Declaration officielle
Autres déclarations de cette vidéo 13 ▾
- □ Peut-on gérer plusieurs sites web sans pénalité SEO ?
- □ Tirets vs underscores dans les URLs : quel impact réel sur votre SEO ?
- □ Le noindex follow garantit-il vraiment l'exploration des liens par Google ?
- □ Pourquoi Google ignore-t-il les fragments d'URL avec # en SEO ?
- □ Les erreurs 503 brèves impactent-elles vraiment le crawl de votre site ?
- □ Changer d'hébergeur web impacte-t-il réellement votre référencement naturel ?
- □ Faut-il vraiment limiter l'API d'indexation aux offres d'emploi et événements ?
- □ Faut-il vraiment bannir le texte intégré directement dans les images ?
- □ Les menus burger dupliqués dans le DOM nuisent-ils au référencement ?
- □ Peut-on vraiment cibler plusieurs pays avec une seule page grâce à hreflang ?
- □ Les erreurs 404 externes nuisent-elles vraiment au classement Google ?
- □ Faut-il vraiment un sitemap.xml pour bien ranker sur Google ?
- □ Faut-il vraiment abandonner les URLs mobiles séparées (m-dot) pour le SEO ?
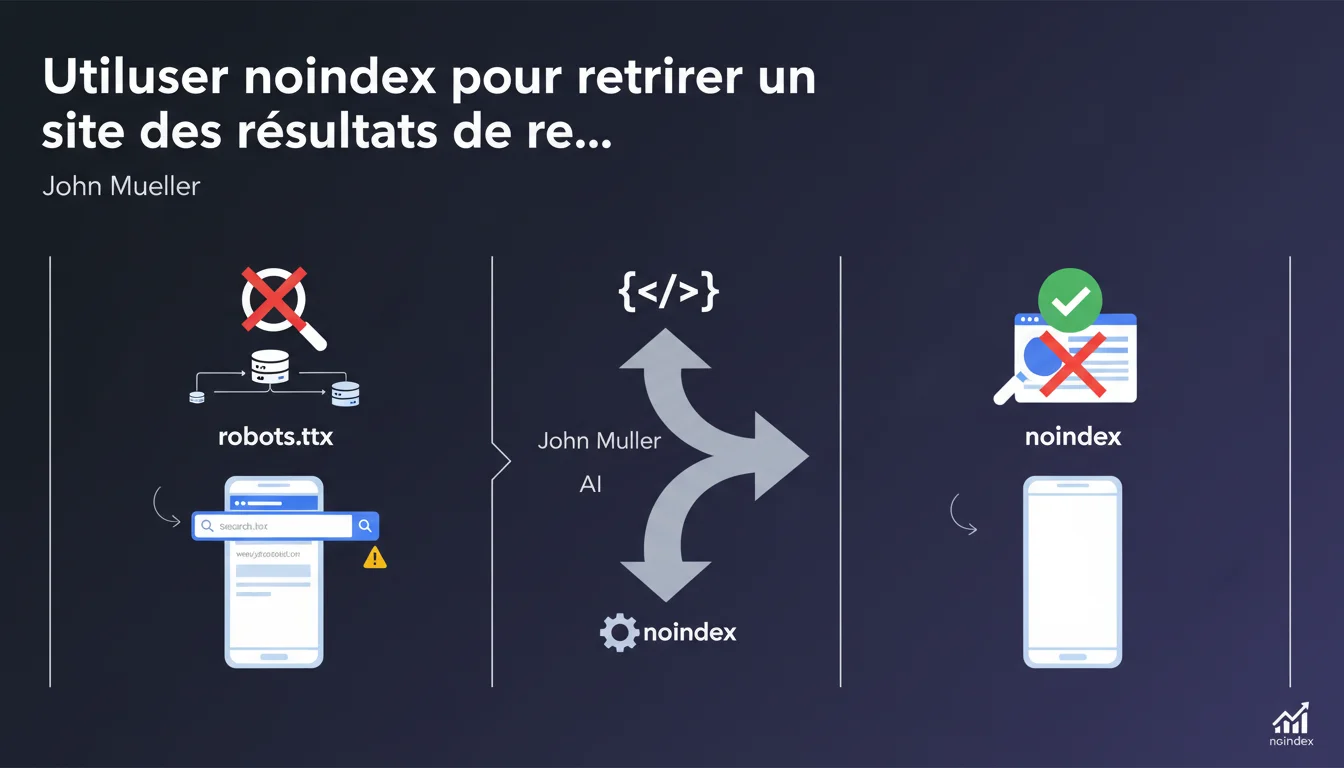
Google recommande d'utiliser la balise meta robots noindex plutôt que robots.txt pour retirer un site des résultats de recherche tout en le gardant accessible. Avec robots.txt, le site peut toujours apparaître si quelqu'un le cherche par son nom exact, car Google peut indexer l'URL sans crawler le contenu.
Ce qu'il faut comprendre
Quelle est la différence fondamentale entre robots.txt et noindex ?
Le robots.txt bloque le crawl des pages par les robots d'indexation. Concrètement, Google ne peut pas accéder au contenu de la page, mais peut quand même indexer l'URL si elle est mentionnée ailleurs sur le web (backlinks, réseaux sociaux, etc.).
La balise meta robots noindex fonctionne différemment : elle permet à Googlebot de crawler la page, d'accéder au contenu, mais lui ordonne explicitement de ne pas l'indexer. C'est une instruction directe au moteur de recherche.
Pourquoi un site bloqué par robots.txt peut-il quand même apparaître dans les SERP ?
Paradoxalement, bloquer une page via robots.txt peut créer une entrée fantôme dans l'index. Si des sites externes pointent vers cette URL, Google la connaît et peut l'afficher avec la mention « Aucune information disponible pour cette page ».
