Official statement
Other statements from this video 13 ▾
- □ Peut-on gérer plusieurs sites web sans pénalité SEO ?
- □ Tirets vs underscores dans les URLs : quel impact réel sur votre SEO ?
- □ Pourquoi Google ignore-t-il les fragments d'URL avec # en SEO ?
- □ Les erreurs 503 brèves impactent-elles vraiment le crawl de votre site ?
- □ Pourquoi noindex est-il plus efficace que robots.txt pour masquer un site de Google ?
- □ Changer d'hébergeur web impacte-t-il réellement votre référencement naturel ?
- □ Faut-il vraiment limiter l'API d'indexation aux offres d'emploi et événements ?
- □ Faut-il vraiment bannir le texte intégré directement dans les images ?
- □ Les menus burger dupliqués dans le DOM nuisent-ils au référencement ?
- □ Peut-on vraiment cibler plusieurs pays avec une seule page grâce à hreflang ?
- □ Les erreurs 404 externes nuisent-elles vraiment au classement Google ?
- □ Faut-il vraiment un sitemap.xml pour bien ranker sur Google ?
- □ Faut-il vraiment abandonner les URLs mobiles séparées (m-dot) pour le SEO ?
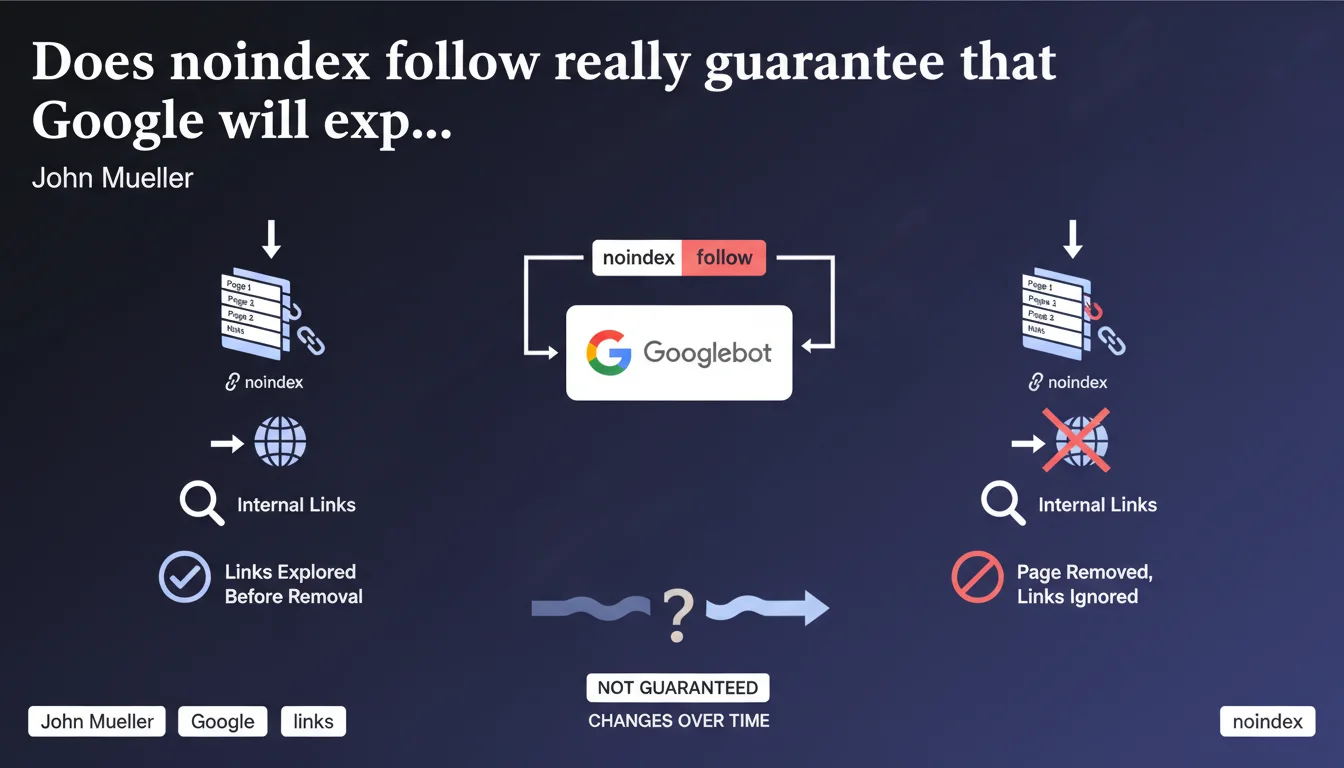
Google does not guarantee that links on a noindex follow page will be explored before the page is removed from the index. Two scenarios are possible: either Googlebot crawls and follows the links before deindexing, or the page disappears without anything being used. This behavior is unpredictable and changes over time.
