Declaration officielle
Autres déclarations de cette vidéo 13 ▾
- □ Peut-on gérer plusieurs sites web sans pénalité SEO ?
- □ Tirets vs underscores dans les URLs : quel impact réel sur votre SEO ?
- □ Pourquoi Google ignore-t-il les fragments d'URL avec # en SEO ?
- □ Les erreurs 503 brèves impactent-elles vraiment le crawl de votre site ?
- □ Pourquoi noindex est-il plus efficace que robots.txt pour masquer un site de Google ?
- □ Changer d'hébergeur web impacte-t-il réellement votre référencement naturel ?
- □ Faut-il vraiment limiter l'API d'indexation aux offres d'emploi et événements ?
- □ Faut-il vraiment bannir le texte intégré directement dans les images ?
- □ Les menus burger dupliqués dans le DOM nuisent-ils au référencement ?
- □ Peut-on vraiment cibler plusieurs pays avec une seule page grâce à hreflang ?
- □ Les erreurs 404 externes nuisent-elles vraiment au classement Google ?
- □ Faut-il vraiment un sitemap.xml pour bien ranker sur Google ?
- □ Faut-il vraiment abandonner les URLs mobiles séparées (m-dot) pour le SEO ?
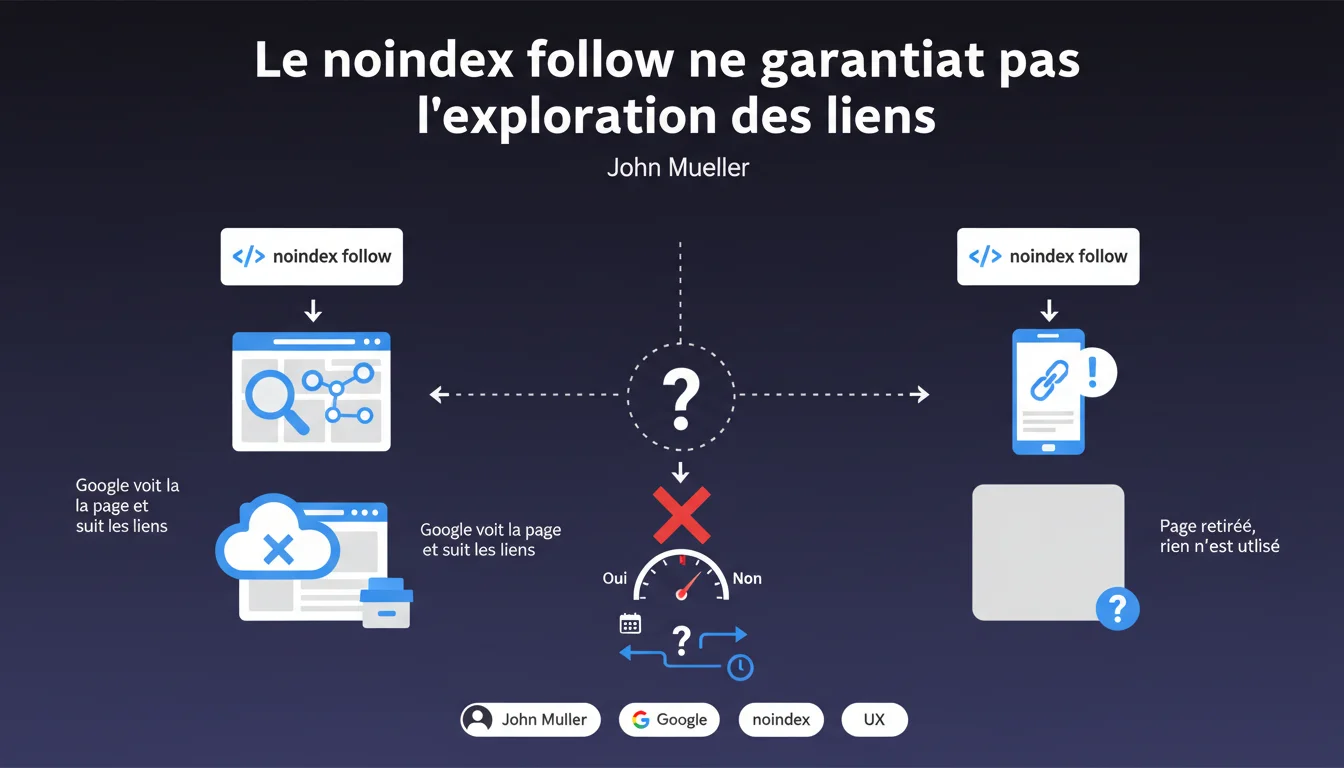
Google ne garantit pas que les liens d'une page en noindex follow seront explorés avant son retrait de l'index. Deux scénarios : soit Googlebot crawle et suit les liens avant déindexation, soit la page disparaît sans que rien ne soit exploité. Ce comportement est imprévisible et évolue dans le temps.
Ce qu'il faut comprendre
Que se passe-t-il concrètement avec une balise noindex follow ?
La directive noindex follow envoie deux instructions contradictoires à Google : ne pas indexer la page, mais suivre les liens qu'elle contient. L'idée, c'est de profiter du maillage interne sans polluer l'index avec des pages de faible valeur.
Sauf que — et c'est là que ça coince — Google ne s'engage sur rien. Soit le robot passe, scanne les liens et les intègre au crawl avant de retirer la page, soit il retire la page directement sans exploiter son contenu. Aucune garantie.