C'est particulièrement problématique quand quelqu'un recherche votre marque par son nom exact. L'URL peut ressortir même si le contenu n'est pas crawlé — exactement ce que Mueller pointe ici.
Dans quels cas cette distinction est-elle critique ?
Pour les sites en staging, les pages de développement ou les sections privées d'un site accessible publiquement, la nuance est capitale. Un robots.txt ne garantit pas l'invisibilité totale.
Un autre cas classique : les sites en refonte temporairement mis en ligne sur un domaine définitif mais qu'on ne veut pas voir indexés avant le lancement officiel. Noindex est la seule protection fiable.
- robots.txt bloque le crawl, mais n'empêche pas l'indexation des URLs connues ailleurs
- meta robots noindex empêche l'indexation, même si la page est crawlée
- La recherche par nom de marque exact peut révéler des URLs bloquées par robots.txt
- Pour un masquage total des résultats de recherche, noindex est la seule méthode garantie
- Les deux directives peuvent coexister, mais avec des objectifs différents
Avis d'un expert SEO
Cette déclaration est-elle cohérente avec les observations terrain ?
Absolument. J'ai observé des dizaines de cas où des environnements de staging protégés uniquement par robots.txt sont apparus dans Google lors de recherches par nom de domaine exact. Le phénomène est reproductible.
La confusion vient du fait que robots.txt est souvent présenté comme une méthode de « blocage », alors qu'il ne bloque que l'accès au contenu, pas la connaissance de l'existence de l'URL. C'est une nuance technique que beaucoup de praticiens négligent.
Quelles situations échappent à cette règle ?
Si un site est totalement isolé — aucun backlink externe, aucune mention publique, jamais soumis dans Search Console — et protégé par robots.txt, il y a une chance qu'il ne soit jamais découvert par Google. Mais c'est un pari risqué.
Autre cas : les sites avec authentification HTTP (mot de passe serveur). Là, Google ne peut même pas accéder à la page pour lire un éventuel noindex. Mais dès que l'authentification est levée, on retombe sur le besoin de noindex.
[À vérifier] : Mueller ne précise pas combien de temps prend la désindexation effective après ajout d'un noindex. Sur des sites à faible crawl, ça peut prendre des semaines. Le délai exact dépend de multiples facteurs que Google ne documente pas clairement.
Le risque de combiner robots.txt et noindex
Attention au piège classique : si vous bloquez une page par robots.txt ET que vous ajoutez un noindex dans le code, Google ne pourra jamais lire le noindex puisqu'il ne crawle pas la page. L'URL peut donc rester indéfiniment dans l'index.
La séquence correcte pour désindexer une page déjà indexée et bloquée par robots.txt : d'abord autoriser le crawl, ajouter le noindex, attendre la désindexation, puis éventuellement rebloquer par robots.txt si nécessaire.
Impact pratique et recommandations
Que faut-il faire concrètement pour masquer un site des SERP ?
Ajoutez la balise <meta name="robots" content="noindex, nofollow"> dans le <head> de toutes les pages concernées. C'est la directive la plus explicite et universelle.
Alternativement, vous pouvez utiliser un header HTTP X-Robots-Tag: noindex — particulièrement utile pour les fichiers non-HTML (PDF, images) ou les sites avec un contrôle limité sur le code front-end.
Dans les deux cas, assurez-vous que le robots.txt n'empêche pas le crawl de ces pages, sinon Google ne verra jamais la directive noindex.
Comment vérifier que la désindexation fonctionne ?
Utilisez la commande site:votredomaine.com dans Google pour vérifier les pages indexées. Si des URLs persistent malgré le noindex, vérifiez qu'elles sont bien crawlables.
Dans Google Search Console, la section « Couverture » vous indique les pages « Exclues par la balise noindex ». C'est la confirmation que Google a bien lu et respecté la directive.
Le délai de désindexation varie selon la fréquence de crawl du site. Pour accélérer le processus, soumettez les URLs concernées via l'outil d'inspection d'URL dans Search Console.
Quelles erreurs éviter absolument ?
Ne combinez jamais robots.txt Disallow et meta noindex sur les mêmes URLs. C'est la configuration la plus contre-productive : Google ne peut pas lire le noindex et l'URL reste indexable.
Évitez également le noindex via JavaScript uniquement si vous n'êtes pas certain que Google exécute correctement le JS sur votre site. Privilégiez toujours une implémentation côté serveur ou dans le HTML brut.
- Ajouter
meta robots noindexdans le<head>de chaque page à masquer - Vérifier que robots.txt autorise le crawl de ces pages
- Contrôler dans Search Console que les pages sont « Exclues par la balise noindex »
- Utiliser
site:domaine.compour surveiller les pages encore indexées - Soumettre les URLs via l'outil d'inspection pour accélérer la désindexation
- Ne jamais combiner Disallow robots.txt et meta noindex sur les mêmes URLs
- Préférer une implémentation serveur (header HTTP) ou HTML brut au JS pour le noindex
❓ Questions frequentes
Puis-je utiliser robots.txt pour désindexer une page déjà présente dans Google ?
Le noindex empêche-t-il le transfert de PageRank via les liens sortants ?
Combien de temps faut-il pour qu'une page avec noindex disparaisse de l'index ?
Un header HTTP X-Robots-Tag noindex est-il aussi efficace qu'une meta balise ?
Si je protège mon site par mot de passe HTTP, ai-je quand même besoin de noindex ?
🎥 De la même vidéo 13
Autres enseignements SEO extraits de cette même vidéo Google Search Central · publiée le 18/04/2024
🎥 Voir la vidéo complète sur YouTube →
💬 Commentaires (0)
Soyez le premier à commenter.