What you need to understand
What actually happens with a noindex follow tag?
The noindex follow directive sends two contradictory instructions to Google: don't index the page, but follow the links it contains. The idea is to take advantage of internal linking without cluttering the index with low-value pages.
Except — and this is where it gets tricky — Google makes no promises. Either the bot passes through, scans the links and integrates them into the crawl before removing the page, or it removes the page directly without exploiting its content. No guarantees.
Why does this behavior change over time?
Google constantly adjusts its crawl budget and priorities. A pagination page crawled today may be ignored tomorrow if Googlebot decides it brings nothing to the table.
Visit frequency, site authority, content freshness — everything influences this behavior. Result: it's impossible to plan a reliable strategy based on noindex follow to pass juice or guarantee the exploration of entire sections.
In what cases does this uncertainty really cause problems?
Mainly on pagination pages, e-commerce facets, or archives. If you're counting on these pages to help discover deep content through their internal links, you're taking a risk.
Google can very well decide to ignore them completely after a few crawls. You then lose PageRank transmission and the exploration of your strategic URLs nested within these pages.
- Noindex follow is not a guarantee that links will be explored before deindexing
- Google's behavior varies depending on crawl budget and site authority
- Pagination pages and facets are particularly affected
- No predictability: what works today can fail tomorrow
SEO Expert opinion
Does this statement align with real-world observations?
Yes, completely. We regularly see sites where noindex follow pages pass no juice — their links are never crawled. Other times it works for months, then nothing.
What Mueller doesn't say is which signals trigger one scenario or the other. Low crawl budget? Page depth? Domain authority? [To verify] — Google remains vague about the exact criteria.
Should you ban noindex follow altogether?
No, but you need to stop believing it's a miracle solution. If your goal is to pass PageRank or guarantee the exploration of strategic links, go with indexed pages that have unique content.
Noindex follow remains useful for edge cases: technical pages, test zones, temporary redirects. But relying on it to structure your internal linking across thousands of pages? Too risky.
What concrete alternative if noindex follow doesn't deliver on its promises?
Either you index these pages with unique content (intro text, filter explanations, added value), or you use the canonical tag to consolidate variants toward one main page. Or you remove these pages from crawl entirely with a disallow if they have no SEO value.
But let's be honest: every site has its own architecture, and there's no magic recipe. What works for an e-commerce with 50,000 URLs doesn't apply to a niche blog.
Practical impact and recommendations
What should you do if you currently use noindex follow on pagination?
First step: audit the crawl of these pages in Search Console. Check if Google visits them regularly and whether the links they contain are actually explored.
If you notice that certain strategic URLs are never discovered despite being present on these pages, it's a sign that Google is ignoring them. You then need to rethink your strategy.
What mistakes should you absolutely avoid?
Don't rely on noindex follow to distribute PageRank to important pages. If a page has SEO value, index it properly with unique content.
Also avoid mixing noindex follow with other contradictory directives (canonical, disallow). Google might ignore everything as a precaution.
- Verify in Search Console whether your noindex follow pages are crawled regularly
- Check if the internal links of these pages appear in coverage reports
- Replace noindex follow with indexed pages that have unique content if they serve a strategic function
- Use the canonical tag to consolidate variants rather than multiplying noindex directives
- Audit your architecture: if deep URLs are never crawled, it's a structural problem
How do you ensure your architecture stands the test of time?
A comprehensive technical audit is essential: analysis of crawl budget, site structure, internal linking, facet management. Then you need to monitor continuously — what works today can break down tomorrow.
In practice, many sites end up with complex crawlability issues tied to hybrid architecture spanning pagination, facets, and filters. Diagnosing bottlenecks, balancing indexation and PageRank distribution, while optimizing crawl budget: that takes real expertise.
❓ Frequently Asked Questions
Le noindex follow transmet-il du PageRank vers les pages liées ?
Dois-je retirer toutes mes pages de pagination en noindex follow ?
Quelle alternative au noindex follow pour gérer des facettes e-commerce ?
Comment vérifier si Google explore les liens d'une page en noindex follow ?
Ce comportement imprévisible est-il lié au budget de crawl ?
🎥 From the same video 13
Other SEO insights extracted from this same Google Search Central video · published on 18/04/2024
🎥 Watch the full video on YouTube →
💬 Comments (0)
Be the first to comment.