions of low-differentiation product pages. Leboncoin indexes hundreds of thousands of ephemeral classifieds.
So "unique value" is contextual and relative to domain authority. An established e-commerce player can get away with standardized product sheets that a new entrant never could. History, authority, direct traffic matter—even though Google never admits this explicitly.
What critical nuance is missing from this statement?
Mueller doesn't distinguish between "not indexing" and "de-indexing after indexation". If Google indexes then removes pages, that's a different signal—often linked to freshness, internally detected duplication, or algorithmic penalty.
Here we're talking about massive refusal to index initially. This points to filtering at the crawl or discovery stage, not post-indexation evaluation. The problem sits upstream—Google doesn't even judge it worth crawling deeply.
Practical impact and recommendations
What should you actually do facing catastrophic indexation rates?
First, rule out technical issues—but quickly. Check robots.txt, Search Console (coverage, errors), canonicals, redirects. If everything's technically sound, move immediately to a quality audit.
Next, have 20-30 representative pages reviewed by someone external (independent SEO, external senior writer, even a typical user from your audience). Ask: "Does this page offer something you can't find elsewhere?" If the answer is no or hesitant, you've found your diagnosis.
What mistakes should you absolutely avoid?
Don't fall into the "let's add 200 words to every page" trap. Adding text volume without informational value solves nothing—it often makes things worse by diluting signal.
Another classic mistake: thinking semantic optimization (silos, internal linking architecture) will compensate for fundamental weakness. Structure improves crawl distribution and internal PageRank flow, but it won't transform mediocre content into indexable content.
How do you prioritize fixes across thousands of pages?
Segment first by page type (product sheets, categories, articles, location pages, etc.). Identify which type has the worst indexation rate—attack that one first with a sample of 50-100 pages.
Test improvements on that sample: enriched unique content, structured data, original media, UX improvements. Submit via Search Console, wait 4-6 weeks. If indexation improves, scale it up. If not, pivot.
- Complete technical audit (robots.txt, canonicals, redirects, Search Console)
- Quality assessment by external party on representative sample (20-30 pages)
- Page-type segmentation to identify low-indexation categories
- A/B testing on reduced sample before scaling corrections
- Real editorial enrichment—not just padding word counts
- Relevant Schema.org structured data to aid comprehension
- Strategic de-indexation of low-value pages (deliberate noindex)
❓ Frequently Asked Questions
Un taux d'indexation de 2% est-il toujours un problème de qualité ?
Combien de temps faut-il pour corriger un problème d'indexation massif ?
Faut-il désindexer volontairement les pages non indexées par Google ?
L'ajout de contenu généré par IA peut-il résoudre un problème d'unicité ?
Les données structurées aident-elles à améliorer l'indexation ?
🎥 From the same video 21
Other SEO insights extracted from this same Google Search Central video · published on 05/03/2022
🎥 Watch the full video on YouTube →
💬 Comments (0)
Be the first to comment.