Pourquoi ce comportement change-t-il au fil du temps ?
Google ajuste en permanence son budget de crawl et ses priorités. Une page de pagination aujourd'hui crawlée peut être ignorée demain si Googlebot décide qu'elle n'apporte rien.
La fréquence de visite, l'autorité du site, la fraîcheur du contenu : tout influence ce comportement. Résultat : impossible de planifier une stratégie fiable sur du noindex follow pour transmettre du jus ou garantir l'exploration de sections entières.
Dans quels cas ce flou pose-t-il vraiment problème ?
Principalement sur les pages de pagination, les facettes e-commerce, ou les archives. Si tu comptes sur ces pages pour faire découvrir du contenu profond via leurs liens internes, tu prends un risque.
Google peut très bien décider de les ignorer totalement après quelques passages. Tu perds alors la transmission de PageRank et l'exploration de tes URLs stratégiques nichées dans ces pages.
- Noindex follow n'est pas une garantie d'exploration des liens avant déindexation
- Le comportement de Google varie selon le budget de crawl et l'autorité du site
- Les pages de pagination et facettes sont particulièrement concernées
- Aucune prévisibilité : ce qui fonctionne aujourd'hui peut échouer demain
Avis d'un expert SEO
Cette déclaration colle-t-elle avec les observations terrain ?
Oui, totalement. On voit régulièrement des sites où les pages en noindex follow ne transmettent aucun jus — leurs liens ne sont jamais crawlés. D'autres fois, ça fonctionne pendant des mois, puis plus rien.
Ce que Mueller ne dit pas, c'est quels signaux déclenchent l'un ou l'autre scénario. Budget de crawl faible ? Profondeur des pages ? Autorité du domaine ? [A vérifier] — Google reste vague sur les critères précis.
Faut-il pour autant bannir le noindex follow ?
Non, mais il faut arrêter de croire que c'est une solution miracle. Si ton objectif est de transmettre du PageRank ou garantir l'exploration de liens stratégiques, passe par des pages indexées avec du contenu unique.
Le noindex follow reste utile pour des cas marginaux : pages techniques, zones de test, redirections temporaires. Mais compter dessus pour structurer ton maillage interne sur des milliers de pages ? Trop risqué.
Quelle alternative concrète si noindex follow ne tient pas ses promesses ?
Soit tu indexes ces pages avec du contenu unique (texte intro, filtres expliqués, valeur ajoutée), soit tu utilises la balise canonical pour regrouper les variantes vers une page principale. Ou encore, tu retires carrément ces pages du crawl avec un disallow si elles n'ont aucune utilité SEO.
Mais soyons honnêtes : chaque site a sa propre architecture, et il n'y a pas de recette magique. Ce qui marche pour un e-commerce à 50 000 URLs ne s'applique pas à un blog de niche.
Impact pratique et recommandations
Que faire si tu utilises actuellement noindex follow sur de la pagination ?
Première étape : auditer le crawl de ces pages dans la Search Console. Regarde si Google les visite régulièrement et si les liens qu'elles contiennent sont effectivement explorés.
Si tu constates que certaines URLs stratégiques ne sont jamais découvertes malgré leur présence sur ces pages, c'est le signe que Google les ignore. Il faut alors revoir ta stratégie.
Quelles erreurs éviter absolument ?
Ne pas compter sur noindex follow pour distribuer du PageRank vers des pages importantes. Si une page a de la valeur SEO, indexe-la proprement avec du contenu unique.
Évite aussi de mélanger noindex follow avec d'autres directives contradictoires (canonical, disallow). Google risque de tout ignorer par précaution.
- Vérifie dans la Search Console si tes pages en noindex follow sont crawlées régulièrement
- Contrôle si les liens internes de ces pages apparaissent dans les rapports de couverture
- Remplace le noindex follow par des pages indexées avec contenu unique si elles ont une fonction stratégique
- Utilise la balise canonical pour regrouper les variantes plutôt que de multiplier les noindex
- Audite ton architecture : si des URLs profondes ne sont jamais crawlées, c'est un problème de structure
Comment s'assurer que ton architecture tient la route sur le long terme ?
Un audit technique complet s'impose : analyse du budget de crawl, arborescence, maillage interne, gestion des facettes. Ensuite, il faut monitorer en continu — ce qui fonctionne aujourd'hui peut dérailler demain.
Concretement, beaucoup de sites se retrouvent avec des problématiques d'exploration complexes liées à une architecture hybride pagination/facettes/filtres. Diagnostiquer les goulets d'étranglement, équilibrer l'indexation et la transmission de PageRank, tout en optimisant le budget de crawl : ça demande une expertise pointue.
❓ Questions frequentes
Le noindex follow transmet-il du PageRank vers les pages liées ?
Dois-je retirer toutes mes pages de pagination en noindex follow ?
Quelle alternative au noindex follow pour gérer des facettes e-commerce ?
Comment vérifier si Google explore les liens d'une page en noindex follow ?
Ce comportement imprévisible est-il lié au budget de crawl ?
🎥 De la même vidéo 13
Autres enseignements SEO extraits de cette même vidéo Google Search Central · publiée le 18/04/2024
🎥 Voir la vidéo complète sur YouTube →
💬 Commentaires (0)
Soyez le premier à commenter.